2020软件工程实践第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | <学习解析 Json 文件,以及熟悉 GitHub 的使用,并对第一次作业进行总结> |
| 学号 | <181800330> |
| 使用语言 | Python |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| Estimate | 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 180 | 240 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 60 |
| Design Spec | 生成设计文档 | 60 | 80 |
| Design Review | 设计复审 | 40 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 45 |
| Design | 具体设计 | 150 | 200 |
| Coding | 具体编码 | 180 | 250 |
| Code Review | 代码复审 | 20 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 300 |
| Reporting | 报告 | 20 | 20 |
| Test Report | 测试报告 | 30 | 50 |
| Size Measurement | 计算工作量 | 20 | 50 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 40 | 80 |
| Sum | 合计 | 1020 | 1555 |
二、解题思路与分析
本次题目的要求是制作一个程序统计和分析 GitHub 的用户行为数据,数据规模在 10 GB 以下,以 json 格式给出。统计个人的 4 种事件的数量、每一个项目的 4 种事件的数量、每一个人在每一个项目的 4 种事件的数量。
刚刚拿到这个问题时,疑惑多多,感觉真是鸭梨山大,完全是无从下手,在听到华哥说这是一道大数据的题目时,赶紧拿起百度搜了搜,不搜还好,这一搜心就凉了半截😭(~难以想象之后的一周每天的的睡眠时间~😂)
但好在华哥在QQ群里提示了很多关键点💓,根据这些小提示,在反复读完题面之后,我详细的总结出了我现在还不了解的问题,这些问题是我在正式编程之前需要去仔细了解的。
1、问题合集
- Json文件的使用方法、如何导入Json文件到Python中、如何生成新的Json文件
- Python的代码规范、库调用、函数调用的使用方法(由于之前只是很粗略的看过相关Python的入门书,所以Python基础非常薄弱,Coding过程可以说是历经九九八十一难!)
- 有关单元测试的覆盖率与性能测试相关问题
2、解决方案
- 对于Json文件的使用方法、如何导入Json文件到Python中、如何生成新的Json文件这一系列问题,我通过CSDN详细的查找了相关资料
Json文件的使用
Json文件的使用方法 - Python的代码规范参考华哥给我们给我们的有关Python的规范文档《Python PEP8》(在网上找了一个中文版的,更加方便大家阅读)
- 对于单元测试这一块,同样是上网寻找解决方法
(推荐廖雪峰老师的网站,里面有很多关于unittest函数的讲解:单元测试) - 关于Coding:这应该是每个人都绕不开的问题,五个字,码就完事了!😏
在解决完上述的问题之后,便开始进入主题,进行项目的任务分解,化繁为简,以此来完成任务
3、项目任务分解
我将这次任务大致的分为命令行参数的解析、Json文件的第一次读取,数据分析(对题目中所给的三种统计内容进行统计),生成三个符合指定要求的Json文件,在Json文件中查询答案。首先结合助教给出的有关命令行参数的代码,给出有关命令行参数的代码设置,并解析命令行参数。其次,构建DATA类,在这个类中写出读取Json文件的read_1函数,分析统计三个内容的analysis函数,以及save2json函数来生成三个指定项目的Json文件,最后还有read_2函数,用来查询数据。
三、设计实现过程
1、代码组织
本题的的核心代码就是init函数,在这个函数之中又分为read_1函数、analysis函数、save2json函数、read_2函数。read_1函数负责读出Json数据,通过Json_loads函数将Json文件转化为字典添加到列表中,analysis函数负责分析数据构建一个字典列表,归类汇总,将三个目标对应的数值通过搜索计算得出,save2json函数通过json.dump生成三个以供后续查询的Json文件,最后read_2函数负责查询答案。
2、核心代码init函数的流程图

四、代码说明
1、命令行参数设置:
def run():#命令行参数的设置(-i为初始化,-u为用户,-r为项目,-e为事件)
my_parser = argparse.ArgumentParser(description='analysis the json file')
my_parser.add_argument('-i', '--init', help='json file path')
my_parser.add_argument('-u', '--user', help='username')
my_parser.add_argument('-r', '--repo', help='repository name')
