
Redis缓存穿透、击穿与雪崩:问题分析与解决方案
在现代高并发系统中,Redis作为缓存层被广泛使用,其高效的读写性能为系统提供了强大的支持。然而,在使用Redis缓存的过程中,缓存穿透、击穿和雪崩等问题可能会对系统造成严重影响。本文将围绕这些问题展开讨论,并结合Redis的特性提出具体的解决方案。
一、Redis缓存穿透:如何应对无效数据查询?
缓存穿透是指当用户请求的数据既不在Redis缓存中,也不在数据库中时,请求会直接打到数据库层,仿佛“穿透”了缓存层。这种情况通常发生在恶意攻击或误操作导致查询不存在的数据时,若不加以处理,可能导致数据库压力骤增甚至崩溃。
(一)问题分析
- 风险点:
- 当系统查询数据时,首先会在缓存中查找。如果缓存中没有找到,则会进一步在数据库中查找。如果数据库中找到了该数据,则会将其写入缓存以供后续查询使用。然而,如果请求的数据既不在缓存中也不在数据库中,而系统持续接收到对这些不存在数据的查询请求,这将导致系统不断地访问数据库,从而造成性能损失和资源浪费。
- 常见场景:
- 恶意攻击者通过构造大量不存在的数据请求,试图压垮数据库。
- 系统误操作或错误配置也可能导致频繁查询不存在的数据。
(二)解决方案
1. 快速拦截法:为不存在的数据设置临时缓存
为了减少对数据库的无效访问,可以在Redis中为查询不存在的数据创建一个临时键值对,并为其设置较短的过期时间。这种方法简单高效,能有效拦截后续对相同数据的重复查询,避免数据库被频繁访问。
-
具体实现步骤:
- 当查询Redis缓存未命中后,继续查询数据库。
- 若数据库中也不存在该数据,则在Redis中插入一个临时键值对,并设置一个较短的过期时间(如5分钟)。
- 后续对该数据的查询会命中Redis中的临时键,直接返回空值,无需再次查询数据库。
-
优势与适用场景:
