前言
- 学习渠道:慕课网:Python入门
- 记录原因:人总归要向记忆低头[微笑再见.gif]
- 记录目标:形成简洁的知识点查阅手册
变量和数据类型
- ####赋值
- 在Python中,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量。这种变量本身类型不固定的语言称之为**动态语言**
- ####变量在计算机内存中的表示
- 对`a = 'ABC'`,在内存中创建了一个'ABC'的字符串和一个名为a的变量,并把它指向'ABC'。
- ####字符串
- 转义
- 符号:`\`
- 反斜杠本尊:`\\`
- 单行转义:`r'……'`
- 多行转义:`r'''……'''`
- Unicode编码
- `# -*- coding: utf-8 -*-`
- `print u'中文'`
- ####运算
- 整数与浮点数
- 只能使用小括号,但是括号可以嵌套很多层
- Python的整数除法,即使除不尽,结果仍然是整数,余数直接被扔掉
- Python的整数运算结果仍然是整数,浮点数运算结果仍然是浮点数
- 整数运算的结果永远是精确的,而浮点数运算的结果不一定精确,因为计算机内存再大,也无法精确表示出无限循环小数
- 布尔型(短路计算)
- Python解释器在做布尔运算时,只要能提前确定计算结果,它就不会往后算了,直接返回结果。
- 在计算 a and b 时,如果 a 是 False,则根据与运算法则,整个结果必定为 False,因此返回 a;如果 a 是 True,则整个计算结果必定取决与 b,因此返回 b。
- 在计算 a or b 时,如果 a 是 True,则根据或运算法则,整个计算结果必定为 True,因此返回 a;如果 a 是 False,则整个计算结果必定取决于 b,因此返回 b。
List和Tuple类型
- ####表示:[]
- ####创建list
- `L = [314, 'wyq', True]` #Python是动态语言
- `empty_list = []`
- ####索引元素
- `L[0]` #314,有效地址是0,1,2
- `L[-1]` #True,倒序访问,有效地址是-1,-2,-3
- ####增加元素
- 前插
- `L.insert(0, 35)` #将新元素添加到指定索引位置的前面,L = [35, 314, 'wyq', True]
- `L.insert(-1, 'zxy')` #L = [314, 'wyq', 'zxy', True]
- 后插
- `L.append('zxy')` #将新元素添加到list末尾,L = [314, 'wyq', True, 'zxy']
- ####删除元素
- `L.pop()` #删除list的最后一个元素,并返回被删除的元素,True,L = [314, 'wyq']
- `L.pop(-1)` #效果同上
- `L.pop(1)` #删除list的指定索引元素,并返回被删除的元素,‘wyq’,L= [314, True]
- 删除前面的元素,后面的元素会自动“跟上”
- ####替换元素
- `L[2] = False` #L = [314, 'wyq', False]
- `L[-1] = False` #效果同上
- 慕课上的一道例题:
- 
- ####列表生成式
L = [x * x for x in range(1, 11)] #[1,11)之间自然数的平方的list
L = [x * x for x in range(1, 11) if x % 2 == 0] #加上条件过滤,只剩下偶数的平方
L = [x * y for x in range(1, 3) for y in range(1, 4)] #for循环嵌套
#复杂表达式生成表格
tds = ['<tr><td>%s</td><td>%s</td></tr>' % (name, score) for name, score in d.iteritems()]
print '<table>'
print '<tr><th>Name</th><th>Score</th><tr>'
print '\n'.join(tds)
print '</table>'
#字符串可以通过 % 进行格式化,用指定的参数替代 %s
#字符串的join()方法可以把一个 list 拼接成一个字符串。
- ###元组tuple
- ####表示:()
- ####创建tuple
- `empty_t = ()`
- `t = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]`
- `t = tuple(range(10))` #效果同上
- `t = (range(10))` #这样创建的是一个list
- `t = (1,)` #单元素tuple多加一个逗号,避免歧义
- ####索引:同list
- ####特点
- 区别于list:一旦创建完毕,不可修改(增删替)
- 利用tuple的特性,只可读不可写,类似const一样,使用tuple来防止数据被修改
- ####可变的tuple
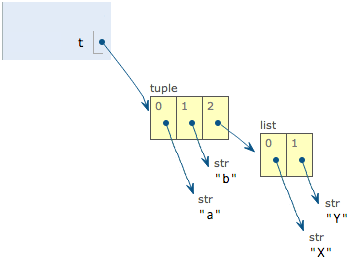
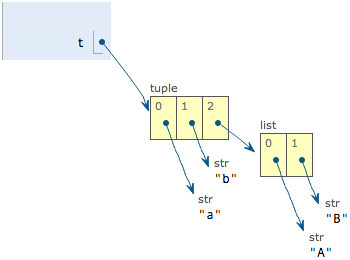
- `t = (0, 1, [3, 4])` #'可以通过L = t[2]来取得list,改变list即改变tuple
- tuple的不可修改,是因为其每个元素的指向不变,若元素指向一个可变的变量,则tuple可变,创建一个完全不可变的tuple须保证tuple的每一个元素本身不可变
- 来自慕课的图示:
- 
条件判断和循环
if 判断条件 :
语句块
#严格4空格缩进
#Python交互环境下需空行退出缩进
elif :
语句块
else :
语句块
- ###循环
- ####for循环:
for 变量 in (list or tuple)
语句块
#依次将有序序列中的值赋给变量,并执行语句块
- ####while循环
while 循环条件:
语句块
#while循环不会迭代 list 或 tuple 的元素
#根据表达式判断循环是否结束
- ####退出循环:`break`
- ####进入下一次循环:`continue`
