
分库分表
- 优点
- 提升数据的访问速度(分表)
- 减小单个数据表的数据量(水平、垂直都减小了),也就提高了数据的访问检索速度
- 其实是人为得定一个逻辑,决定怎么去拆分子表和在需要时寻找子表。比如最简单的把一个表根据id的结尾数字分为0到9的10张表(有可能需要更复杂的办法来尽量让各子表的数据均匀分布),然后从代码层级上根据id直接去相应的子表进行查询。
- 缓解数据库的压力(分库)
- 单一数据库实例可以支持的连接数是有限的
- 分散到了多个节点,不再局限于一台服务器,可以利用更多的网络等资源。
- 提升存储的容量(分库)
- 分散到了多个节点,不再局限于一台服务器,可以利用更多的存储资源。
- 提升数据的访问速度(分表)
- 缺点
- 提高了代码、数据库设计的复杂度
- 使用场景
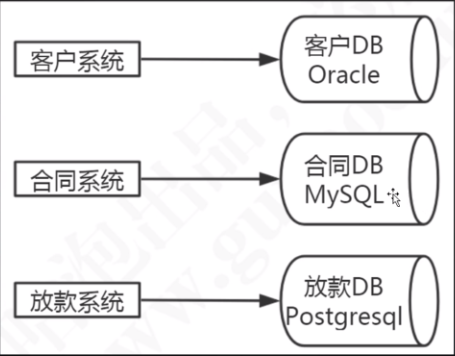
- 分库多结合子系统/服务的拆分,主要目的是业务隔离
- 分表多用于单表数据量特别大的情况,有阿里的文档推荐500万行以上再分表,也有人说如果数据库字段不多表设计合理的话,5000万行也可以。这要结合实际场景和性能测试的结果来看。千万不要做过度过早设计,会提高系统、设计的复杂度。
- 系统架构的演变
- 应用系统单体架构 + 数据库单体架构:应用代码混杂,难以排查问题,个别模块的瓶颈会导致整个系统的扩容等。
- 应用系统多系统架构(子系统、微服务等)+ 数据库单体架构:数据库中表太多,性能、存储都比较差,而且互相影响。
- 应用系统多系统架构(子系统、微服务等)+ 数据库按应用分库架构:单张表仍可能数据量过大。
- 应用系统多系统架构(子系统、微服务等)+ 数据库按应用分库再分表架构:比较合适。
- 应用系统单体架构 + 数据库单体架构:应用代码混杂,难以排查问题,个别模块的瓶颈会导致整个系统的扩容等。
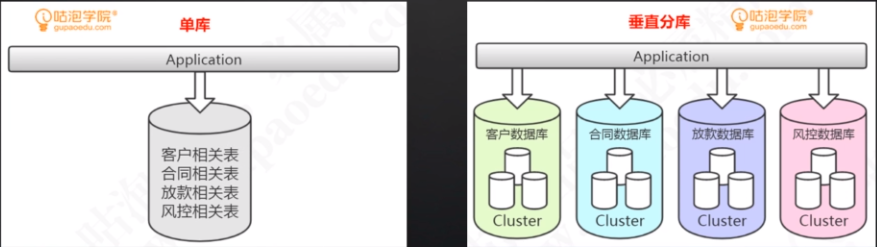
- 分表
- 垂直切分
- 按列切分
- 分为单库切分(一张表切成一个库中的多张表)、多库垂直切分(一张表切成多个库中的多张表)。
- 可能带来的问题
- 联表查询
- 字段冗余(把经常关联的字段也放到自己的表中)
- 数据同步(通过ETL等把别的库的数据同步过来)
- 广播表/同步表(所有的库中都放一份相同的重要数据,比如行名行号表)
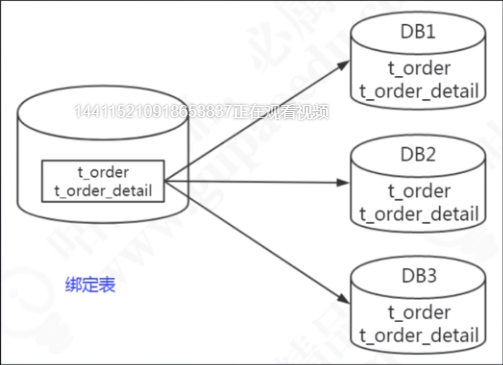
- 绑定表/ER表(对于有外键关系的父子表,将相关联的不同表的数据放到同一个库中)
- 系统级组装(如果前面的办法都不行,那只能在代码中通过接口或者数据库连接分别读取数据再连接了)
- 分布式事务
- 不同的库中无法使用本地事务,那么只能使用一些现成开源你框架了,如Atomikos、LCN、阿里刚开源的Seata(GTS的社区版)
- 联表查询
- 水平切分
- 按行切分,数据结构不变
- 可能带来的问题
- 联表查询
- 分页查询
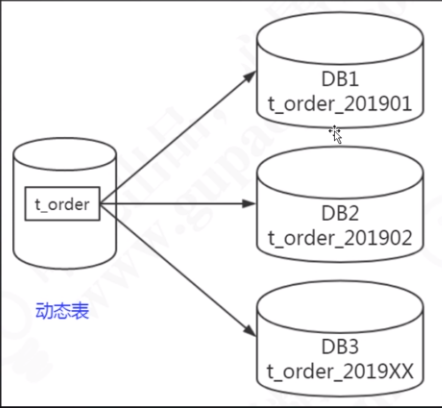
- 全局ID(auto increment等自增字段会导致id重复)
