带着新人学springboot的应用08(springboot+jpa的整合)
这一节的内容比较简单,是springboot和jpa的简单整合,jpa默认使用hibernate,所以本质就是springboot和hibernate的整合。
说实话,听别人都说spring data jpa很简化操作,不用写多少代码,今天我们就来看看。
顺便一提的是,传统大公司用hibernate比较多,互联网公司用mybatis比较多。
1.大概说一下jpa的好处(熟悉的话可以跳过)
前面说过springboot和mybatis的整合,用mybatis的最大优点就是可以看得见sql语句,我们想改就改,想怎么优化就怎么优化。
但是用过hibernate的小伙伴应该知道,hibernate几乎是看不见sql语句的,因为hibernate底层自动生成,但是前提是你要配置好数据库表和一个javabean的映射关系,也比较麻烦,所以就有了jpa,jpa是一个规范,不是框架(这么说很抽象,你可以把jpa当成一个接口,而hibernate是其中的一个实现类),那么我们使用jpa,那么间接的就使用了hibernate。
那为什么这么麻烦呢?直接使用hibernate不就好了吗?
举个很简单的例子,接口Animal,两个实现类Dog、Cat;假如有个项目我们要使用Dog里的crud方法,直接Animal animal = new Dog();然后animal.xx();
过了一段时间我们又有一个项目要使用Cat里面的crud方法,还是Animal animal = new Cat();然后animal.xxx();
有没有觉得,代码几乎一样,我们只需要搞清楚Animal中的方法,就能使用两个类,学习的成本降低了差不多一半,真正的事半功倍。
jpa的实现常见的hibernate,OpenJPA,TopLink,EclipseJPA这几种,虽然我只用过hibernate,但是,你学会了jpa之后,另外几种你也就会了,因为方法和操作hibernate一样。
还有就是,开发jpa和开发hibernate的居然是同一个作者...emmmm...
再说一下hibernate和spring整合的时候,应该发现了Dao层还是要写贼多的东西,各种crud方法要慢慢实现;即使用jpa之后,spring整合jpa(实现产品为hibernate),还是摆脱不了要实现crud方法,虽然代码少写了一点,但是治标不治本;
但是就当jpa和Spring Data整合之后,你几乎看不到代码了!就一个接口放在那里,即使你有特殊的需求,你只要写个方法,方法名符合一定的规范,就ok了,你都不用实现(当然,实际的项目中不下心可能就碰到了特别复杂的需求,那么还是老老实实的写sql吧!)。
spring data是spring的一个子项目,专门针对持久化层的,我们用过的spring data radis,spring data rabbitmq都是这个项目的模块之一。
2.简单的搭建一下环境
首先,创建springboot项目,要导入的模块web+mysql+jpa+1.5.18
话说以前我这版本应该是1.5.16啊,怎么偷偷的趁我不注意自动给我升级到1.5.18了......

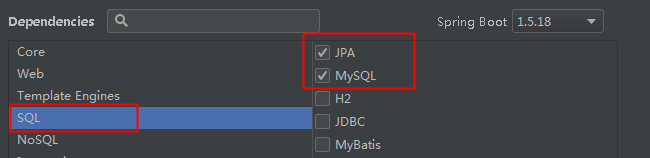
然后配置文件配置数据源(就用默认的数据源)

