python 3.x 爬虫基础---http headers详解
python 3.x 爬虫基础
python 3.x 爬虫基础---http headers详解
python 3.x 爬虫基础---Requersts,BeautifulSoup4(bs4)
前言
上一篇文章 python 爬虫入门案例----爬取某站上海租房图片 中有对headers的讲解,可能是对爬虫了解的不够深刻,所以老觉得这是一项特别简单的技术,也可能是简单所以网上对爬虫系统的文档,书和视频感觉都好少,故此准备接下这段时间对爬虫涉及到的点做个系统的学习与总结。
利用浏览器查看headers
打开浏览器,按F12(开发调试工具)------》查看网络工作(Network)------》选择你访问的页面地址------》headers。就可以看到你想要的信息,如下图(【白眼】这些有点开发基础的应该都知道吧)
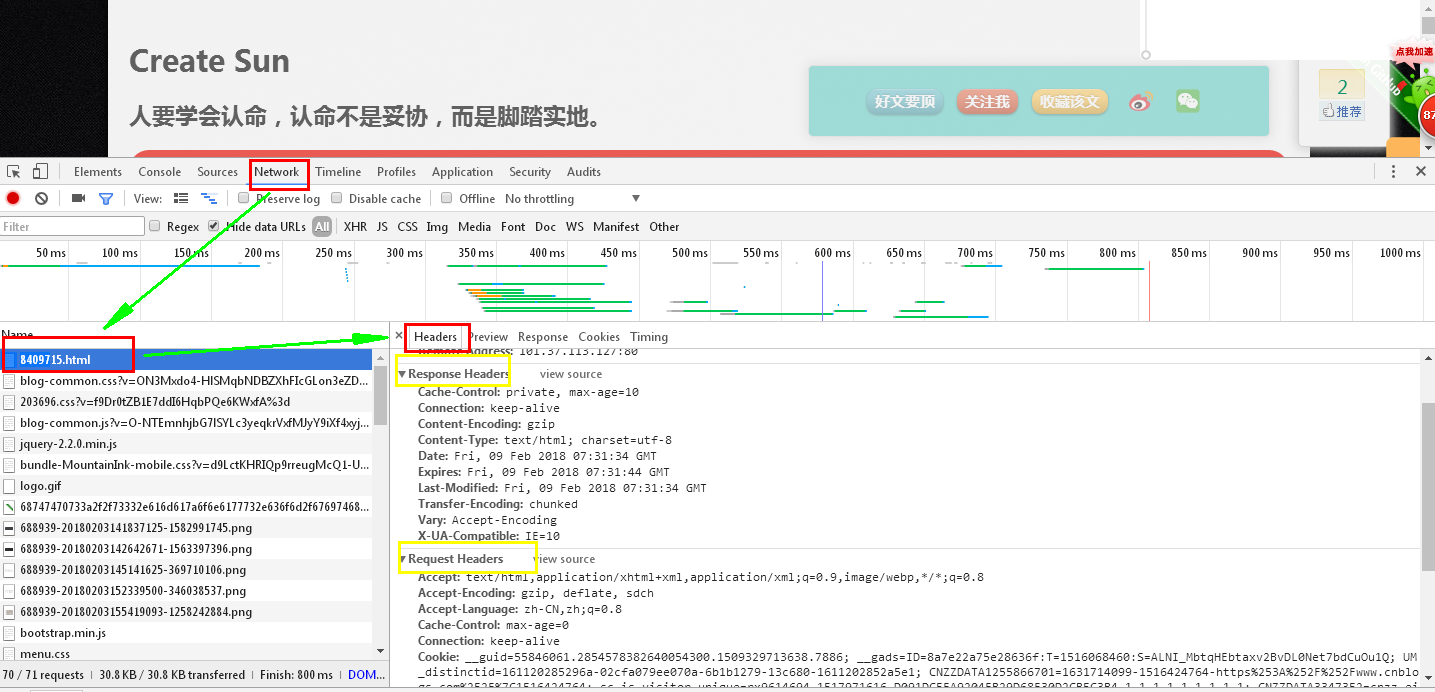
如图所示我们可以看出heades包含(通用)request headers(请求) 与response headers(响应)。从名字上我们大概就能知道它们相应的作用是什么吧。这一块知识可以去学习http 协议去了解,记得以前买过一本书叫做《图解http》,有兴趣的看一去看一下。
request headers
爬虫第一步应该就是要获取页面信息,但是那往往别人是不想让你爬它们的网站的至于为什么?请用脚指头想一想,其实我以前的项目也做过防止爬虫的功能,net mvc防网络攻击案例 ,那么存在压迫就会有反抗,其中反爬虫的方式headers的伪造就是第一步。其中我主要提一下Host,Connection,Accept,Accept-Encoding,Accept-Language,User-Agent,Referrer这7个请求头。
Host详解
大家应该知道host是在http1-1之后才有的,也就是以前没有host只存在ip网站也是能够正常运行的,但是为什要加入host的呢。

如上图我们去ping host。host:csblogs.com 对应的ip是104.27.132.253,那么我在这就要问了,有没有可能blogs.com也对应104.27.132.253这个ip地址?答案是肯定的,做过web开发的人员应该都在自己电脑上部署过多个web站点。只需要我们用不同的端口就行。是的host就是域名吗。他主要就是实现一对多的功能。一台虚拟主机上的一个ip可以放成千上万个网站。当对这些网站的请求到来时,服务器根据Host这一行中的值来确定本次请求的是哪个具体的网站,就是域名解析。
Connection详解
如下图有没有发现请求与相应都存在Connection,那么它到底有什么用呢?控制HTTP C/S直接是否可以进行长连接。HTTP1.1规定了默认保持长连接,但是python爬虫的时候有可能会出现短链接。那么什么是长连接?