- 优势:实现简单,能够快速拦截无效请求,尤其适合防止单点恶意攻击。
- 适用场景:适用于对性能要求较高且需要快速防护的场景。
2. 布隆过滤器:精准过滤无效请求
布隆过滤器是一种基于概率的数据结构,能够高效判断某个数据是否可能存在。结合Redis的特性,我们可以轻松实现布隆过滤器来解决缓存穿透问题。
1. 布隆过滤器的工作原理
- 核心结构:布隆过滤器由一个大型位数组和多个无偏Hash函数组成。
- 存储过程:
- 将每个key通过多个Hash函数计算出下标,并将对应位置的值设为1。
- 查询过程:
- 通过相同的Hash函数计算下标,若位数组中存在0,则说明数据一定不存在;否则可能存在于Redis缓存中。
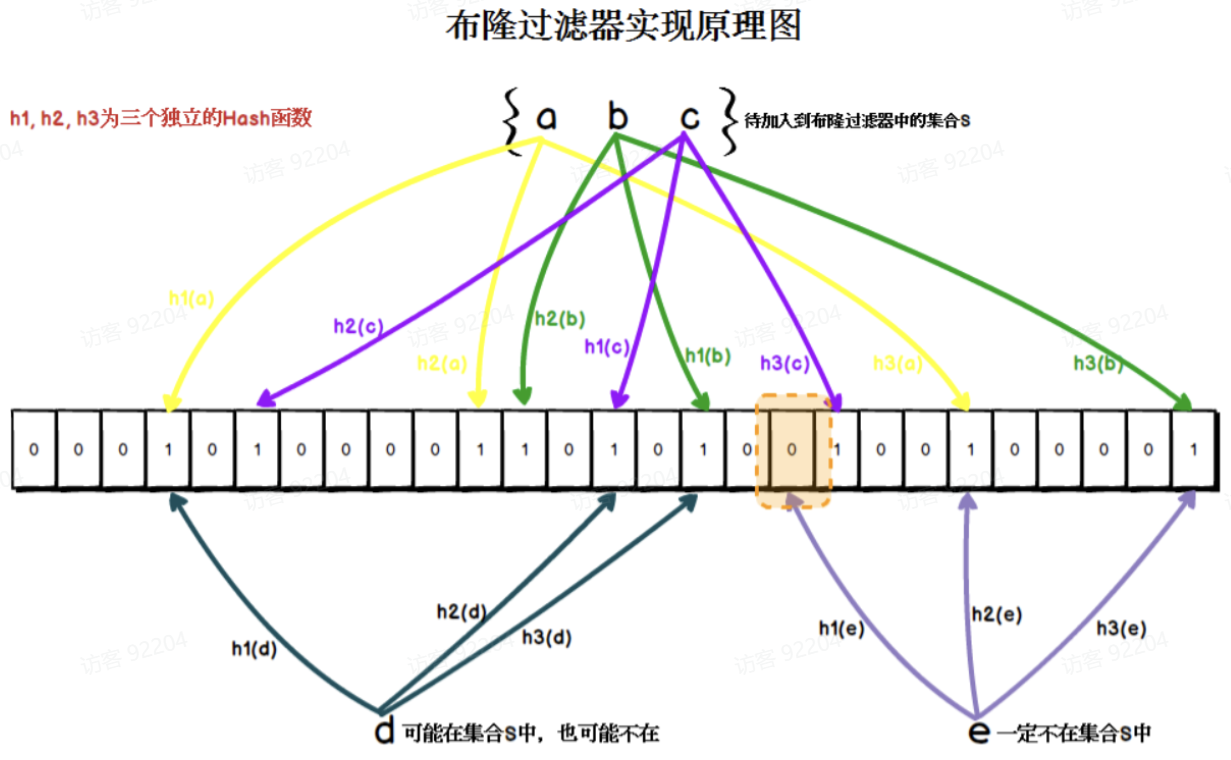
2. 实现流程
- 前置准备:将Redis缓存中的所有key存储到布隆过滤器中。
- 查询流程:
- 在查询Redis缓存之前,先通过布隆过滤器判断当前key是否存在。
- 如果布隆过滤器返回“一定不存在”,则直接返回结果,无需查询Redis或数据库。
- 如果布隆过滤器返回“可能存在”,则继续查询Redis;若Redis未命中,再查询数据库。
- 在查询Redis缓存之前,先通过布隆过滤器判断当前key是否存在。
- 实际应用:Redisson提供了开箱即用的布隆过滤器实现方案,开发者可以轻松集成到现有项目中。
3. 优势与注意事项
- 优势:
- 布隆过滤器占用内存极小,适合大规模数据的快速过滤。
- 能够显著降低无效查询对数据库的压力。
- 注意事项:
- 布隆过滤器存在一定的误判率(即“可能存在”但实际不存在的情况),因此需要根据业务需求调整位数组大小和Hash函数数量,以降低误判率。
通过以上两种方法,我们可以有效应对Redis缓存穿透问题,保护数据库免受无效查询的冲击。
二、Redis缓存击穿:如何应对热点数据失效?
