


福大软工1816 · 第五次作业 - 结对作业2
Deadline: 2018-10-10 23:00pm
零、任务
WordCount进阶需求:结合个人项目与结对1的需求,编码实现顶会热词统计器
一、编码要求
- 按照[附录1]提示,Fork github 项目到自己的仓库,在Github仓库中新建一个“队友1学号&队友2学号”为名的文件夹,完成项目后正确发起一个Pull Request。
- 在开始实现程序之前,在PSP表格[附录2]记录下你估计在程序开发各个步骤上耗费的时间,在你实现程序之后,在PSP表格记录下你在程序的各个模块上实际花费的时间。
- 使用C++ 或者Java语言实现,C++请使用Visual Studio Community 2017进行开发,运行环境为64-bit Windows 10。
- 提交的代码要求经过Code Quality Analysis工具的分析并消除所有的警告。
- 完成项目的首个版本之后,请使用性能分析工具Studio Profiling Tools来找出代码中的性能瓶颈并进行改进。
- 使用Github[附录3]来管理源代码和测试用例,代码有进展即签入Github。签入记录不合理的项目会被助教抽查询问项目细节。
- 使用单元测试[附录4]对项目进行测试,并使用插件查看测试分支覆盖率等指标;写出至少10个测试用例确保你的程序能够正确处理各种情况。
- 两人制定需要共同遵守的代码规范,并在博客中说明各自负责的部分。
二、编码的具体要求
新增功能,并在命令行程序中支持下述命令行参数。说明:字符总数统计、单词总数统计、有效行统计要求与个人项目相同
1. 使用工具爬取论文信息
- 从CVPR2018官网爬取今年的论文列表,输出到result.txt(一定叫这个名字),内容包含论文题目、摘要,格式如下:
- 为爬取的论文从0开始编号,编号单独一行
- 两篇论文间以2个空行分隔
- 在每行开头插入“Title: ”、“Abstract: ”(英文冒号,后有一个空格)说明接下来的内容是论文题目,或者论文摘要
- 后续所有字符、单词、有效行、词频统计中,论文编号及其紧跟着的换行符、分隔论文的两个换行符、“Title: ”、“Abstract: ”(英文冒号,后有一个空格)均不纳入考虑范围
- 可参考样例如下:

- 请在博客中注明你所使用的爬虫工具,并说明如何使用
- 如果是使用C++或Java实现的,在博客中简单解释你的思路,会有额外加分
2. 自定义输入输出文件
- -i 参数设定读入文件的存储路径,-o 参数设定生成文件的存储路径
- 格式如下:
WordCount.exe -i [file] -o [file]
一个例子如:
WordCount.exe -i input.txt -o output.txt
/*
*从input.txt读取需要统计的文本,将统计结果输出到output.txt
*/
3. 加入权重的词频统计
- 属于Title的单词权重为10,属于Abstract 单词权重为1
- 在上文图片样例中,embodied 的频率为 1x10+2x1=12。(在题目中出现1次,在摘要中出现2次,其中1次由于图片大小未能显示)
- 进行单词统计时依旧正常累加
- -w 参数设定是否采用不同权重计数
- -w 参数与数字 0|1 搭配使用,用于表示是否采用不同权重:0 表示属于 Title、Abstract 的单词权重相同均为 1 ;1 表示属于 Title 的单词权重为10,属于Abstract 单词权重为1。格式如下:
WordCount.exe -w [0|1]
一个例子如:
WordCount.exe -w 1
/*
*程序会输出input.txt中采用不同权重统计出的词频前10的单词
*/
4. 新增词组词频统计功能
- 统计文件夹中指定长度的词组的词频
- m (2 ≤ m ≤ 10)个由分隔符隔开的单词组成一个词组,词组只存在于同一个字段中,即不能跨越 Title、Abstract 组成词组
