Android一些问题
1.wait()与sleep()
wait()方法会释放占有的对象锁,当前线程进入等待池,释放cpu, 而其他正在等待的线程即可抢占此锁,获得锁的线程即可运行程序;
sleep()方法则表示,当前线程会休眠一段时间,休眠期间,会暂时释放cpu,但并不释放对象锁,也就是说,在休眠期间,其他线程依然无法进入被同步保护的代码内部,当前线程休眠结束时,会重新获得cpu执行权,从而执行被同步保护的代码。
wait()和sleep()最大的不同在于wait()会释放对象锁,而sleep()不会释放对象锁。
2.实现线程安全的三种方式
同步方法
同步代码块
Lock锁机制, 通过创建Lock对象,采用lock()加锁,unlock()解锁,来保护指定的代码块
3.指定线程执行顺序
a.通过join方法:
t1.start() ;
t1.join();
t2.start() ;
t2.join();
t3.start() ;
b.通过单个线程的线程池
Executors executors = Executors.newSingleThreadExecutor();
executors.submit(t1);
executors.submit(t2);
executors.submit(t3);
c.通过共享对象锁加上可见变量来实现。
共享对象锁,可以保证每个方法只能同时有一个线程进入,配合wait和notifyall方法,可以启动或者唤醒线程。
4. java中thread的start和run的区别
1) start:
用start方法来启动线程,真正实现了多线程运行,这时无需等待run方法体代码执行完毕而直接继续执行下面的代码。通过调用Thread类的start()方法来启动一个线程,这时此线程处于就绪(可运行)状态,并没有运行,一旦得到cpu时间片,就开始执行run()方法,这里方法 run()称为线程体,它包含了要执行的这个线程的内容,Run方法运行结束,此线程随即终止。
2) run:
run()方法只是类的一个普通方法而已,如果直接调用Run方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码,这样就没有达到写线程的目的。
总结:调用start方法方可启动子线程,而run方法只是thread的一个普通方法调用,还是在主线程里执行。这两个方法应该都比较熟悉,把需要并行处理的代码放在run()方法中,start()方法启动线程将通过底层自动调用 run()方法,这是由jvm的内存机制规定的, 并且run()方法必须是public访问权限,返回值类型为void。
5、HashMap与Hashtable的区别
HashMap与Hashtable都完成了Map接口,主要区别在于HashMap准许空(Null)键值(key-value)而Hashtable不允许,HashMap线程不安全效率高,Hashtable线程安全效率低。
总结:
|
HashMap |
线程不安全 |
允许有null的键和值 |
效率高 |
方法不是Synchronize的, 要提供外同步 |
有containsvalue和containsKey方法 |
HashMap 是Java1.2 引进的Map interface 的一个实现 |
HashMap是Hashtable的轻量级实现 |
|
Hashtable |
线程安全 |
不允许有null的键和值 |
效率低 |
方法是是Synchronize的 |
有contains方法 |
Hashtable 继承于Dictionary 类 |
Hashtable 比HashMap 要旧
|
6、内部类可以引用他包含类的成员吗?有没有什么限制?
