mysql入门必备
自己对mysql的一点理解吧,当然技术有限,就借鉴的一些大佬的文章,希望能帮助到大家!( ̄▽ ̄)ノ
1.什么是mysql?
mysql是关系型数据库,比较常见的关系型数据库有mysql/oracle/sql server/sqlite ;存数据使用的是表,这样的话结构比较固定,易于维护,我们通常使用crud去操作表中的数据;这里的crud就是insert,delete,update,select
与之相对的是非关系型数据库,如redis/mongoDB,是一种key-value形式的存储,不理解的可以简单的看作json那样存储的;
至于两者之间的优缺点可以简单参考这个大哥的博客
2.mysql中的sql语言有几种?
在mysql中,有4种语言:
(1)DDL -- Data Definition Language,中文是数据库定义语言,也就是create(创建数据库或者数据表),alter(修改数据表相关信息),drop(删除数据库或者数据表)这几个常用关键字,
只有创建表的时候,或者我们后期需要给表加索引之类的可能会用到,平常用的比较少
(2)DML-- Data Manipulation Language,中文是数据库操作语言,这个也就是我们常用的crud操作,注意,我们还需要记住一个explain关键字,这个explain是用于分析你写的sql语句执行效率的一个好用的工具,可以查看到有没有使用到索引等信息
(3)一笔带过
DCL:数据库控制语言,例如Grant —为用户授予权限 revoke–撤回授权权限
TCL:事务控制语言,例如Commit --保存已完成的内容,rollback —回滚
3.什么sql最影响mysql效率?
不考虑读写分离的情况下,最影响mysql的效率的就是查询语句,也就是你写的那一大串的select xx from xx这种,所以我们一般就是优化查询语句;
4.如何分析sql的执行效率呢?
我们要找到一些执行的很慢的sql,首先我们需要开启mysql的慢查询日志,设置时间限制,当超过这个时间限制的就记录到日志文件中,然后我们就用下面这种方式分析就ok了!那么怎么开启慢查询日志呢?看这里
使用explain查看sql的执行计划,如下所示,有兴趣的可以看看执行计划中每个字段的意思,例如possible_keys 表示可能使用的索引,key 表示实际使用的索引等等,有兴趣的可以看看这个大哥的博客

注:还有一种更加细致的分析sql性能消耗的,使用show profile,有兴趣的可以看看这个
5.通常如何优化查询sql呢?
从上面我们知道了如何分析一条sql中的效率,最常用的优化方案便是加索引;
6.索引是什么?
索引是个什么东西呢?这里涉及到数据结构中的一个B+树,索引在磁盘中是以文件的形式存在,其实可以看做一张表,也是会占用物理空间的!!!
通俗易懂一点的解释就是书籍目录:在word文档中目录肯定也是占物理空间的对吧,而且我们点击目录就可以直接跳转到对应的正文处,所以我们可以大概的知道索引可能存的是实际数据的物理地址空间(后面也可以存实际的数据哦!取决于引擎)
那么问题来了,所有索引都是这么存的吗?
7.索引的分类
以innodb为例,索引分为两种:
(1)聚集(clustered)索引,也叫聚簇索引,一个表只能有一个。
(2)非聚集(unclustered)索引,也叫稀疏索引,或者叫做普通索引,多个。
看名字就觉得想放弃了,其实聚集索引就是主键索引,其他的索引都叫做非聚集索引(比如联合索引,唯一索引啥的,这些都是非聚集索引的逻辑分类)
8.两种索引的不同之处
首先说一下mysql中innodb存数据的方式,首先我们要有这么一个想象的画面,数据库表的数据,都是存放在聚集索引下面的,下面画个图就了解了:
有这么一张表,id是主键(这里有个地方需要注意,对于innodb引擎,如果我们在建表语句那里有指定主键,那么就ok,没有指定主键,mysql就会偷偷的创建一个主键索引,我们是看不到的,表中也没有)
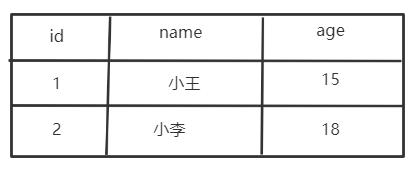
那么主键索引应该就是这样的,下图所示,这个时候实际的数据就是存到主键索引的叶子节点中的!
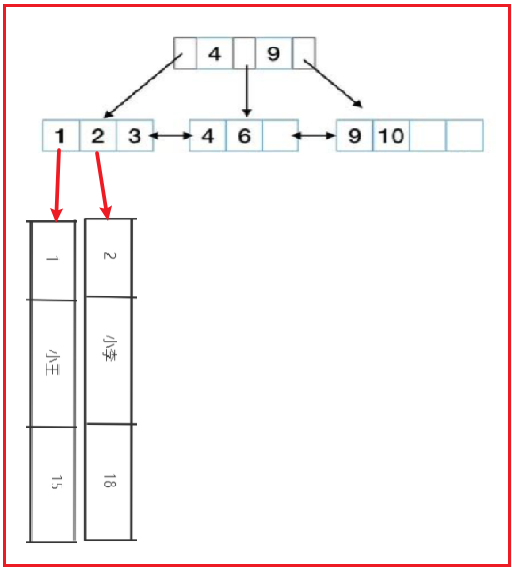
现在问题来了,那么非聚集索引是怎么存的呢?例如我把上表中name字段添加索引...
