
文本多分类和多标签分类的差别
大纲:
1、介绍
2、数据标注,数据输入格式
3、3种文本多标签分类的方法
4、损失函数、概率、预测结果
一、文本分类介绍
首先,我介绍下文本多分类和文本多标签分类的的区别。
1、Multi-Class:多分类/多元分类(二分类、三分类、多分类等)
- 二分类:判断邮件属于哪个类别,垃圾或者非垃圾
- 多分类:判断新闻属于哪个类别,如财经、体育、娱乐等
2、Multi-Label:多标签分类
- 文本可能同时涉及政治,金融、教育、体育中多种,也可能不属于任何一种。
- 电影可以根据其摘要内容分为动作,喜剧和浪漫类型。有可能电影属于 [浪漫与喜剧]等多种类型。
3、二者区别
- 多分类任务中一条数据只有一个标签,但这个标签可能有多种类别。比如判定某个人的性别,只能归类为"男性"、"女性"其中一个。再比如判断一个文本的情感只能归类为"正面"、"中面"或者"负面"其中一个。
- 多标签分类任务中一条数据可能有多个标签,每个标签可能有两个或者多个类别(一般两个)。例如,一篇新闻可能同时归类为"娱乐"和"运动",也可能只属于"娱乐"或者其它类别。
二、输入数据格式
1、标注数据格式
Text, Label
多分类: 俄罗斯进攻乌克兰, 军事
多标签分类: 俄罗斯进攻乌克兰,美国宣布对俄制裁, 军事、政治
备注:这里标注数据格式简单举例,可根据实际数据自定义,只要后面统一转换到模型网络输入即可。
2、输入数据格式
例子:假设个人爱好的集合一共有6个元素:运动、旅游、读书、工作、睡觉、美食
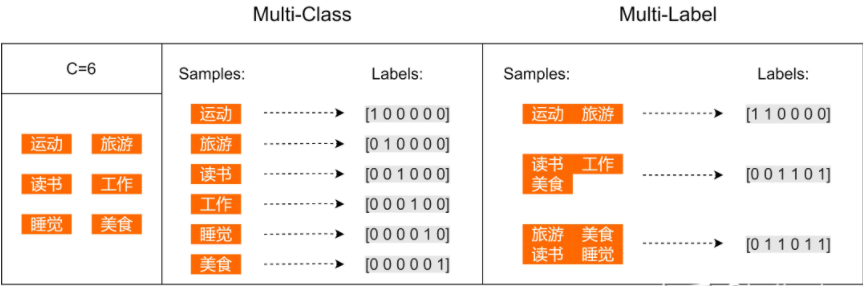
三、3种文本多标签分类的方法
1、改变输出概率(probabilities)的计算方式和交叉熵的计算方式
- tf.nn.sigmoid_cross_entropy_with_logits测量离散分类任务中的概率误差,其中每个类是独立的而不是互斥的。这适用于多标签分类问题。
- tf.nn.softmax_cross_entropy_with_logits测量离散分类任务中的概率误差,其中类之间是互斥的(每个条目恰好在一个类中)。这适用多分类问题。
- 在简单的二进制分类中,sigmoid和softmax没有太大的区别,但是在多分类的情况下,sigmoid允许处理非独占标签(也称为多标签),而softmax处理独占类。

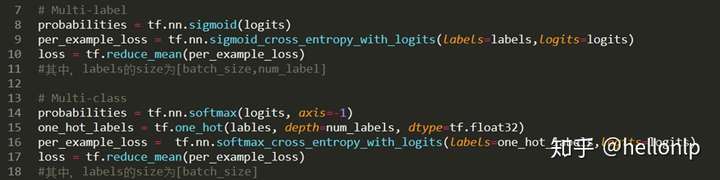
比较直接的在最后加上一层全连接,全连接层的作用是将output_layer投射到我们的标签上面。在计算概率的时候用sigmod计算,即将每一个标签当做一个二分类问题,loss函数则为sigmoid_cross_entropy_with_logits()。
2、改变输出的全连接层。
- 在输出层设置多个全连接层,每一个全连接层对应一个标签。
- 损失函数为所有标签损失函数的平均值。
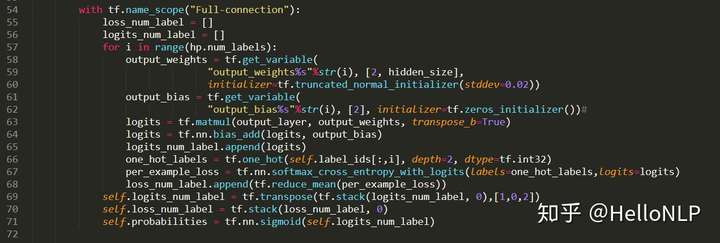
在网络的最后一层,针对每一个标签,使用一个全连接层,然后在每个标签上就是一个二分类问题,这个其实跟第一种方式很像,只是第一种方法中,每个标签公用了最后一层全连接层。
3、使用框架:Attention + seq2seq(Beam Search)
- 上下文语义信息 -> 多标签之间的关系。多标签一般去看下并非独立。
- 将多标签当作一个序列(类似一句话)。