- 使用词组词频统计功能时,不再统计单词词频,而是统计词组词频,但不影响单词总数统计
- 最终只输出频率最高的10个词组,频率相同的词组,优先输出字典序靠前的词组
- -m 参数设定统计的词组长度
- -m 参数与数字配套使用,用于设置词组长度,格式如下:
WordCount.exe -m [number]
一个例子如:
WordCount.exe -m 3
/*
*要求程序统计长度为3的词组
*/
例:输入文件中内容为:
0
Title: Monday Tuesday Wednesday Thursday
Abstract: Friday
则输出如下:
characters: 40
words: 5
lines: 2
<monday tuesday wednesday>: 1
<tuesday wednesday thursday>: 1
5. 自定义词频统计输出
- 用户指定输出前 n 多的单词(词组)与其频数
- -n 参数设定输出的单词数量
- -n 参数与数字搭配使用,用于限制最终输出的单词(词组)的个数,表示输出频数最多的前 [number] 个单词(词组),0 ≤ [number] ≤ 100格式如下:
WordCount.exe -n [number]
一个例子如:
WordCount.exe -n 1
/*
*输出文件中出现次数最多的那个单词
*/
6. 多参数的混合使用
实际测试时,在一句命令行语句中
- -i 、-o 、-w 参数一定会出现
- -m、-n 参数可能都不出现,可能只出现一个,也可能都出现
- 未出现 -m 参数时,不启用词组词频统计功能,默认对单词进行词频统计
- 未出现 -n 参数时,不启用自定义词频统计输出功能,默认输出10个
- 参数之间的顺序并不固定
- 一个完整例子如下:
WordCount.exe -i input.txt -m 3 -n 3 -w 1 -o output.txt
/*
*统计input.txt文件中的字符数、单词数、有效行数、出现次数排在前3的3个单词长的词组,并采用权重累计频数,最终统计结果输出到output.txt
*/
例:输入文件中内容为:
0
Title: Monday Tuesday Wednesday Thursday
Abstract: Monday Tuesday Wednesday Thursday Friday
则输出如下:
characters: 74
words: 9
lines: 2
<monday tuesday wednesday>: 11
<tuesday wednesday thursday>: 11
<wednesday thursday friday>: 1
7. 附加题(20')
本部分不参与自动化测试,如有完成,需在博客中详细描述,并在博客中附件(.exe及.txt)为证。附加功能的加入不能影响上述基础功能的测试,分数取决于创意和所展示的完成度,创意没有天花板,这里不提出任何限制,尽你们所能去完成。
要求:发挥个人的奇思妙想,对论文列表进行更多的挖掘并进行数据分析,为你们举几个栗子:
- 从网站综合爬取论文的除题目、摘要外其他信息
- 如:论文类型、作者、作者单位等等

- 如:论文类型、作者、作者单位等等
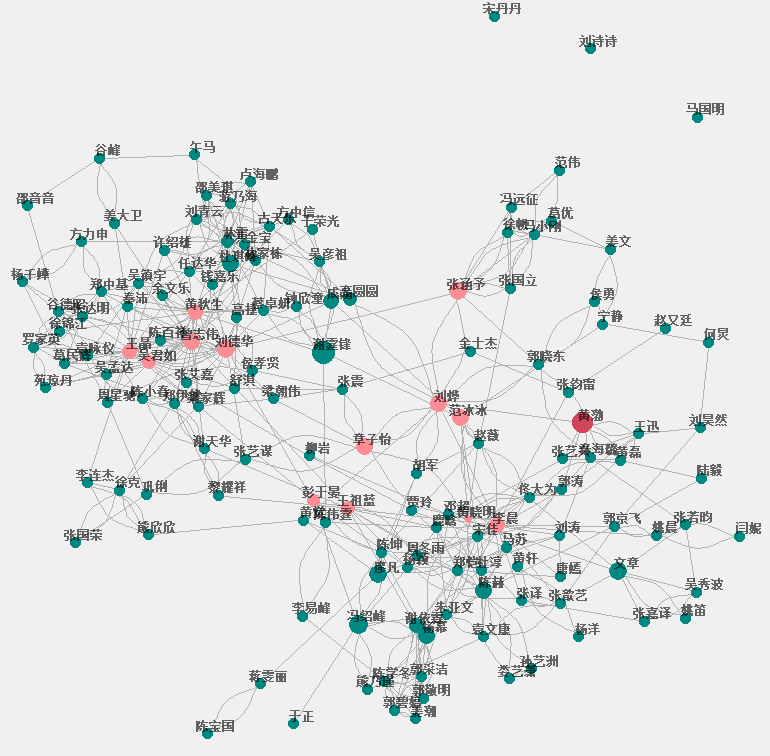
- 分析论文作者的所属地, 哪些国家、哪些高校发表的论文比较多
- 分析论文列表中各位作者之间的关系,论文A的第一作者可能同时是论文B的第二作者,不同论文多位作者之间可能存在着联系
- 对数据的图形可视化做出一些努力,比如对上一条功能可以形成关系图谱
三、博客撰写(模版/评分)
- 在文章开头给出结对同学的博客链接、本作业博客的链接、你所Fork的同名仓库的Github项目地址【1'】
- 给出具体分工【1'】
- 给出PSP表格【1'】
- 解题思路描述与设计实现说明【15'】
- 爬虫使用【3'】
- 代码组织与内部实现设计(类图)【6'】
