
[python] python 读写Oracle clob类型数据的处理
clob字段是oracle专门用于存储超长字符串的字段类型,一般varchar2只能存4000个字符串,超过4000个就存不下去了。
如果直接使用 pandas.read_sql(sql, conn)会报错,那么如何将clob读取到python中呢?
1.read方法
import cx_Oracle conn = cx_Oracle.connect("user/pwd@ip/db") cur = conn.cursor() # col 是clob字段 cur.execute("select col from table") pram=[] for i in cur: text = i[0].read() pram.appen(text) cur.close() conn.close()
2.使用DBMS_LOB.SUBSTR模块
方法是先提取前2000个字符串,接着提取2000个字符串….,然后拼接起来。
import cx_Oracle import pandas as pd conn = cx_Oracle.connect("user/pwd@ip/db") # 这里只提取前6000个字符串 sql1 = "select DBMS_LOB.SUBSTR(col,2000,1) as col1 as fzss from table" # 1-2000个字符串 sql2 = "select DBMS_LOB.SUBSTR(col,4000,2001) as col2 as fzss from table" # 2001-4000个字符串 sql3 = "select DBMS_LOB.SUBSTR(col,6000,4001) as col3 as fzss from table" # 2001-4000个字符串 # 读取数据 df1 = pd.read_sql(sql1, conn) df2 = pd.read_sql(sql2, conn) df3 = pd.read_sql(sql3, conn) # 有些记录不一定是很长的字符串,结果可能是None,需要填充空字符串,否则下面的拼接会出错 df1 = df1.fillna('') df2 = df2.fillna('') df3 = df3.fillna('') # 将它们拼接起来,放在tmp字段上 df1['TMP'] = df1.loc['COL1']+df2.loc['COL2']+df3.loc['COL3']
3.将字符串写入clob字段
方法和将字符串导入varchar2字段是一样的,不需要特殊设置。 比如:
id='123' clob='a'*2**20 # 重复2的20次方次 param=[id, colb] sql = "insert into table (id,colb) values(:1, :2)" cursor.execute(sql, param) conn.commit()
LOB variable no longer valid after subsequent fetch 的解决办法:
将cx_Oracle.LOB数据转换为python中的字符串:
3条原则:
1、读取数据时不要使用cursor.fetchall()。(这个有人用可以,有的不可以,具体不知道为什么,大家都试下)。
2、cx_Oracle的版本要在6或以上,不要用5, 5会有有问题。
3、要对execute到的cursor做循环遍历,然后对LOB的object进行read()。转换成字符串可以加str(LOB.read())。
cx_Oracle.LOB object有个read方法,我们只要先遍历cx_Oracle.LOB object,然后对每个元素使用read即可正常查看字符类型的原数据。
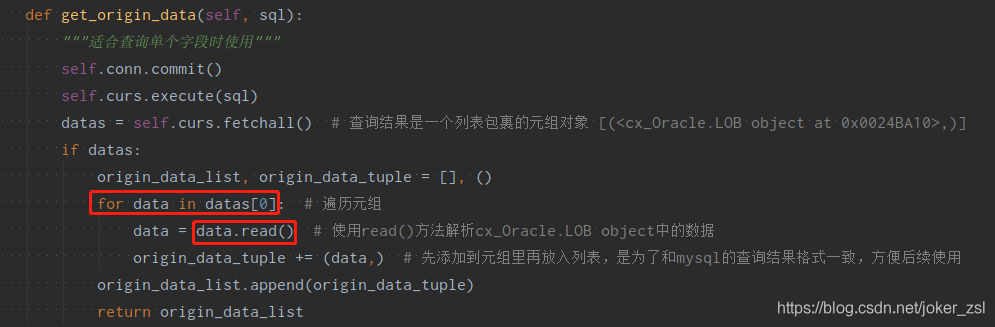
上图转载自:https://blog.csdn.net/joker_zsl/article/details/110531353

 浙公网安备 33010602011771号
浙公网安备 33010602011771号