Attention 结构图
第三种方式就是,将任务当做是一个标签生成的过程,那这样就可以使用一个seq2seq的框架来完成了。前面使用一个encoder结构来对输入的特征数据编码, 然后在经过decoder进行解码最终生成多个标签,这个就跟机器翻译是一个思路,所以在最终生成标签的时候,会有标签的依赖关系。
四、损失函数、概率、预测结果
- tf.nn.sigmoid_cross_entropy_with_logits测量离散分类任务中的概率误差,其中每个类是独立的而不是互斥的。这适用于多标签分类问题。
- tf.nn.softmax_cross_entropy_with_logits测量离散分类任务中的概率误差,其中类之间是互斥的(每个条目恰好在一个类中)。这适用多分类问题。样本标签为[1,0,0] , [0,1,0], [0,0,1]时。
- tf.nn.sparse_cross_entropy_with_logits测量离散分类任务中的概率误差,其中类之间是互斥的(每个条目恰好在一个类中)。这适用多分类问题。样本标签为[1,2,3]时。
- 在简单的二进制分类中,sigmoid和softmax没有太大的区别,但是在多分类的情况下,sigmoid允许处理非独占标签(也称为多标签),而softmax处理独占类。
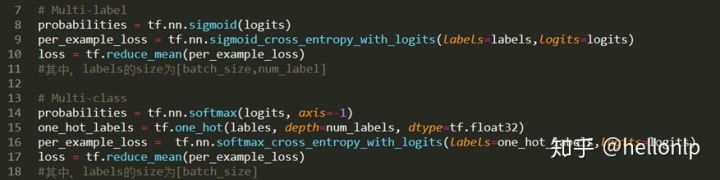
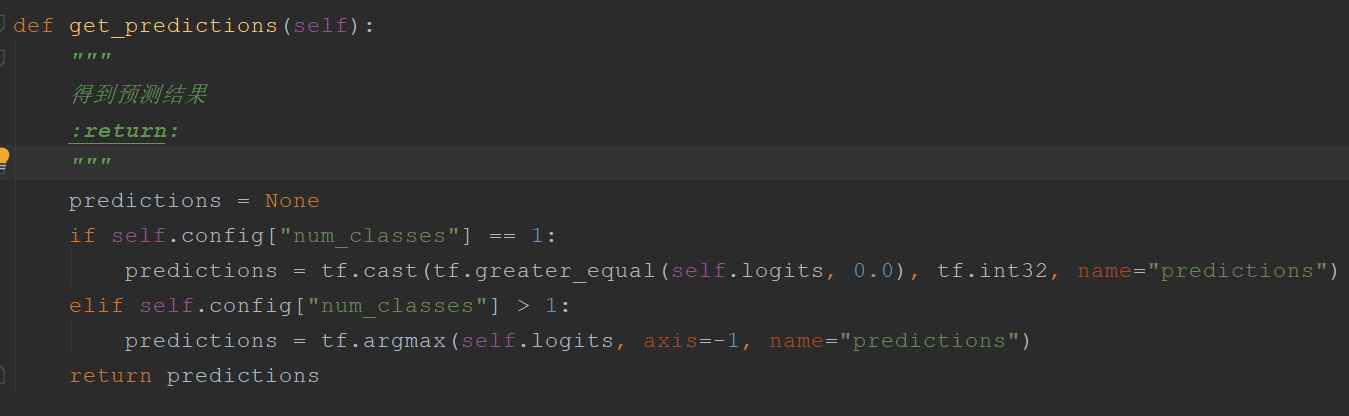
在文本多分类中,label_ids的维度为(batch_size);在多标签文本分类中,它的维度为(batch_size,num_labels)。这样做的原因:
- 在文本多分类中,最后得到的标签只有一个,并且必须是其中的一个。
- 在多标签文本分类中,最后得到的标签可能有1个或者多个。
一般的多分类是通过tf.argmax(logits)实现,返回的是最大的那个数值所在的label_id,因为logits对应每一个label_id都有一个概率。但是,在多标签分类中,我们需要得到的是每一个标签是否可以作为输出标签,所以每一个标签可以作为输出标签的概率都会量化为一个0到1之间的值。所以当某一个标签对应输出概率小于0.5时,我们认为它不能作为当前句子的输出标签;反之,如果大于等于0.5,那么它代表了当前句子的输出标签之一。
五、总结
|
分类问题名称 |
输出层使用激活函数 |
对应的损失函数 |
|
二分类 |
sigmoid函数 |
sigmoid_cross_entropy_with_logits() |
|
多分类 |
softmax函数 |
softmax_cross_entropy_with_logits() |
|
多标签分类 |
sigmoid函数 |
sigmoid_cross_entropy_with_logits() |
参考文章:
https://zhuanlan.zhihu.com/p/152140983?utm_source=wechat_session
https://blog.csdn.net/u011412768/article/details/109082838 输出举例
https://zhuanlan.zhihu.com/p/385475273 评估指标
https://zhuanlan.zhihu.com/p/372402161 概率分布的交叉熵

 浙公网安备 33010602011771号
浙公网安备 33010602011771号