缓存击穿是指某个热点数据的key在Redis中突然过期,导致大量请求在同一时间直接打到数据库层。这种情况通常发生在高并发场景下,若不加以处理,可能会瞬间压垮数据库。
(一)问题分析
- 热点数据:某些数据由于访问频率极高,成为系统的“热点”,例如商品详情页、热门文章等。
- 风险点:当这些热点数据的key在Redis中过期时,若此时有大量并发请求涌入,所有请求都会绕过缓存直达数据库,造成数据库压力骤增。
(二)解决方案
1. 热点数据永不过期
为了避免热点数据的key过期,可以采用“逻辑过期”策略,即在Redis中为热点数据设置一个永不过期的key,并通过后台定时任务定期更新缓存。
- 具体实现步骤:
- 设置永不过期的key:在Redis中存储热点数据时,不设置过期时间。
- 定时更新缓存:
- 使用定时任务(如每天凌晨2点)主动更新热点数据。
- 更新流程:
- 删除Redis中对应的key。
- 从数据库中查询最新数据。
- 将最新数据写入Redis。
- 优势与适用场景:
- 优势:确保热点数据始终存在于Redis中,避免因key过期导致的击穿问题。
- 适用场景:适用于访问频率极高且更新频率较低的数据。
2. 接口限流或降级策略
在高并发场景下,可以通过接口限流或降级的方式控制请求流量,避免数据库被瞬间压垮。
- 限流策略:
- 使用工具如Redis的
INCR命令或中间件(如Sentinel)限制单位时间内的请求数量。 - 对超出限流阈值的请求直接返回友好提示或默认值。
- 使用工具如Redis的
- 降级策略:
- 当检测到Redis缓存失效时,直接返回默认数据或静态页面,避免查询数据库。
- 适用场景:适用于对实时性要求不高的场景。
3. 分布式锁:确保缓存重建的唯一性
在分布式环境下,当热点数据的key过期时,可能会出现多个线程同时尝试重建缓存的情况。为避免重复加载数据库,可以使用分布式锁来确保同一时刻只有一个线程负责重建缓存。
- 实现方案:
- 基于Redisson的分布式锁:
- Redisson是Redis官方推荐的Java客户端,提供了开箱即用的分布式锁功能。
- 示例代码:
RLock lock = redissonClient.getLock("hot_data_lock"); try { // 尝试加锁,最多等待10秒,锁的租约时间为30秒 if (lock.tryLock(10, 30, TimeUnit.SECONDS)) { // 查询数据库并更新缓存 String data = queryDataFromDatabase(); redisTemplate.opsForValue().set("hot_data_key", data); } else { // 获取锁失败,执行降级逻辑或返回默认值 System.out.println("获取锁失败,执行降级逻辑..."); } } catch (InterruptedException e) { Thread.currentThread().interrupt(); // 恢复中断状态 System.out.println("线程被中断..."); } finally { if (lock.isHeldByCurrentThread()) { lock.unlock(); // 确保当前线程持有锁时才释放锁 } } - 优势:简单易用,适合已有Redis项目的场景,性能满足大多数需求。
- 基于Zookeeper的分布式锁:
- Zookeeper通过临时序号节点和监听机制实现分布式锁。
- 优势:性能较高,但需要引入额外的Zookeeper依赖,适合对性能要求较高的场景。
- 基于Redisson的分布式锁:
三、Redis缓存雪崩:如何应对大量key同时过期?
缓存雪崩是指在某一时间点,Redis中的大量key同时过期,导致请求直接打到数据库层。这种情况通常发生在缓存设计不当或系统重启后,所有缓存key在同一时间失效,从而引发数据库压力骤增甚至崩溃。
(一)问题分析
- 风险点:
- 当大量key在同一时间过期时,所有请求都会绕过Redis直接访问数据库。
- 数据库无法承受如此高的并发请求,可能导致服务不可用。
- 常见场景:
- 系统初始化时,所有缓存数据在同一时间加载并设置相同的过期时间。
- 定时任务批量更新缓存时未考虑过期时间的分布。
(二)解决方案
1. 分布式锁:控制缓存重建的并发
当大量key同时过期时,可以通过分布式锁确保同一时刻只有一个线程负责重建缓存,避免多个线程同时加载数据库。
2. 热点数据永不过期
为了避免热点数据的key过期,可以采用“逻辑过期”策略,即不为热点数据设置过期时间,而是通过后台定时任务主动更新缓存。
3. 随机设置key的过期时间
为了防止大量key同时过期,可以在设置缓存时为每个key添加一个随机的过期时间偏移量。例如,原本设置的过期时间为1小时,可以在此基础上增加一个随机值(如0~5分钟)。
- 实现方式:
int baseExpireTime = 60 * 60; // 基础过期时间:1小时 int randomOffset = ThreadLocalRandom.current().nextInt(300); // 随机偏移:0~5分钟 redisTemplate.opsForValue().set("cache_key", data, baseExpireTime + randomOffset, TimeUnit.SECONDS);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号