一个内部类对象可以访问创建它的外部类对象的内容。
可以: 如果不是静态内部类,那没有什么限制!如果是静态内部类,那在这种情况下不可以访问外部类的普通成员变量,而只能访问外部类中的静态成员
7.Binder优势
- Binder基于C/S架构的,架构清晰明朗,Server端与Client端相对独立,稳定性较好;Socket虽然也是C/S架构,但传输效率低并且不够安全。而共享内存实现方式复杂,没有客户与服务端之别, 需要充分考虑到访问临界资源的并发同步问题,否则可能会出现死锁等问题。
- 有更好的传输性能。对比于Linux的通信机制,
- socket:是一个通用接口,导致其传输效率低,开销大,主要用于不同机器或跨网络的通信;
- 管道和消息队列:因为采用存储转发方式,所以至少需要拷贝2次数据,效率低;
- 共享内存:虽然在传输时没有拷贝数据,但其控制机制复杂(比如跨进程通信时,需获取对方进程的pid,得多种机制协同操作)。
- 安全性更高。Linux的IPC机制在本身的实现中,并没有安全措施,得依赖上层协议来进行安全控制。而Binder机制的UID/PID是由Binder机制本身在内核空间添加身份标识,安全性高;并且Binder可以建立私有通道,这是linux的通信机制所无法实现的(Linux访问的接入点是开放的)。
8.SurfaceView
它拥有独立的绘图表面,即它不与其宿主窗口共享同一个绘图表面,由于拥有独立的绘图表面,因此SurfaceView的UI就可以在一个独立的线程中进行行绘制,由于不占用主线程资源,SurfaceView一方面可以实现复杂而高效的UI。
SurfaceView里面镶嵌的Surface是在包含SurfaceView的宿主Activity窗口(顶层视图对应的Surface)后面,用来描述SurfaceView的Layer的Z轴位置是小于用来描述其宿主Activity窗口的Layer的Z轴位置的,这样SurfaceView的Layer就被挡住看不见了,SurfaceView提供了一个可见区域,只有在这个可见区域内的surface部分内容才可见,就好像SurfaceView会在宿主Activity窗口上面挖一个“洞”出来,以便它的UI可以漏出来对用户可见,实际上,SurfaceView只不过是在其宿主Activity窗口上设置了一块透明区域.

SurfaceView的双缓冲机制:即对于每一个SurfaceView对象而言,有两个独立的graphic buffer。在Android SurfaceView的双缓冲机制中是这样实现的:
在Buffer A中绘制内容,然后让屏幕显示Buffer A;在下一个循环中,在Buffer B中绘制内容,然后让屏幕显示Buffer B,如此往复。而由于这个双缓冲机制的存在,可能会引起闪屏现象,。在第一个"lockCanvas-drawCanvas-unlockCanvasAndPost "循环中,更新的是buffer A的内容;到下一个"lockCanvas-drawCanvas-unlockCanvasAndPost"循环中,更新的是buffer B的内容。 如果buffer A与buffer B中某个buffer内容为空,当屏幕轮流显示它们时,就会出现画面黑屏闪烁现象。
解决方法
出现黑屏是因为buffer A与buffer B中一者内容为空,而且为空的一方还被post到了屏幕。于是有两种解决思路:
1.不让空buffer出现:每次向一个buffer写完内容并post之后,顺便用这个buffer的内容填充另一个buffer。这样能保证两个 buffer的内容是同步的,缺点是做了无用功,耗费性能。
2.不post空buffer到屏幕:当准备更新内容时,先判断内容是否为空,只有非空时才启动"lockCanvas-drawCanvas-unlockCanvasAndPost"这个流程。(上述模板和示例中即采用了这个方法)
SurfaceView和View的不同之处:
|
View |
SurfaceView |
|
适用于主动更新 |
适用于被动刷新 |
|
在主线程中进行画面更新 |
通常通过一个子线程来进行画面更新 |
|
绘图中没有使用双缓冲机制 |
在底层实现中就实现了双缓冲机制
|
tips:SurfaceView和View一大不同就是SurfaceView是被动刷新的,但我们可以控制刷新的帧率,而View并且通过invalidate方法通知系统来主动刷新界面的,但是View的刷新是依赖于系统的VSYSC信号的,其帧率并不受控制,而且因为UI线程中的其他一些操作会导致掉帧卡顿。而对于SurfaceView而言,它是在子线程中绘制图形,根据这一特性即可控制其显示帧率,通过简单地设置休眠时间即可,并且由于在子线程中,一般不会引起UI卡顿。
Thread.sleep(50);即可以控制1s内刷新20次
9.TCP和UDP的区别?