配置一个javabean去对应和一张表对应
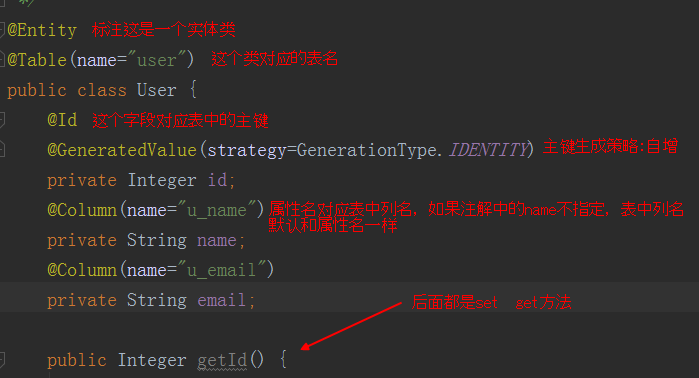
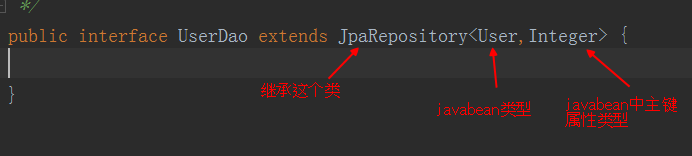
来看看现在的dao层是什么鬼。
看清楚,这是一个接口,而且不用标示注解!
为了方便,就不写service层了,直接controller层
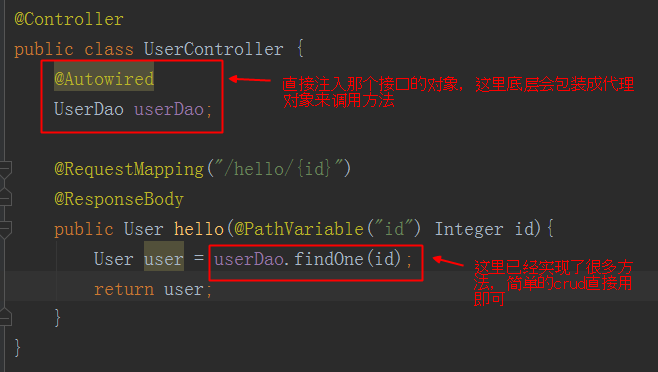
然后运行springboot项目,就会在数据库创建user表
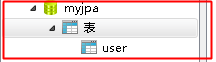
我手动往表里添加几条数据
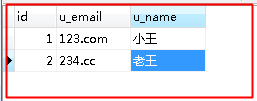
打开浏览器,输入url:http://localhost:8080/hello/2,可以看到结果和控制台的sql语句
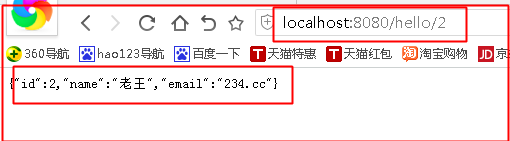

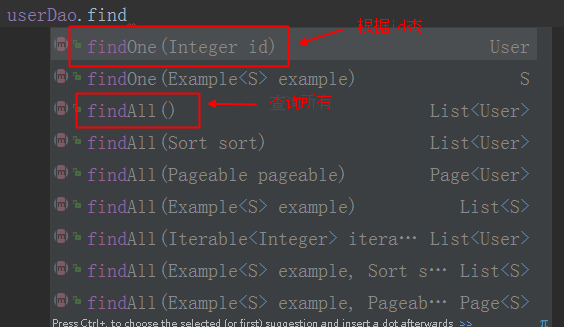
这是最简单的使用了,其实这里关键是userDao到底可以用哪些方法,截了一下图,大概可以看到基本的crud方法应该是都实现了,你只需要传入相关的参数即可。
话说每次都说crud,但是具体是哪几个单词知道吗?C(create),R(Read),U(update),D(delete),看到名字应该知道意思吧!
在springdata jpa中,增加和修改方法都是save()
删除,delete()

查询,方法就多了,但都是类似findxxx(),具体的自己去尝试
3.貌似比较高级的操作
所谓高级的操作,无外乎就是自定义嘛!
因为有的高手就觉得我为什么用你这个方法啊,我能不能自定义啊?比如我要..emmm...按照名字来查找记录,ok,jpa也提供给你,但是你要想好一个很特别很特殊的方法名,这个方法名不单单你认识,而且还要程序认识。(玛德,想个方法名都这么多要求,日了狗哦!)
那么我们在dao层自定义一个方法试试(看清楚方法名!) 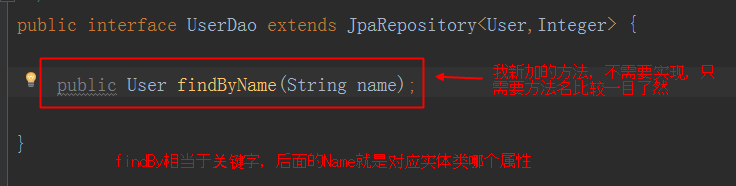
controller层我试试这个方法
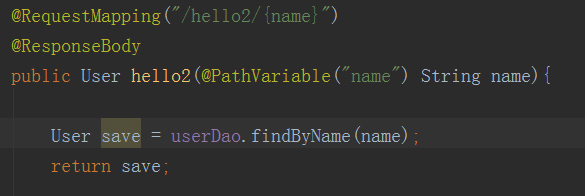
看看浏览器能不能访问,能访问,ok