- 说明算法的关键与关键实现部分流程图【6'】
- 附加题设计与展示【20'】
- 设计的创意独到之处
- 实现思路
- 实现成果展示
- 关键代码解释【2'】
- 贴出你认为重要的/有价值的代码片段,并解释【2'】
- 性能分析与改进【6'】
- 描述你改进的思路【5'】
- 展示性能分析图和程序中消耗最大的函数【1'】
- 单元测试【5'】
- 展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
- 贴出Github的代码签入记录【1'】
- 请合理记录commit信息
- 遇到的代码模块异常或结对困难及解决方法【5'】
- 问题描述
- 做过哪些尝试
- 是否解决
- 有何收获
- 评价你的队友【2'】
- 值得学习的地方
- 需要改进的地方
- 学习进度条【1'】
四、测试须知(请认真阅读,不符规范的部分在总分基础上进行扣分)
组织目录
助教在测试时,将运行自动测试程序编译源文件并运行,进行批量测试,因此请保证项目的组织目录符合要求.
-
Java
对于使用Java语言的项目有以下两点要求:
- 【以两人学号为名的文件夹中】的目录下必须有src文件夹
- 在src目录下必须有名为Main.java文件,且Main.java中包含 public static void main(String[] args) 方法
一个Java项目的示例组织目录如下所示:
031602111&031602222 (文件夹名字为两人学号)
|- src
|- Main.java(主程序,可以从命令行接收参数)
|- lib.java(包含其它自定义函数,可以有多个,对名字不做要求)
|- Main.class(编译生成的可运行程序)
|- lib.class(编译生成的可运行程序)
|- cvpr
|- result.txt(爬虫结果)
|- Main.java(爬虫程序,可以爬取CVPR2018论文列表)
-
C++
对于使用C++ 语言的项目有以下两点要求:
- 【以两人学号为名的文件夹中】的目录下必须有src文件夹
- 在src文件夹中是可在VS2017下编译运行的解决方案,解决方案的名字必须为 WordCount
一个C++工程示例组织目录如下所示:
031602111&031602222 (文件夹名字为两人学号)
|- src
|- WordCount.sln
|- WordCount
|- stdafx.cpp
|- stdafx.h
|- WordCount.cpp
|- WordCount.vcxproj
|- cvpr
|- result.txt(爬虫结果)
|- Crawler.cpp(爬虫程序,可以爬取CVPR2018论文列表)
规范说明
- 助教在测试时,将自动按照指定目录搜索cpp文件,使用指定编译环境编译源代码,并利用命令行进行批量测试,请务必遵照上述组织目录
- 关于在Github的上传
- 不要上传整个项目工程文件,很大
- 不要上传单元测试工程文件,测试详情请在博客中写明
- 不要把作业上传在结对文件夹以外的地方,可能导致冲突
- 助教会在作业结束后统一处理 pr
- 本次测试数据将采用CVPR2018会议论文的实际数据
- 一共10个测试用例,每个用例限时60s
- 每通过一个用例得分+20,其中字符统计正确+1,单词统计正确+1,有效行统计正确+1,词频统计正确+15,单个用例执行时间在10s内+2(可能适应总体情况调整)
- 这次的用例较大,请保证你们的程序不会崩溃,可使用爬虫的结果检验程序性能
- 最后,自动测试得分占本次作业的40%
五、附录
1. Fork项目并创建文件夹
- 打开链接,点击Fork按钮,将仓库 personal-project 拷贝到自己的同名仓库中,如下图所示:

- 拷贝成功后,可以看到自己已经拥有了一个同名仓库
- 在对应语言下创建以学号为名的文件夹,确保所有本地的改动都已 push 后,可以在自己的仓库中向源仓库(personal-project)发起Pull Request:
