

(五)Flink Table API 编程
首先:flink根据使用的便捷性提供了三种API,自下而上是:
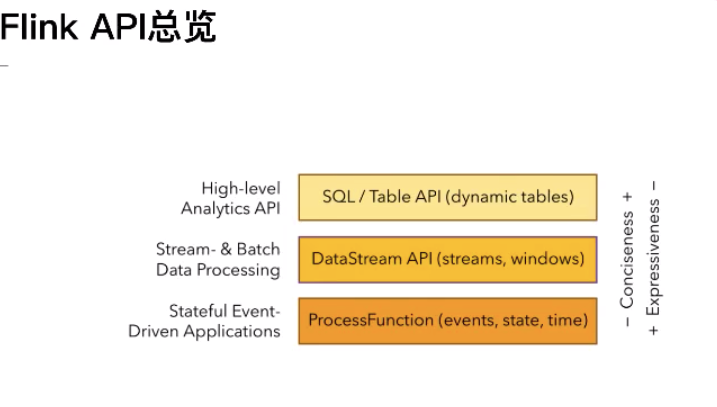
Table API & SQL
1、声明行:用户只关心做什么,不用关心怎么做
2、高性能:支持性能优化,可以获取更好的执行性能
3、流批统一:相同的统计逻辑,既可以流模式运行,也可以批模式运行
4、性能稳定:语义遵循SQL标准,不易变动
5、易理解:语义明确,所见即所得
Table API:tab.groupBy("word").select("word,count(1) as count")
SQL:SELECT word,COUNT(*) as cnt FROM MyTable GROUP BY word
Table API 特点:
1、Table API使得多声明的数据处理起来比较容易
例如:我们把a大于10的数据存xxx的外部表,同时需要把a小于10的数据插入到外部表yyy,我们是使用TableAPI很方便。
Table.filter(a>10).insertInto("xxx")
Table.filter(a<10).insertInto("yyy")
2、TableAPI使得扩展标准SQL更容易(当且仅当需要的时候)
Table API 编程:
1、WordCount示例:
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.TableEnvironment; import org.apache.flink.table.api.java.StreamTableEnvironment; import org.apache.flink.table.descriptors.FileSystem; import org.apache.flink.table.descriptors.OldCsv; import org.apache.flink.table.descriptors.Schema; import org.apache.flink.types.Row; public class JavaStreamWordCount { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tEnv = TableEnvironment.getTableEnvironment(env); String path = JavaStreamWordCount.class.getClassLoader().getResource("words.txt").getPath(); tEnv.connect(new FileSystem().path(path)) .withFormat(new OldCsv().field("word", Types.STRING).lineDelimiter("\n")) .withSchema(new Schema().field("word", Types.STRING)) .inAppendMode() .registerTableSource("fileSource"); Table result = tEnv.scan("fileSource") .groupBy("word") .select("word, count(1) as count"); tEnv.toRetractStream(result, Row.class).print(); env.execute(); } }
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.TableEnvironment; import org.apache.flink.table.api.java.StreamTableEnvironment; import org.apache.flink.table.descriptors.FileSystem; import org.apache.flink.table.descriptors.OldCsv; import org.apache.flink.table.descriptors.Schema; import org.apache.flink.types.Row; public class JavaStreamWordCount { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tEnv = TableEnvironment.getTableEnvironment(env); String path = JavaStreamWordCount.class.getClassLoader().getResource("words.txt").getPath(); tEnv.connect(new FileSystem().path(path)) .withFormat(new OldCsv().field("word", Types.STRING).lineDelimiter("\n")) .withSchema(new Schema().field("word", Types.STRING)) .inAppendMode() .registerTableSource("fileSource"); Table result = tEnv.scan("fileSource") .groupBy("word") .select("word, count(1) as count"); tEnv.toRetractStream(result, Row.class).print(); env.execute(); } }
import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.java.BatchTableEnvironment; import org.apache.flink.table.descriptors.FileSystem; import org.apache.flink.table.descriptors.OldCsv; import org.apache.flink.table.descriptors.Schema; import org.apache.flink.types.Row; public class JavaBatchWordCount { public static void main(String[] args) throws Exception { ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); BatchTableEnvironment tEnv = BatchTableEnvironment.create(env); String path = JavaBatchWordCount.class.getClassLoader().getResource("words.txt").getPath(); tEnv.connect(new FileSystem().path(path)) .withFormat(new OldCsv().field("word", Types.STRING).lineDelimiter("\n")) .withSchema(new Schema().field("word", Types.STRING)) .registerTableSource("fileSource"); Table result = tEnv.scan("fileSource") .groupBy("word") .select("word, count(1) as count"); tEnv.toDataSet(result, Row.class).print(); } }
参考:https://github.com/hequn8128/TableApiDemo