- 拆分规则的选择(难点)
- 根据业务需求合理选择,比如按时间切分交易数据,就要考虑到热点数据的问题。
- 目标
- 均匀
- 查询方便
- 扩容
- 迁移简单
- 方案
- 连续分片
- 随机分片
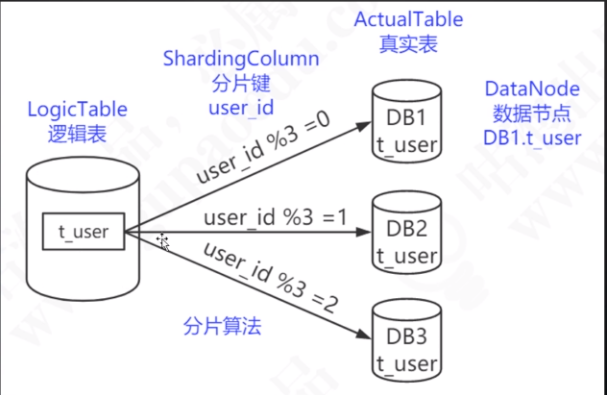
- 取模(绝对均匀,ID%3,根据余数即分到了三张表)
- 基于范围(比如每500W条数据一张表)
- 枚举(根据某个枚举字段来判断存到哪里,如性别、地域)
- 哈希
- 一致性哈希(基于哈希环,避免了数据增减时导致的重新分布问题?)
- 垂直切分
- 分库分表后,程序如何访问数据库
- 程序中如何动态选择、切换数据源
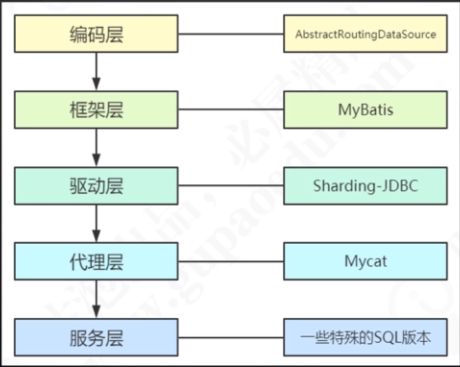
- 编码层的方案
- 代码中每个访问数据库的地方都要写if-else,比较臃肿,不太推荐
- 框架层的方案
- 可以考虑,之前titan项目好像就是用的这个。
- ORM这一层,用拦截器拦截sql,然后动态选择数据源。
- 驱动层的方案
- 比较推荐。
- 对代码来说,分库分表是透明的
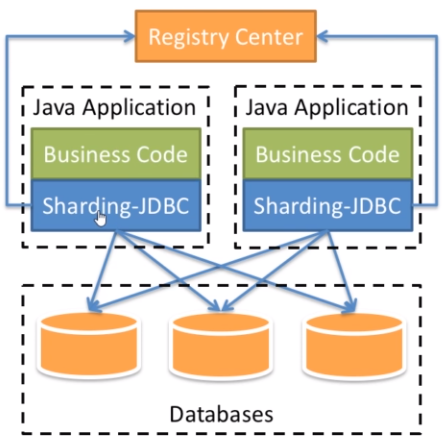
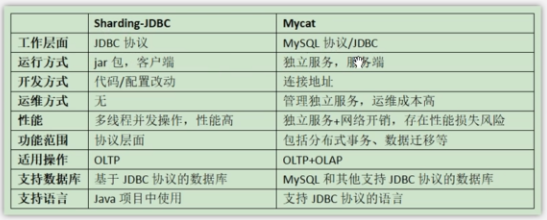
- 比如Sharding-JDBC,来自当当网,是一个增强的JDBC驱动,作为客户端直连数据库,以jar包形式提供服务。
- 推测的实现/处理过程
- SQL解析
- 执行器优化
- SQL路由
- SQL改写
- SQL执行
- 结果归并

- 推测的实现/处理过程
- 代理层的方案
- 把分库分表的功能剥离出来做成一个服务,实现数据库的协议来访问数据库,看起来就像一个数据库一样,比如实现mysql的协议
- 如Mycat
- 服务层的方案
- 一些特殊的数据库DBMS本身就提供分库分表的访问功能
- Spring Boot继承ShardingJDBC
- 配置方式
- 可以使用Java config来配置数据源、分片规则(不利于维护)
- 可以使用yaml文件来定义分片规则
- 可以使用application.properties文件配置数据源、分片规则
- 可以使用传统的xml文件配置数据源、分片规则
- 仍然像传统数据源那样使用Mybatis Generator来生成mapper、model、service等类
- 数据源配置会有所不同,比如要配置分库策略、分表策略、绑定表(父子表)的相关配置、全局表的相关配置
- 配置方式

参考:
数据库分库分表思路
关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力都有限。当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。此时就要考虑对其进行切分了,切分的目的就在于减少数据库的负担,缩短查询时间。
数据库分布式核心内容无非就是数据切分(Sharding),以及切分后对数据的定位、整合。数据切分就是将数据分散存储到多个数据库中,使得单一数据库中的数据量变小,通过扩充主机的数量缓解单一数据库的性能问题,从而达到提升数据库操作性能的目的。
