
Java泛型理解
java泛型
通俗的讲,泛型就是操作类型的占位符
一、通常泛型的写法
1.1定义泛型类
|
public class ApiResult<T>{ int resultCode; String resultMsg; T resultObject; } |
1.2定义泛型方法
|
public JsonUtil{ public <T> T str2Json(String jsonText, Class target){ T result = null; ...
return result; } } |
1.3 K,V类型
|
public class ResultMap<K,V>{ private K key; private V value;
// 省略set,get方法
public void put(K key, V value){ this.key = key; this.value = value; } } |
二、使用泛型类和方法
|
ApiResult<User> result = new ApiResult<User>(); result.setResultCode(0); result.setResultMsg("success"); result.setResultObject(new User());
String userJsonText = "userJsonText"; User u = JsonUtil.str2Json(jsonText, User.class); |
|
ResultMap<String,User> resultMap = new ResultMap<String,User>(); resultMap.put("currentUserKey", new User()); |
三、类型擦除
|
public class Operate{ public static void main(String[] args){ List<String> names = new ArrayList<String>(); names.add("Jack"); names.add("Tom"); for(String name:names){ System.out.println(name); } } } |
其对应的class文件反汇编以后,我们使用java-gui反编译.exe 查看编译之后的代码如下:
发现没有,根本没有<String> 这一部分了。这个限制为String类型的泛型被“擦除”了。写代码的时候,泛型会做校验,类型不对应的,无法add,但是编译之后边去掉了泛型类型。
四、为什么要使用java泛型??
这里的泛型就相当于“约法三章”,先给你定好“规矩”,我这个List<String> 就是用来操作String类型的,你插入Person对象就不行。说白了就是为了类型安全。所以其好处有:
4.1类型安全:
通过知道使用泛型定义的变量的类型限制,编译器可以在一个高得多的程度上验证类型假设。没有泛型,这些假设就只存在于程序员的头脑中(或者如果幸运的话,还存在于代码注释中)。
4.2消除强制类型转换
|
//该代码不使用泛型: List li = new ArrayList(); li.put(new Integer(3)); Integer i = (Integer) li.get(0);
//该代码使用泛型: List<Integer> li = new ArrayList<Integer>(); li.put(new Integer(3)); Integer i = li.get(0); |
|
public class Fruit {
} |
|
public class Apple extends Fruit {
} |
|
public class Plate<T> { private T item; public Plate(T t){ item = t; } public T getItem() { return item; } public void setItem(T item) { this.item = item; }
} |
|
public class TestGenericParadigm {
public static void main(String[] args){
Plate<Fruit> p = new Plate<Apple>(new Apple()); // 编译不通过 Plate<Fruit> p = new Plate<Fruit>(new Fruit()); } } |
为什么上面这个会出现编译不通过??
解释:苹果是水果,但是装苹果的盘子不是装水果的盘子
所以,就算容器里装的东西之间有继承关系,但容器之间是没有继承关系的
为了让泛型用起来更舒服,Sun的大脑袋们就想出了<? extends T>和<? super T>的办法,来让”水果盘子“和”苹果盘子“之间发生关系
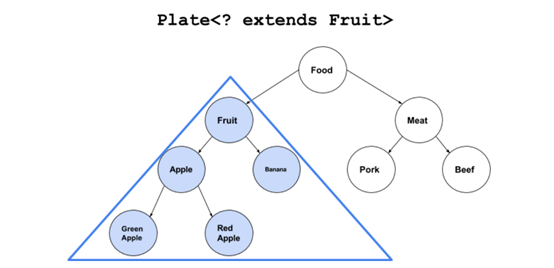
什么是上界?