- 技术点:传输层协议对比
- 参考回答:
- TCP传输控制协议:面向连接;使用全双工的可靠信道;提供可靠的服务,即无差错、不丢失、不重复且按序到达;拥塞控制、流量控制、超时重发、丢弃重复数据等等可靠性检测手段;面向字节流;每条TCP连接只能是点到点的;用于传输可靠性要求高的数据
- UDP用户数据报协议:无连接;使用不可靠信道;尽最大努力交付,即不保证可靠交付;无拥塞控制等;面向报文;支持一对一、一对多、多对一和多对多的交互通信;用于传输可靠性要求不高的数据
10. JVM堆和栈的区别
- 程序在栈内存中运行
- 栈中存的是基本数据类型和堆中对象的引用
- 栈是运行时的单元
- 栈解决程序的运行问题,即程序如何执行,或者说如何处理数据
- 一个线程一个独立的线程栈
- 程序运行所需的大部分数据保存在栈内存中
- 堆中存的是对象
- 堆是存储的单元,堆只是一块共享的内存
- 堆解决的是数据存储的问题,即数据怎么放,放在哪儿
- 所有线程共享堆内存
11.WebViewClient 与 WebChromeClient
WebViewClient帮助WebView处理各种通知和请求事件的,我们可以称他为WebView的“内政大臣”。常用的shouldOverrideUrlLoading就是该类的一个方法,比如:
| onLoadResource |
| onPageStart |
| onPageFinish |
| onReceiveError |
| onReceivedHttpAuthRequest |
WebChromeClient主要辅助WebView处理Javascript的对话框、网站图标、网站标题、加载进度等偏外部事件的“外交大臣”。比如:
| onCloseWindow(关闭WebView) |
| onCreateWindow() |
| onJsAlert (WebView上alert无效,需要定制WebChromeClient处理弹出) |
| onJsPrompt |
| onJsConfirm |
| onProgressChanged |
| onReceivedIcon |
| onReceivedTitle |
看上去他们有很多不同,实际使用的话,如果你的WebView只是用来处理一些html的页面内容,只用WebViewClient就行了,如果需要更丰富的处理效果,比如JS、进度条等,就要用到WebChromeClient。
12.Fragment和View的比较
Fragment和View都有助于界面组件的复用,这在大型工程里边是特别重要的,但是二者又有所区别。
1、Fragment的复用粒度更大。Fragment有完整的生命周期,从代码设计角度讲可以提高内聚性,不同情况下还可以设计不同的Fragment,比如横屏和竖屏情况下View的显示不一样,那么可以建立2个不同的Fragment去处理,代码上面可以有效的扩展。从形态上讲和Activity更为接近,当然从编程角度上看也比View更为复杂。但是Fragment可以组装更多的View同一展示,而且生命周期有助于资源的管理。
2、简单的直接view,复杂的才用fragment,fragment资源消耗比较大。
3、一个fragment必须总是绑定到一个activity中,虽然fragment有自己的生命周期,但同时也被它的宿主activity的生命周期直接影响。
大部分情况下,Fragment用来封转UI的模块化组件;但是也可以创建没有UI的Fragment来提供后台行为,该行为会一直持续到Activity重新启动。这特别适合于定期和UI交互的后台任务或者当因配置改变而导致Activity重新启动是,保存状态变得特别重要的场合。
注意:当Activity因为配置发生改变(屏幕旋转)或者内存不足被系统杀死,造成重新创建时,我们的fragment会被保存下来,但是会创建新的FragmentManager,新的FragmentManager会首先会去获取保存下来的fragment队列,重建fragment队列,从而恢复之前的状态。
首先简单的介绍下两个库的出身:
Picasso是Square公司出品的一款非常优秀的开源图片加载库
Glide是由Google开发,基于 Picasso,依然有保存了Picasso的简洁风格,但是在此做了大量优化与改进。
具体的使用方法这里就不详细介绍了,这里重点说区别,主要体现在下面几个方面:
1. 库的大小和方法的数量
Glide 要比 Picasso 大很多,基本上是 Picasso 的3.5倍
2. 缓存方式
Glide 默认的 Bitmap 格式是 RGB_565 格式,而Picasso默认的是 ARGB_8888 格式,这个内存开销要小一半。