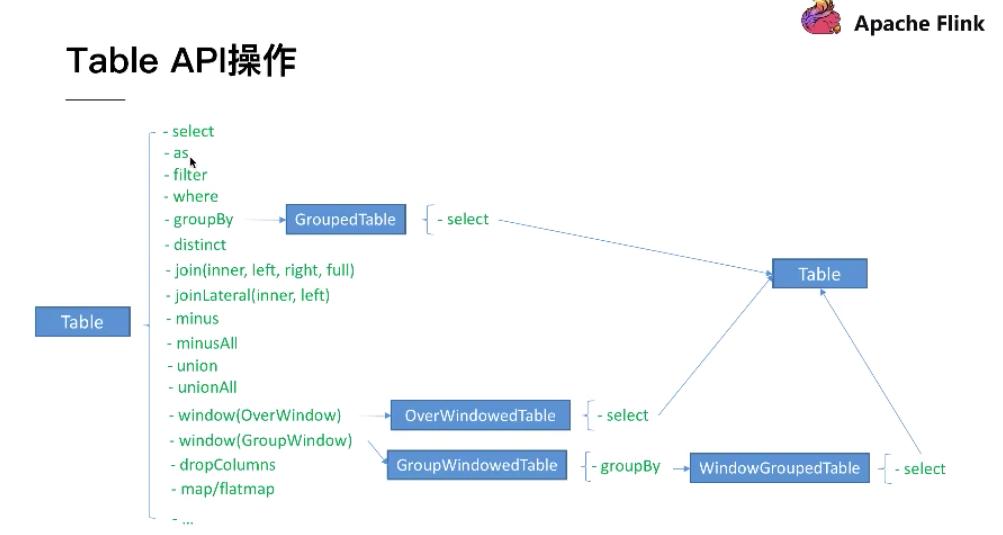
2、TableAPI操作
(1)how to get a Table
Table myTable = tableExnvironment.scan("MyTable"); //Table 是从tableExnvironment中scan出来的,那么MyTable是如果注册呢,即:How to register a table??大致又三种:

(2)how to emit a Table

(3) how to query a Table
3、 Columns Operation & Function




4、 Row-based Operation




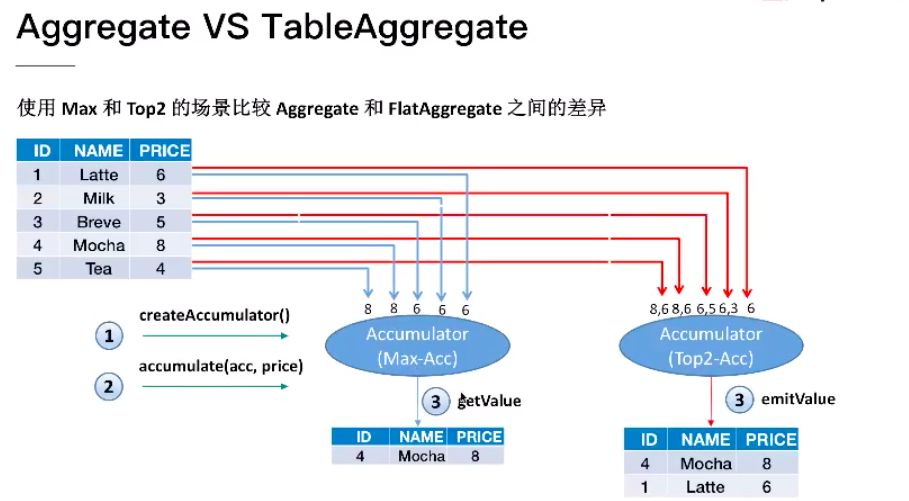
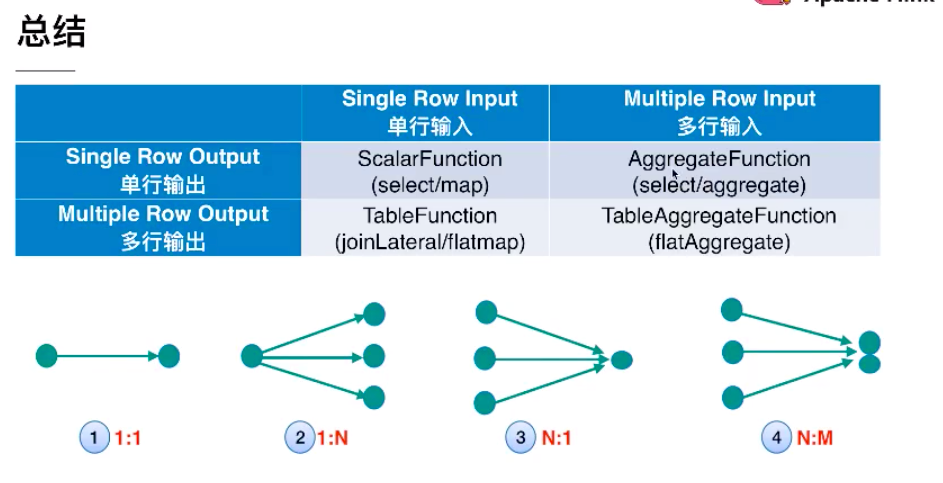
Table SQL 编程:
1、如何在流上运行SQL查询
参考:https://github.com/ververica/sql-training
2、如何使用SQL CLI客户端
3、执行window aggregate 和non-window aggregate,并理解其区别
4、如何用SQL消费Kafka数据
5、如何用SQL将结果写入Kafka和ElasticSearch
还有......更过会在1.9支持,敬请关注