分库分表会带来事务一致性、跨库跨表连接、跨库跨表分页排序、全局主键避重、数据迁移和扩容等问题。
- 什么时候考虑分库分表
- 能不切分尽量不要切分
- 数据量过大致正常运维影响业务访问时
- 数据量快速增长时
- 先考虑单库拆分,再考虑多库拆分(分布式)
- 字段垂直切分倒可以早点考虑
- 单库的表拆分也可以早点考虑
1. 性能优化首先考虑的是:
1.1. 表结构
1.2 .索引
1.3. 从库(只读)
2. 以上无法满足时,数据量过大,查询维度过多时再考虑数据切分:
2.1. 垂直分库(根据业务拆库)
根据业务耦合性,将关联度低的不同表存储在不同的数据库。
垂直分库可以解决部分大哥数据库存储空间过大、业务混杂的问题。
但总数据量还是那么大,行数还是那么大,只是单个库变小了。
2.2. 垂直分表(根据业务字段拆表)
基于数据库中的"列"进行,某个表字段较多,可以新建一张扩展表,将不经常用或字段长度较大的字段拆分出去到扩展表中。
也没有减小单个库过大或行数过多的存储问题,但提高了性能,命中率更高。
2.3. 水平分库、分表
- 根据数值范围
优点:
单表大小可控
天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移
使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。
缺点:
热点数据成为性能瓶颈。连续分片可能存在数据热点,例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
- 根据数值取模(即根据余数,一般采用hash取模mod的切分方式)
优点:
数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈
缺点:
后期分片集群扩容时,需要迁移旧的数据(使用一致性hash算法能较好的避免这个问题)???
容易面临跨分片查询的复杂问题。比如上例中,如果频繁用到的查询条件中不带cusno时,将会导致无法定位数据库,从而需要同时向4个库发起查询,再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。
垂直切分的优点:
解决业务系统层面的耦合,业务清晰
与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等
高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈
缺点:
部分表无法join,只能通过接口聚合方式解决,提升了开发的复杂度
分布式事务处理复杂
依然存在单表数据量过大的问题(需要水平切分)
水平切分的优点:
不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
应用端改造较小,不需要拆分业务模块
缺点:
跨分片的事务一致性难以保证
跨库的join关联查询性能较差
数据多次扩展难度和维护量极大