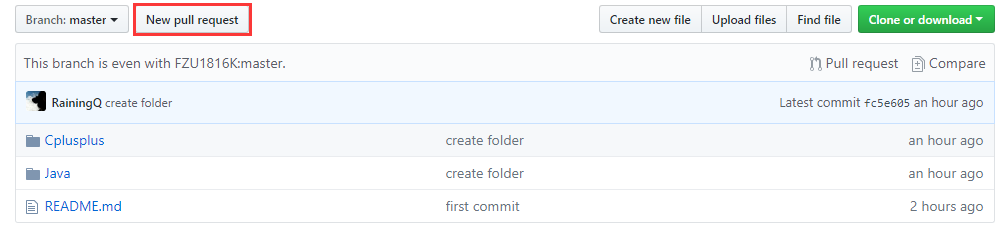
- 点击Create pull request,提交请求,此后只需等待仓库主人通过审核后,你的代码就可以成功合并进源仓库(personal-project)
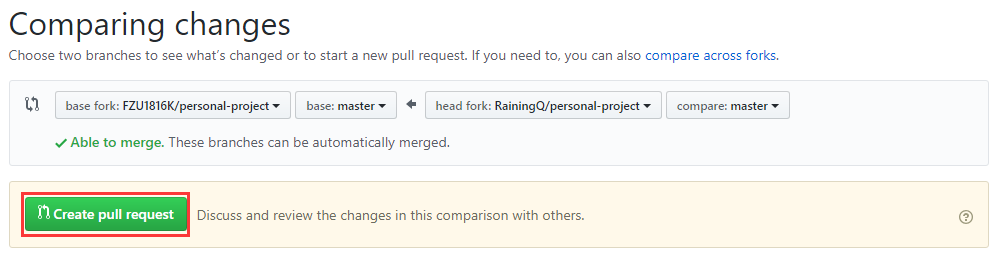
- 如在发起 pull request 后代码发生新的变化,可重复发起 pull request ,助教将合并最新的修改到源仓库
2.PSP表格
PSP是卡耐基梅隆大学(CMU)的专家们针对软件工程师所提出的一套模型:Personal Software Process (PSP, 个人开发流程,或称个体软件过程)。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | ||
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | ||
| · Design Spec | · 生成设计文档 | ||
| · Design Review | · 设计复审 | ||
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | ||
| · Design | · 具体设计 | ||
| · Coding | · 具体编码 | ||
| · Code Review | · 代码复审 | ||
| · Test | · 测试(自我测试,修改代码,提交修改) | ||
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | ||
| · Size Measurement | · 计算工作量 | ||
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 |
| | 合计 | |
在动手开发之前,要先估计将在程序各模块开发所需耗费的时间,以及完成整个项目所需的时间,将这个[估计值]记录下来,写成PSP 的形式。
PSP的目的是:记录工程师如何实现需求的效率,和我们使用项目管理工具(例如微软的Project Professional,或者禅道等)进行项目进度规划类似。
有关PSP的更多内容,请自行阅读邹欣老师的博客:现代软件工程讲义 2 工程师的能力评估和发展
3.Github
请阅读邹欣老师的博客:源代码管理,了解源代码管理的10个实践问题。
本次作业要求使用Github进行源代码管理,代码有进展即签入Github。签入记录不合理的项目会被助教抽查询问项目细节。
对代码签入的具体要求如下:根据需求划分功能后,每做完一个功能,编译成功后,应至少commit一次。本例中,至少应区分基本功能和扩展功能,即分别针对基本功能、扩展功能,编译成功后,总共至少应commit两次。具体的功能划分,请自行定义,并在撰写博客时体现出来,遵循自己对需求的功能划分来提交代码即可。
对Commit不是很熟悉的话,请阅读阮一峰的博客:Commit message 和 Change log 编写指南,了解更多细节。
4.单元测试
请根据自己以往积累的测试经验,在编码完成之后,提交产品之前,设计测试用例,并编写单元测试,对自己的项目进行测试。
首先,至少应采用白盒测试用例设计方法来设计测试用例,其他测试方法不限。其次,要设计至少10个测试用例,确保你的程序能够正确处理各种情况。最后,结合测试评估的要求,对自己的测试设计进行评价,这些测试用例能满足该程序测试的要求吗?
另一个重要的措施是要把单元测试自动化,这样每个人都能很容易地运行它,并且可以使单元测试每天都运行。每个人都可以随时在自己的机器上运行。团队一般是在每日构建中运行单元测试的,这样每个单元测试的错误就能及时被发现并得到修改。
推荐阅读邹欣老师的博客:现代软件工程讲义 2 开发技术 - 单元测试 & 回归测试