my_parser.add_argument('-e', '--event', help='type of event')
2、命令行参数解析:
args = my_parser.parse_args()#命令行参数的解析
3、读取Json文件:
def __read_1(self):
self.__dicts = []
for root, dirs, files in os.walk(self.__dir_addr):
for file in files:
if file[-5:] == '.json' and file[-6:] != '1.json' and file[-6:] != '2.json' and file[-6:] != '3.json':
with open(file, 'r', encoding='utf-8') as f:
self.__jsons = [x for x in f.read().split('\n') if len(x)>0]#读取json文件并按行分割
for self.__json in self.__jsons:
self.__dicts.append(json.loads(self.__json))#将json文件转化成字典,并添加到列表之中
4、分析数据:
def __analysis(self):
self.__types = ['PushEvent', 'IssueCommentEvent', 'IssuesEvent', 'PullRequestEvent']
self.__cnt_perP = {}
self.__cnt_perR = {}
self.__cnt_perPperR = {}
for self.__dict in self.__dicts:
# 如果属于四种事件之一 则增加相应值
if self.__dict['type'] in self.__types:
self.__event = self.__dict['type']
self.__name = self.__dict['actor']['login']
self.__repo = self.__dict['repo']['name']
self.__cnt_perP[self.__name + self.__event] = self.__cnt_perP.get(self.__name + self.__event, 0) + 1
self.__cnt_perR[self.__repo + self.__event] = self.__cnt_perP.get(self.__repo + self.__event, 0) + 1
self.__cnt_perPperR[self.__name + self.__repo + self.__event] =
self.__cnt_perPperR.get(self.__name + self.__repo + self.__event, 0) + 1
5、save2json函数:
def __save2json(self):
with open("1.json", 'w', encoding='utf-8') as f:
json.dump(self.__cnt_perP, f)#dump:将dict类型转换为json字符串格式,写入到文件 (易存储)
with open("2.json", 'w', encoding='utf-8') as f:
json.dump(self.__cnt_perR, f)
with open("3.json", 'w', encoding='utf-8') as f:
json.dump(self.__cnt_perPperR, f)
5、查询函数:
def __read_2(self):
self.__cnt_perP = {}
self.__cnt_perR = {}
self.__cnt_perPperR = {}
with open("1.json", encoding='utf-8') as f:
self.__cnt_perP = json.load(f)#load:针对文件句柄,将json格式的字符转换为dict,从文件中读取
with open("2.json", encoding='utf-8') as f:
self.__cnt_perR = json.load(f)
with open("3.json", encoding='utf-8') as f:
self.__cnt_perPperR = json.load(f)
五、单元测试
测试函数代码:
def test_queryu(self):#测试查询个人的 4 种事件的数量
self.my_data = GHAnalysis.Data('.')
self.my_data = GHAnalysis.Data()
self.assertEqual(self.my_data.get_cnt_user('rspt', 'PushEvent'), 1)
def test_queryr(self):#测试每一个项目的 4 种事件的数量
self.my_data = GHAnalysis.Data('.')
self.my_data = GHAnalysis.Data()
self.assertEqual(self.my_data.get_cnt_repo('rspt/rspt-theme', 'PushEvent'), 1)
def test_queryru(self):#测试每一个人在每一个项目的 4 种事件的数量
self.my_data = GHAnalysis.Data('.')