数据传输完成了保持TCP连接不断开(不发RST包、不四次握手),等待在同域名下继续用这个通道传输数据;相反的就是短连接。

其中一下可以对其进行简单的设置,进行传递。
Connection: Keep-alive#长连接
Connection:close#短链接
Keep-Alive: timeout=20#tcp通道保持20s
Accept详解
指定客户端能够接受的内容类型,在这唯一要提醒的就是它只是建议服务器,而并非就是你写成什么他就返回给你什么。
Accept-Encoding详解
浏览器发给服务器,声明浏览器支持的编码类型的。
Accept-Encoding: compress, gzip //支持compress 和gzip类型 Accept-Encoding: //默认是identity Accept-Encoding: * //支持所有类型 Accept-Encoding: compress;q=0.5, gzip;q=1.0 //按顺序支持 gzip , compress Accept-Encoding: gzip;q=1.0, identity; q=0.5, *;q=0 // 按顺序支持 gzip , identity
Accept-Language详解
请求头允许客户端声明它可以理解的自然语言,以及优先选择的区域方言。
Accept-Language: Zh-CN, zh;q=0.8, en-gb;q=0.8, en;q=0.7#最佳语言为中文-中国(默认权重为1),其次为中文,权重为0.8,再次为英国英语,权重为0.8,最后为通用英语,权重0.7
user_agent详解
向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。通过这个标识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计;例如用手机访问谷歌和电脑访问是不一样的,这些是谷歌根据访问者的UA来判断的,这个应该所有接触爬虫不管不知道它什么意思都会用到它,因为如果没有它,大部分都会没反应。
#user_agent 集合 user_agent_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)', 'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1', 'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0', 'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1', ] #随机选择一个 user_agent = random.choice(user_agent_list) #传递给header #headers = { 'User-Agent': user_agent }
为什么要随机传递一个不行吗?其实大部分时候我都是用一个。其实就是你伪造的越不想爬虫就越是越好的爬虫。
Referer详解
当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。用于统计访问量、防外连接等。这个怎么说呢,就是你如果你想查看去看有没有火车票,那么你就要先登入12306网站。
# 对付“反盗链”(服务器会识别headers中的referer是不是它自己,如果不是则不响应),构建以下headers headers = { "User-Agent": "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)", "Referer": "https://www.cnblogs.com" }
其他
Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中;
Cookie:这是最重要的请求头信息之一;一般可以直接复制,对于一些变化的可以选择构造(python中的一些库也可以实现),详情请了解http.cookiejar,python 3.x 爬虫基础---Urllib详解有提及。
From:请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它;
If-Modified-Since:只有当所请求的内容在指定的日期之后又经过修改才返回它,否则返回304“Not Modified”应答;
Pragma:指定“no-cache”值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝;
UA-Pixels,UA-Color,UA-OS,UA-CPU:由某些版本的IE浏览器所发送的非标准的请求头,表示屏幕大小、颜色深度、操作系统和CPU类型。
Origin:Origin字段里只包含是谁发起的请求,并没有其他信息。跟Referer不一样的 是Origin字段并没有包含涉及到用户隐私的URL路径和请求内容,这个尤其重要。
并且Origin字段只存在于POST请求,而Referer则存在于所有类型的请求;
结语
那么就先写到这里了,上篇文章说春节前最后一篇,结果没压抑住,在这就祝大家新年快乐了。来年大家一起努力吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号