所以现在我们要知道的就是自定义的方法名,要符合什么规范?弄清楚这个了,那自定义方法也就ok了。
其实规则就跟原生的sql语句差不多,就是提取了关键字而已,比如我要根据name模糊查找,sql语句就是xxx where name like ‘王%’,关键字就是like;于是我们方法名就是findByNameLike(String name),括号里就是我们要传进去的条件,相当于‘王%’。
我猜底层应该会解析方法名,拼接成sql语句,向数据库发送sql语句进行操作,本质上,一个方法就是一条sql语句。
还有一些关键词,And,Or,Between,OrderBy等等,都可以用于方法名。
我随便列举一下几个方法名参考一下:
findByUserName(String userName);
findByUserNameOrEmail(String username, String email);
countByUserName(String userName);
findByEmailLike(String email);
List<User> findByUserNameOrderByEmailDesc(String email);
看名字应该知道是干什么的了,好好体会一下!sql语句用的熟练了,这个应该不难。
4.一点小操作
有的时候理想很丰满,现实却很骨感!你一不小心碰到了一个非常复杂的需求,然而用上面这些规则却总是一副日了狗的表情,你就很怀念用sql语句了!玛德,要是我能用sql语句的话,我不要一分钟就能做好了,现在让我编这个方法名就是特么编不出来啊!
ok,springboot data jpa也考虑到了你这种需求,于是我们便能像用mybatis的注解版一样使用jpa了。
请看下面dao层的方法,是不是和mybatis注解版十分相似啊?不过要注意,这里注解里面的语句没记错的话应该是hql语句吧,操作的是实体类!
当然如果你要写原生sql语句,在@Query里面就要加个属性:nativeQuery=true,就可以写原生sql语句了,很简单,这里不多说。
可以取别名,可以有占位符,占位符可以直接是?;不过别人都是?1:代表第一个占位符;如果还有?2:第二个占位符; 还有?3:第三个占位符。。。占位符和参数一一对应,当然还可以用@Param(“xxx”)和形参进行参数绑定,这时hql语句占位符也会发生变化。
我们就不搞这些花里胡哨的了,怎么简单怎么来:

查询只要@Query一个注解就可以了,但是增加,修改,删除还需要另外一个注解@Modifying,再看一个方法。
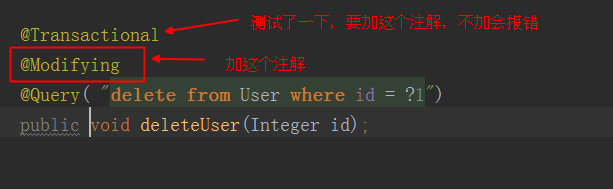
要加那个事务的注解,假如不加,会报错,下图所示,emmm....建议增上改方法除了@Query之外,都加上那这两个注解

然后我运行应用,测试了,成功,你们可以自己试试!
其实后面还有分页,多表查询,有点小麻烦所以我就很不要脸的跳过了,嘿嘿嘿!不过还是大概说一下:
分页就是自己定义一下规则,一页多少数据,多少页,包装成一个对象,放到findAll方法里就可以了;而多表查询,前提是两个类建立好关系(就是一对多,多对一什么的),然后重点就是编写@Query里面的hql语句了;
这里我就是给新手小哥们看一看基本操作,想要深入了解的小伙伴可以自己查查资料看看分页和多表级联操作。
其实本来是不想写这个springboot data jpa的,因为用的比较少,还不如springboot+mybatis好玩,不过啊,因为我后面我要说springboot和一个东西的整合,太像springboot jpa了,于是我也顺便说说jpa得了。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core内存结构体系(Windows环境)底层原理浅谈
· C# 深度学习:对抗生成网络(GAN)训练头像生成模型
· .NET 适配 HarmonyOS 进展
· .NET 进程 stackoverflow异常后,还可以接收 TCP 连接请求吗?
· SQL Server统计信息更新会被阻塞或引起会话阻塞吗?
· 本地部署 DeepSeek:小白也能轻松搞定!
· 传国玉玺易主,ai.com竟然跳转到国产AI
· 自己如何在本地电脑从零搭建DeepSeek!手把手教学,快来看看! (建议收藏)
· 我们是如何解决abp身上的几个痛点
· 如何基于DeepSeek开展AI项目