self.my_data = GHAnalysis.Data()
self.assertEqual(self.my_data.get_cnt_user_and_repo('rspt', 'rspt/rspt-theme', 'PushEvent'), 1)
六、单元覆盖率和性能测试
1、单元测试
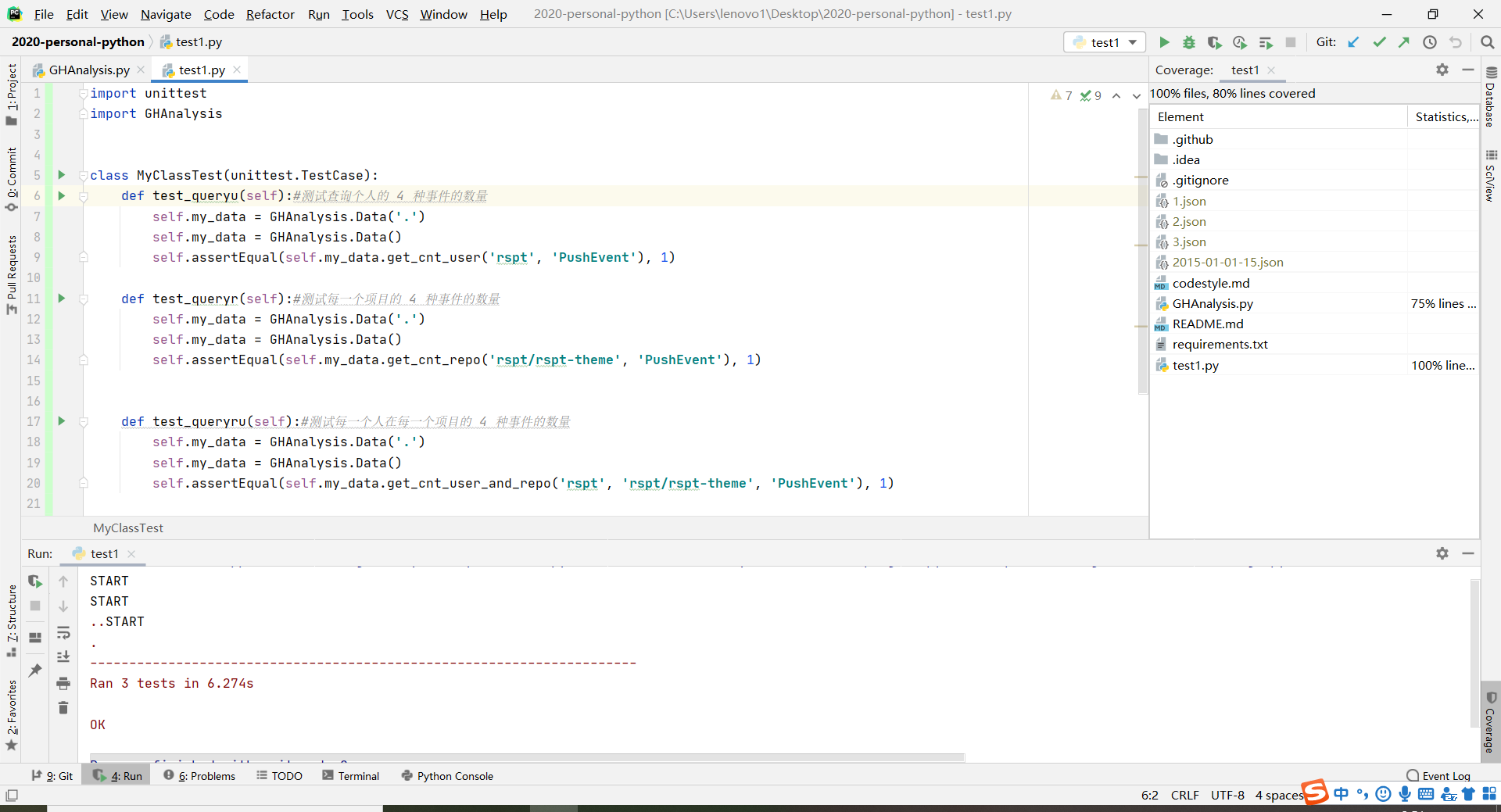
- 覆盖率还是比较低只有75%,回到GHAnalysis函数中,对于命令行参数的设置还有解析没有覆盖到。
2、性能测试(表格)
- 用Python自带的Profile运行得出

3、性能测试(网状图)
- 用Python自带的Profile运行得出

七、代码规范链接
八、总结
①:第一次编程作业,真是一切从零开始,从读懂题面到查找资料解决问题,从Python零基础到按照华哥的Python样例一个一个字手打,对于Python小白来说真的是历经九九八十一难。
②:Json文件的读取与操作、命令行参数的设置与运行、单元测试、Python代码规范,这些陌生的知识在短短的一周之内完全的涌入我的脑子,对我的知识吸收能力是一个极大的考验
③:当我们遇到难题时,可以主动去请教同学,但是我们更加需要注重提问的智慧,如何将一个问题完整的提问也是一门学问。
④:软工实践,我们未完待续~~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号