然后我们思考,非聚集索引的结构也是b+树,和聚集索引一样,不同的是叶子节点中村的就不是实际的数据了,而是主键的值;
我们首先查询到叶子节点的主键的值,然后通过这个主键的值再到聚集索引中查询一次,才能拿到真正的数据!也就是说,通过非聚集索引查数据,一般要查询两次才行!第一次查询出来的是主键的值,第二次通过主键的值去聚集索引中查询实际的数据(用专业一点的词语叫做回表);
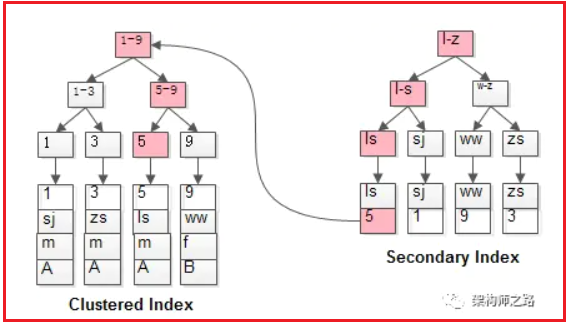
为了更清晰的理解聚集索引和非聚集索引,我在网上偷了一张比较好理解的图(可惜不是b+树,但是原理一样),如下所示,左边是聚集索引,叶子节点存的是实际的数据;右边是非聚集索引,存的是聚集索引的值;
9.是否所有的非聚集索引查询的时候都需要查询两次呢(知识点:覆盖索引)?
在第8点中说了一般是查询两次,通常有 "一般" 这种词语就说明还有特殊情况;
例如还是以上面的那个表为例,首先给name添加索引,那么看看这个sql:select id from user where name = "小王";
首先这个sql肯定会走非聚集索引name,找到叶子节点的存的id为1,这时你觉得还需要把1拿去再去查一次聚集索引么?肯定不需要啊,因为我们sql中只需要这个id就行了啊,已经查询出来了,为什么还要去把那一条数据查询出来呢?
这个时候只需要查询一次就ok了,专业名词叫做覆盖索引,专业解释为:如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’,即只需扫描索引而无须回表。
10.主键自增比较好还是uuid比较好?
经常看到的主键是自增好点还是随机字符串(例如雪花算法,uuid)好?其实数据量小的话是自增好,首先占用的空间小啊,uuid那么多位,另外还因为一点,这里用到一点平衡多叉树的知识,就是分裂(建议新手去看看多叉树的分裂,b+树不是很好理解,点击这里看看2-3-4树的分裂);
而且看到题目中有主键两个字,我们就知道肯定跟聚集索引有关呀!废话,因为我们需要用到主键去构建聚集索引呀,那么如果不是自增的,比如我们再insert数据的时候,主键分别为1,10,,5,20,4,3,1这种,为了保存平衡,那么b+树的节点就会分裂,重新组成新的节点,当数据量很大的时候,性能影响还是很大的,而自增的话,直接就在b+树后面添加节点就行了,不需要分裂!但是使用自增还有一个坏处,就是id可预测性,简直为爬虫等一些东西打开了方便之门...
如果是在分库分表的情况下还是用随机字符串吧,确保全局id的唯一性,有兴趣的还可以再深入了解一下;
11.B+树为什么比B树更适合作为索引,或者说为什么innodb使用B+树作为索引?
这个问题答案我就借用一下这个老哥的;
其实就是要明白B树和B+树的区别,B树所有节点都存了数据,而B+树只有叶子节点才存了数据嘛,这就使得B+树的效率比较稳定,而且由于每个叶子节点之间也有指针相互连接,这样使得范围查询会很方便,不需要从根节点再遍历一次;
12.除了B+树,你还能想到使用什么数据结构当作索引呢?
第一想法肯定是hash表啊,用过hashmap的都知道,这东西是真的好用,时间复杂度O(1);
那么问题来了,这么好用的东西为什么mysql的innodb引擎就是不用呢?留个印象,mysql中的MEMORY存储引擎索引默认用的是hash
例如,你想想你把下面这些数据放到hashmap中,(1,10),(2,20),(3,30),(4,40),然后我需要找到key大于2小于4的数据,怎么找?如果我还要对key进行排序再输出呢,怎么办?
所以用hash作为索引,有几点需要注意:
(1)Hash索引仅仅能满足“=”,“IN”,不能支持范围查询
(2)对于排序操作Hash索引也满足不了
(3)Hash索引不能避免表扫描
(4)当有大量数据的Hash值相等的时候Hash索引的性能大打折扣(这个也就是hash中经典的桶碰撞问题)
13.mysql为什么不用MyISAM引擎作为默认的引擎呢?