|
Plate<? extends Fruit> |
翻译成人话就是:一个能放水果以及一切是水果派生类的盘子。再直白点就是:啥水果都能放的盘子。这和我们人类的逻辑就比较接近了。Plate<? extends Fruit>和Plate<Apple>最大的区别就是:Plate<? extends Fruit>是Plate<Fruit>以及Plate<Apple>的基类。直接的好处就是,我们可以用“苹果盘子”给“水果盘子”赋值了。
Plate<? extends Fruit> p=new Plate<Apple>(new Apple());
如果把Fruit和Apple的例子再扩展一下
|
//Lev 1 class Food{}
//Lev 2 class Fruit extends Food{} class Meat extends Food{}
//Lev 3 class Apple extends Fruit{} class Banana extends Fruit{} class Pork extends Meat{} class Beef extends Meat{}
//Lev 4 class RedApple extends Apple{} class GreenApple extends Apple{} |
在这个体系中,上界通配符 Plate<? extends Fruit> 覆盖下图中蓝色的区域
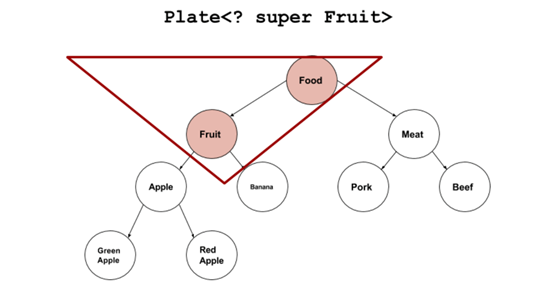
什么是下界?
|
Plate<? super Fruit> |
表达的就是相反的概念:一个能放水果以及一切是水果基类的盘子。Plate<? super Fruit>是Plate<Fruit>的基类,但不是Plate<Apple>的基类。对应刚才那个例子,Plate<? super Fruit>覆盖下图中红色的区域。
上下界通配符的副作用
边界让Java不同泛型之间的转换更容易了。但不要忘记,这样的转换也有一定的副作用。那就是容器的部分功能可能失效。
还是以刚才的Plate为例。我们可以对盘子做两件事,往盘子里set()新东西,以及从盘子里get()东西。
|
public class TestGenericParadigm {
public static void main(String[] args){ /* * 上界通配符 * 不能存入任何元素 * 读出来的东西只能放在Fruit或它的基类中 */
Plate<? extends Fruit> p = new Plate<Apple>(new Apple());
p.setItem(new Fruit()); //Error p.setItem(new Apple()); //Error
Fruit newFruit1 = p.getItem(); Object newFruit2 = p.getItem(); Apple new Fruit3 = p.getItem();//Error
} } |
原因是编译器只知道容器内是Fruit或者它的派生类,但具体是什么类型不知道
所以通配符<?>和类型参数的区别就在于,对编译器来说所有的T都代表同一种类型。比如下面这个泛型方法里,三个T都指代同一个类型,要么都是String,要么都是Integer。
但通配符<?>没有这种约束,Plate<?>单纯的就表示:盘子里放了一个东西,是什么我不知道
下界<? super T>不影响往里存,但往外取只能放在Object对象里
使用下界<? super Fruit>会使从盘子里取东西的get( )方法部分失效,只能存放到Object对象里。set( )方法正常。
|
/* * 下界通配符 * 存入元素正常 * 读取的东西只能存放在Object中 */ Plate<? super Fruit> p1 = new Plate<Fruit>(new Fruit());
p1.setItem(new Fruit()); p1.setItem(new Apple());
Apple newFruit4 = p1.getItem();//Error Fruit newFruit5 = p1.getItem();//Error Object newFruit6 = p1.getItem(); |
因为下界规定了元素的最小粒度的下限,实际上是放松了容器元素的类型控制。既然元素是Fruit的基类,那往里存粒度比Fruit小的都可以。但往外读取元素就费劲了,只有所有类的基类Object对象才能装下。但这样的话,元素的类型信息就全部丢失
PECS原则
最后看一下什么是PECS(Producer Extends Consumer Super)原则,已经很好理解了:
频繁往外读取内容的,适合用上界Extends。
经常往里插入的,适合用下界Super。