在磁盘缓存方面,Picasso只会缓存原始尺寸的图片,而 Glide 缓存的是多种规格,也就意味着 Glide会根据你ImageView的大小来缓存相应大小的图片尺寸,比如你ImageView大小是200*200,原图是 400*400,而使用Glide 就会缓存 200*200规格的图,而Picasso只会缓存 400*400 规格的。这个改进就会导致 Glide 比 Picasso 加载的速度要快
3. 加载图片速度
当内存中不存在时,Picasso会比Glide快一点,可能的原因是缓存机制导致,因为Picasso是直接把图加载到内存中,而Glid 则需要改变图片大小再加载到内存中去,这个应该是会耗费一定的时间。
但是,当加载的图片在内存中时,Glide 则比 Picasso 要快。其原理还是因为缓存机制的区别,因为Picasso 从内存中拿到的图片,还要先去 resize 后,然后设定给 imageView,但是 Glide 则不需要这样。
4. 生命周期
Glide 相比 Picasso 的一大优势是它可以和 Activity 以及 Fragment 的生命周期相互协作,我们在调用 Glide.with() 函数时可以将 Activity 或者 Fragment 的实例传进去,这样 Glide 就会自动将图片加载等操作和组件的生命周期关联起来。
5. Glide可以加载视频缩略图
6. Glide 支持 GIF动态图
14. Inent传递数据大小限制
Intent在传递数据时是有大小限制的,一般被限制在1MB之内(1024KB)。
所以在通过bundle传递数据时只能传递较小的数据信息,对于在不同组件之间需要传递大容量数据的情况时,有几种替代方式可以解决不能用bundle传递这些数据的问题:
方法一:不同进程,可以将需要传递的数据写在临时文件或者数据库中,再跳转到另外一个组件的时候再去读取这些数据信息,这种处理方式会由于读写文件较为耗时导致程序运行效率较低;
方法二:同一个进程,可以将需要传递的数据信息封装在一个静态的类中,在当前组件中为类设置内容,然后再跳转到的组件中去取,这种处理方式效率很高,但是会破坏程序的独立性。
15. OkHttp优势
- HTTP/2 support allows all requests to the same host to share a socket. 链接到同一主机的所有请求共享一个socket连接
- Connection pooling reduces request latency (if HTTP/2 isn’t available). 连接池减少请求延迟
- Transparent GZIP shrinks download sizes. gzip压缩数据大小
- Response caching avoids the network completely for repeat requests. 响应缓存避免重复请求
16. SparseArray
Android提供了SparseArray,这也是一种KV形式的数据结构,提供了类似于Map的功能。和HashMap等数据结构基本一样,唯一不同的就是key和value的类型,HashMap的key值和value值为泛型,但是SparseArray的key值只能为int 类型,value值为Object类型
优点
- 占用内存空间小,没有额外的Entry对象
- 没有Auto-Boxing
缺点
- 不支持任意类型的Key,只支持数字类型(int,long)
- 数据条数特别多的时候,效率会低于HashMap.(因为它是基于二分查找去找数据的, HashMap通过hash函数能快速定位)
总的来说,SparseArray适用于数据量不是很大,同时Key又是数字类型的场景。
HashMap can be replaced by the following:
SparseArray <Integer, Object>
SparseBooleanArray <Integer, Boolean>
SparseIntArray <Integer, Integer>
SparseLongArray <Integer, Long>
LongSparseArray <Long, Object>
LongSparseLongArray <Long, Long> //this is not a public class, but can be copied
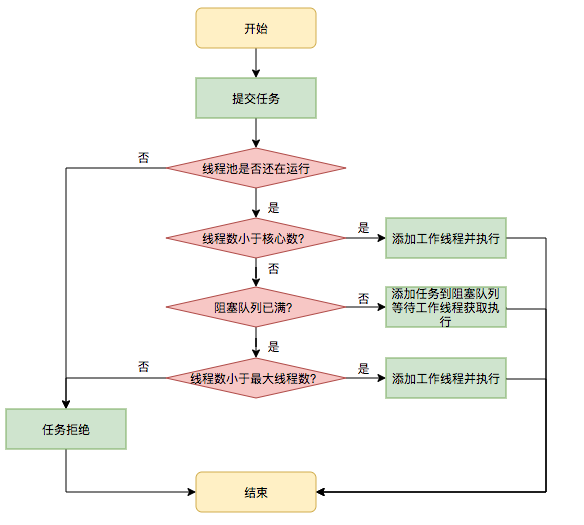
17. 线程池任务调度:
核心线程 > 阻塞队列 > 最大线程
- 首先使用核心线程
- 当任务数大于核心线程数,那么会被插入等待队列中
- 如果等待队列已满,且线程数量未达到最大线程数,则会开启新线程
- 若无法插入等待队列且无法创建新线程,则请求会被拒绝
18.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号