这个应该知道一点常识,MyISAM引擎不支持事务,不支持外键,默认是表锁,查询的效率比innodb要高等等, 还会经常和innodb做比较;
我再多说一点:首先,通过前面这么大的篇幅我们知道了如果使用innodb引擎,那么主索引文件(或者聚集索引文件)和数据文件实际上是放在一起的;
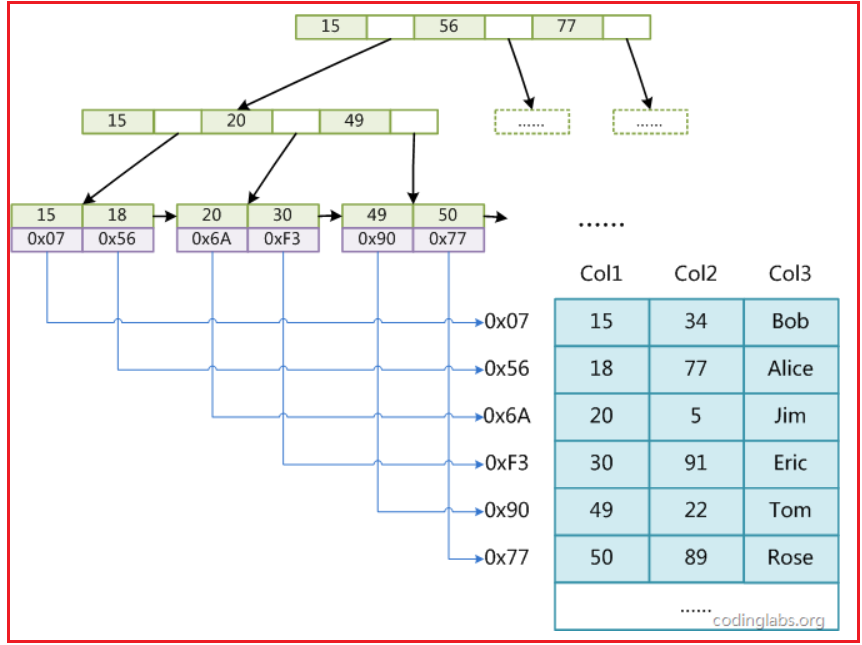
然后,MyISAM引擎引擎索引文件和数据文件是分开的!!!注意,是分开的,也就是说B+树叶子节点存放的是实际行数据的指针,例如下面这样(图是偷的( ̄▽ ̄)ノ),该引擎下所有的索引都是这样的,注意,存的是物理地址啊!
14.什么是最左匹配原则?
在说这个问题之前,我们回忆一下,索引的逻辑分类有单列索引和组合索引吧,其中除了主键索引数据聚集索引,其他的索引都属于非聚集索引。最左原则就是对于组合索引来说的!
还有一点,B+树索引的叶子节点是已经排序好了的,我们才能根据索引值去走B+树查询。
例如我们用最开始我们的表,我们对name和age创建一个组合索引:CREATE INDEX name_age_Index ON "user"("name", "age");
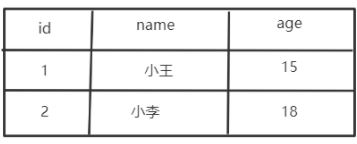
那么现在我们需要将这个name和age看成一个整体,例如就这个组合索引的B+索引如下,我就简单画一下,顺便多添加了几行数据:
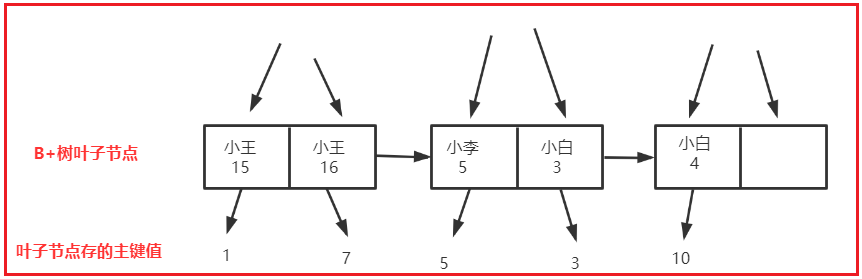
上图我们能发现什么?首先是根据组合索引的第一个字段进行排序的,当第一个字段是一样的,才会继续对第二个字段进行排序;那么你直接使用select id from age = "5",你觉得会走这个索引么?肯定不会啊,因为叶子节点的age明显都不是排序的啊,怎么找啊?
所以只要有点数学基础,即使组合索引包含三列,CREATE INDEX name_age_Index ON "user"("name", "age","score");,我们用到name和age会走索引,但是用到name和score只会走name索引,不会走score索引!
最后再奖励自己一下几个最左匹配原则的题目练习一下,点点这里
=========================截至目前时间2020/12/12==========================
后续还会记录一下mysql相关的知识,未完待续
