
hadoop的wordcount程序
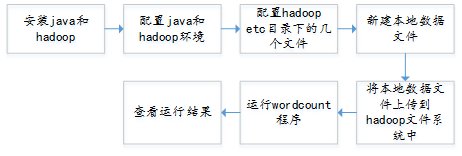
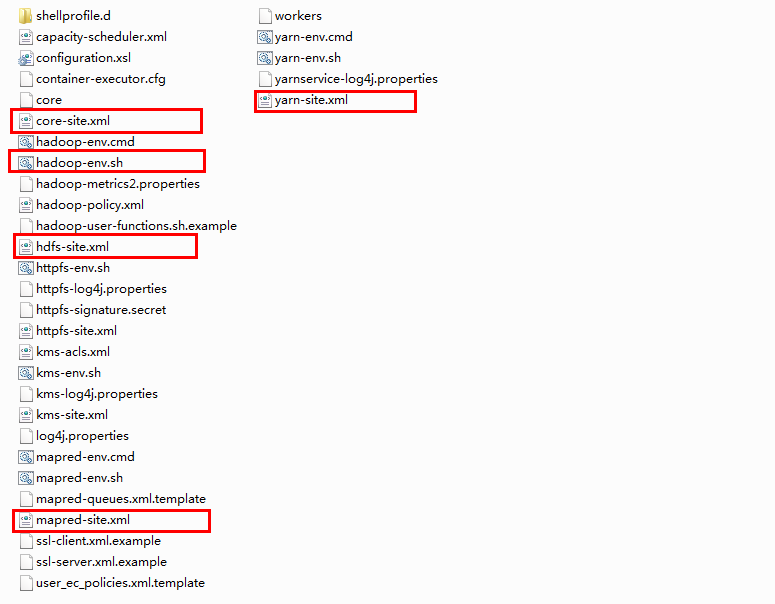
首先需要配置上面画红框的几个文件
1、core-site.xml文件
1 <configuration> 2 <property> 3 <name>fs.defaultFS</name> 4 <value>hdfs://localhost:9000</value> 5 </property> 6 7 <property> 8 <name>hadoop.tmp.dir</name> 9 <value>/soft/hadoop-3.1.1/data</value> 10 </property> 11 12 </configuration>
2、hdfs-site.xml文件
1 <configuration> 2 <property> 3 <name>dfs.namenode.http-address</name> 4 <value>localhost:50070</value> 5 </property> 6 7 8 <property> 9 <name>dfs.replication</name> 10 <value>1</value> 11 </property> 12 </configuration>
3、yarn-stie.xml文件
1 <property> 2 <name>yarn.resourcemanager.hostname</name> 3 <value>localhost</value> 4 </property> 5 6 <property> 7 <name>yarn.nodemanager.aux-services</name> 8 <value>mapreduce_shuffle</value> 9 </property> 10 11 <property> 12 <name>mapreduce.framework.name</name> 13 <value>local</value> 14 </property> 15 </configuration>
4、mapred-site.xml文件
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 </property>
5、hadoop-env.sh文件
1 # 这个地方设置为你java的安装目录 2 JAVA_HOME=/soft/jdk1.8.0_191

二、启动hadoop运行环境
2.1 首先初始化一下hadoop文件系统
1 hadoop namenode format
2.2 运行hadoop
1 start-all.sh
我们这里需要确认一下是否运行成功,使用下面的命令
jps

这里尤其要注意一下这个DataNode是否运行
成功运行以后,应该可以在浏览器输入下面两个网址


3 测试wordcount程序
3.1 首先在本地随便新建一个input.txt文件,input.txt文件中随便输入一些单词
hello world
hello world
hello boy
hello gril
hello
hello
hello
hello
hello
3.2 在hadoop根文件系统中,新建一个文件夹
1 hadoop fs -mkdir /wordcount
3.3 将本地的input.txt文件上传到hadoop文件中
1 hadoop fs -put input.txt /wordcount/input
3.4 运行hadoop提供wordcount程序
hadoop提供许多测试程序,具体在hadoop安装目录的share目录下
hadoop jar /soft/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /wordcount/input /output/wordcount
上面的/out/wordcount表示输出文件的位置
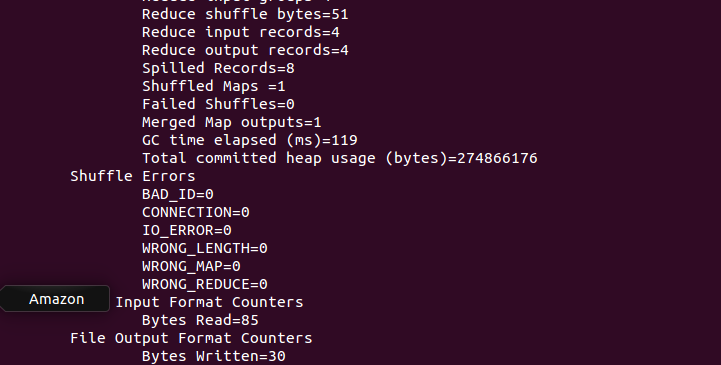
3.5 查看运行的结果
1 hadoop fs -cat /wordcount/part-r-00000
1 boy 2 2 girl 2 3 hello 10 4 world 1
积沙成塔

