
进度条加载与案例优化对比——python使用perf_count方法实现
本章我们将讨论python3 perf_counter()的用法及它的实际应用我从中选取两个python基于rquests库的爬虫实例代码源文件进行举例
Python3 perf_counter() 用法:
调用一次 perf_counter(),从计算机系统里随机选一个时间点A,计算其距离当前时间点B1有多少秒。当第二次调用该函数时,默认从第一次调用的时间点A算起,距离当前时间点B2有多少秒。两个函数取差,即实现从时间点B1到B2的计时功能。
import time scale = 50 print("执行开始".center(scale//2,"-")) # .center() 控制输出的样式,宽度为 25//2,即 22,汉字居中,两侧填充 - start = time.perf_counter() # 调用一次 perf_counter(),从计算机系统里随机选一个时间点A,计算其距离当前时间点B1有多少秒。
#当第二次调用该函数时,默认从第一次调用的时间点A算起,距离当前时间点B2有多少秒。两个函数取差,即实现从时间点B1到B2的计时功能。 for i in range(scale+1): a = '*' * i # i 个长度的 * 符号 b = '.' * (scale-i) # scale-i) 个长度的 . 符号。符号 * 和 . 总长度为50 c = (i/scale)*100 # 显示当前进度,百分之多少 dur = time.perf_counter() - start # 计时,计算进度条走到某一百分比的用时 print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur),end='') # \r用来在每次输出完成后,将光标移至行首,这样保证进度条始终在同一行输出,
#即在一行不断刷新的效果;{:^3.0f},输出格式为居中,占3位,小数点后0位,浮点型数,
#对应输出的数为c;{},对应输出的数为a;{},对应输出的数为b;{:.2f},输出有两位小数的浮点数,
#对应输出的数为dur;end='',用来保证不换行,不加这句默认换行。
time.sleep(0.1) # 在输出下一个百分之几的进度前,停止0.1秒
print("\n"+"执行结果".center(scale//2,'-'))
测试结果:
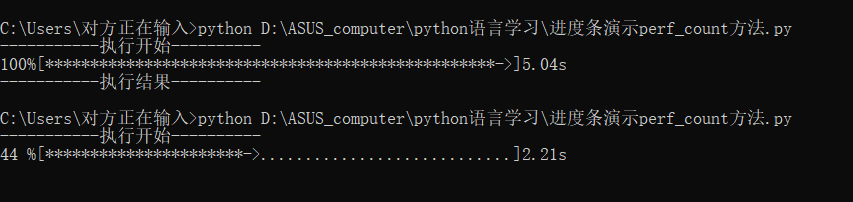
这当然不止这一点用处
比如你还可以用在程序的性能测试上
进行性能分析比对查找问题
————上例子:
Requests库的爬取性能分析
前一阵子再做网略爬虫,就拿这个最简单例子来讲解感觉挺适合的。
尽管Requests库功能很友好、开发简单(其实除了import外只需一行主要代码),但其性能与专业爬虫相比还是有一定差距的。请编写一个小程序,“任意”找个url,测试一下成功爬取100次网页的时间。(某些网站对于连续爬取页面将采取屏蔽IP的策略,所以,要避开这类网站。)
在这里我们以百度为url链接测试,代码如下:
first_test.py
import time import requests def getHtml(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent.encoding return url.text except: return("The requests get url found unkonw-mistakes.") def main(): url = "https://baidu.com" time1 = time.time() i = 0 while(i<100): start = time.time() getHtml(url) end = time.time() i += 1 print('第{}次爬取耗时{}s'.format(i+1,end-start)) time2 = time.time() print(time2-time1) if __name__ =='__main__': main()
运行结果:

如图所示大约共耗时31.19s .
ok,让我们进行接下来的测试.........
second_test.py
import requests import time def getHTMLText_timecost(url): try: r = requests.get(url,timeout = 30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return 'ERRO' def main(): url = 'https://www.baidu.com' sumtime = 0 succtimes = 0 for i in range(100): start = time.time() res = getHTMLText_timecost(url) if res != 'ERRO': succtimes += 1 end = time.time() timecost = end - start sumtime += timecost print('第{}次爬取耗时{}s'.format(i+1,timecost)) print('共爬取{}次,耗时{}s,其中爬取成功{}次'.format(i+1,sumtime,succtimes)) if __name__ == '__main__': main()
运行结果:
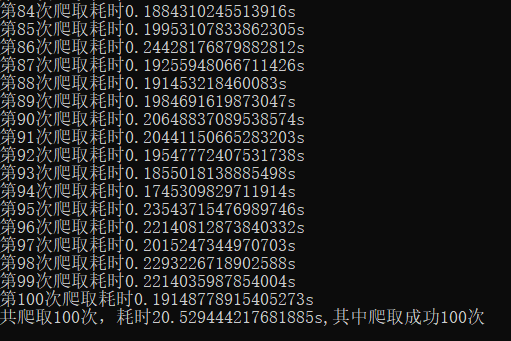
如图所示大约共耗时20.53s .
经过这两段代码的调试运行,我们发现相同功能下不同代码之间存在着性能的差异,并随着运
算工作量的提升而愈发明显这就需要我们对代码进行科学的分析与思考寻求更优的方案投入到实际应用中。