Dict和Set类型
d = {
key: value, #key不能重复
……
}
- ####索引元素
- `d[key]` #若key不存在,则报错KeyError
room = {
sy:a
wyq: b
zxy:c
zxt:d
}
#为避免KeyError,先判断一下key是否存在
if 'wyq' in room:
print room['wyq']
- `d.get(key)` #若key不存在,则返回 None
- ####增加元素
- `d[key] = value` #若key不存在,则增加该条记录;若key存在,则替换原value
- ####迭代
- 迭代value
for val in room.valus(): #使用itervalues()效果相同
print val
# a
# b
# c
# d
# values() 把dict转换成了包含value的list。
# itervalues() 不会转换,它在迭代过程中依次取出 value,所以 itervalues() 方法比 values() 方法节省了生成 list 所需的内存。
- 迭代key和value
for key, val in room.items(): #使用iteritems()效果相同
print key, ' : ', val
# items() 把dict对象转换成了包含tuple的list,对list迭代
# items()与iteritems()的区别类似于values()与itervalues()
- iteritems()和itervalues()属于Python 2.x
- ####dict的特点
- **查找速度快**,无论dict有10个元素还是10万个元素,查找速度都一样
- **无序**
- **key 元素不可变**,list不能作为key元素
- ###Set无序不重复集合
- ####表示:set([])
- ####创建
- `s = set([1, 2, 3, 4])` #传入list赋值,若list内元素重复,自动去重
- ####访问
- set存储的是无序集合,无法通过索引访问。
- 访问 set中的某个元素实际上就是判断一个元素是否在set中
room = set(['sy', 'wyq', 'zxy', 'zxt'])
print 'wyq' in room #返回true
- ####特点
- set的内部结构和dict很像,唯一区别是不存储value,因此,判断一个元素是否在set中速度很快。
- 元素必须是**不变对象**
- **无序**
- ####遍历
s = set([('sy', 528), ('wyq', 530), ('zxy', 540), ('zxt', 545)])
#set内存储的是不变对象,所以这里用tuple得到他们
for t in s:
print t[0], ':', t[1]
- ####更新
- 增加:`s.add(element)` #若element已存在,不会报错
- 删除:`s.remove(element)` #若element不存在,报错
函数
- Python内置函数
- 也可在交互命令行中通过help(function)查询
-
引用函数包:import
-
定义函数
#多值返回的实际是一个tuple, 也可返回(None)
def 函数名(参数1, 参数2, ……):
语句块
return 结果1, 结果2, ……
#含有参数默认值的函数
def 函数名(参数1, 参数2 = 默认值2, 参数3 = 默认值1)
语句块
return
#能接受任意个参数的函数,实际是将多个参数组装成一个tuple(*args)
def 函数名(*args):
语句块
return
- ###递归函数
- 递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
- **使用递归函数需要注意防止栈溢出。**在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。例如,fact(10000)。
- 
- range(m, n+1):获得m~n的连续数列list
- len():长度
- s.capitalize():首字母大写,其余小写
- s.upper(): s全部大写
- s.lower():s全部小写
- s.title():
- s.strip(rm): 删除 s 字符串中开头、结尾处的 rm 序列的字符,当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' ')
- zip(list1, list2):合并list
- isinstance(x, str):判断变量 x 是否是字符串
切片
- 操作对象
- list
- tuple
- 字符串
- Unicode
- 两个参数
- L[m: n] #取L第m个到第n-1个元素,[ L[m], L[m+1], ……, L[n-2], L[n-1] ]
- L[: n] #m = 0
- L[:] #从头到尾,实际上复制出一个新的list
- 三个参数
- L[m: n: k] #在L的第m个到第n个元素中,每隔k个取一个
- 可倒序,可嵌套
- L = [range(101)]
- L[-10] #取L最后10个数
- L[4::5][-10:] #取最后10个5的倍数
迭代
- `for x in list/tuple/str/Unicode/dict/set:`
- `for…in…`可以迭代任何可迭代对象
- Python中,迭代永远是取出元素本身,而非元素的索引
-
索引迭代
L = ['sy', 'wyq', 'zxy', 'zxt']
for index, name in enumerate(L):
print index, ' - ', name
# 0 - sy
# 1 - wyq
# 2 - zxy
# 3 - zxt
# enumerate()将L化为[(0, sy), (1, wyq), (2, zxy), (3, zxt)],实际又在迭代tuple
后记
- 评论区是个神奇的地方
- 说好只笔记最简要的内容,为什么记了这么多[懵逼.jpg]
- 使用Python编程总是漏掉冒号[气哭.gif]
- 真的好基础emmm万丈高楼平地而起




