大数据环境搭建
一、宿主机环境准备
1. 关闭安全相关服务
(1) 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service
(2) 关闭selinux
# 临时关闭
setenforce 0
# 永久关闭
vim /etc/selinux/config
SELINUX=disabled
(3)重启机器
reboot
2. 创建docker网络
(1) 创建一个新的docker虚拟网桥,172.33.0网段
docker network create --subnet=172.33.0.0/24 docker-bd0
(2) 查看创建的虚拟网桥
docker network ls
NETWORK ID NAME DRIVER SCOPE
4608e8409547 docker-bd0 bridge local
(3) 查看虚拟网桥对应的Linux宿主机虚拟网卡
ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:97:9b:f1:8f txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
(4) 临时删除docker0网桥(意味着激活docker-bd0网桥)
# 不执行
ifconfig docker0 down
brctl delbr docker0
(5) 重启docker服务
systemctl restart docker
(6) 配置dns服务器
vim /etc/resolv.conf
修改为如下
# Generated by NetworkManager
nameserver 172.33.0.10
nameserver 8.8.8.8
nameserver 8.8.4.4
3. 创建与容器的共享目录
# 在宿主机中创建/mnt/docker_share 用于存放用来安装的软件
mkdir /mnt/docker_share
cd /mnt/docker_share
# 同时将docker容器中的所有软件以及数据都放在 /opt 中用于共享
cd /opt
二、docker环境部署图
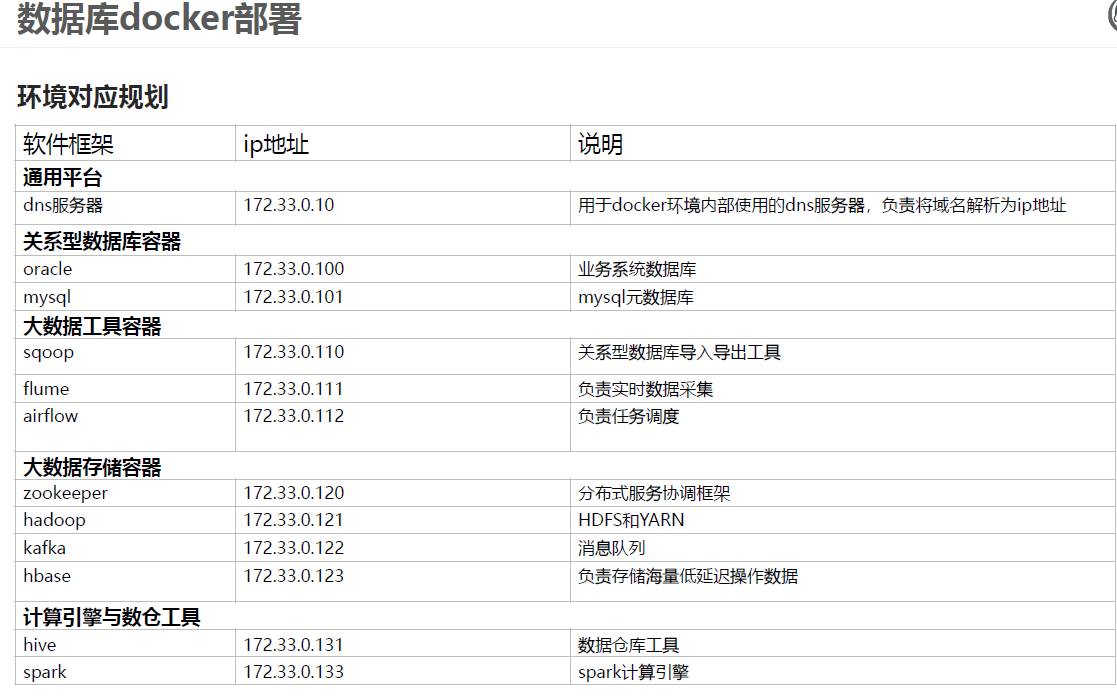
# 在宿主机中 添加映射
vi /etc/hosts
172.33.0.10 dns.bigdata.cn
172.33.0.100 oracle.bigdata.cn
172.33.0.101 mysql.bigdata.cn
172.33.0.110 sqoop.bigdata.cn
172.33.0.111 flume.bigdata.cn
172.33.0.112 airflow.bigdata.cn
172.33.0.120 zookeeper.bigdata.cn
172.33.0.121 hadoop.bigdata.cn
172.33.0.122 kafka.bigdata.cn
172.33.0.123 hbase.bigdata.cn
172.33.0.131 hive.bigdata.cn
172.33.0.133 spark.bigdata.cn
# 在你的windows电脑上配置 -- 为了方便访问
cd /windows/system32/driver/etc/hosts
192.168.149.88 oracle.bigdata.cn
192.168.149.88 hadoop.bigdata.cn
192.168.149.88 hive.bigdata.cn
192.168.149.88 mysql.bigdata.cn
192.168.149.88 node1
三、数据库部署
(一). Oracle数据库部署
1. 拉取docker11镜像
docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g
2. 查看已经下载的镜像
docker images
3. 创建oracle容器
# 创建容器,并将1521端口映射到Linux宿主机端口
docker run --net docker-bd0 --ip 172.33.0.100 -d -p 1521:1521 --restart=always --name oracle 3fa112fd3642 ('容器名或id')
4. 配置容器Oracle环境变量
# 进入到docker容器的bash中
docker exec -it oracle bash
# 切换到root用户
su root
密码为:helowin
# 添加Oracle环境变量配置
vi /etc/profile
export ORACLE_HOME=/home/oracle/app/oracle/product/11.2.0/dbhome_2
export ORACLE_SID=helowin
export PATH=$ORACLE_HOME/bin:$PATH
# 加载环境变量
source /etc/profile
5. oracle命令连接数据库
# 切换到oracle用户
su oracle
source /etc/profile
# 连接数据库
sqlplus /nolog
conn / as sysdba
# 用来退出,这个不要用,现在
exit 退出
6. 配置oracle字符集
# 1.查看oracle字符集
select * from nls_database_parameters where parameter = 'NLS_CHARACTERSET';
# 2.修改Oracle字符集为ZHS16GBK
# (1) 关闭数据库
shutdown immediate;
# (2) mount方式打开数据库
startup mount
# (3) 配置session
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
ALTER SYSTEM SET AQ_TM_PROCESSES=0;
# (4) 启动数据库
alter database open;
# (5) 修改字符集
ALTER DATABASE character set INTERNAL_USE ZHS16GBK;
# (6) 关闭,重新启动
shutdown immediate;
startup
# (7) 再次查看编码格式
select * from nls_database_parameters where parameter = 'NLS_CHARACTERSET';
# 结果
NLS_CHARACTERSET
ZHS16GBK
7. 创建CISS用户并授权
create user ciss identified by 123456;
grant connect,resource,dba to ciss;
ALTER PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED;
grant imp_full_database to ciss;
exit
# 不用操作
create user test identified by test; -- 创建内部管理员账号密码;
grant connect,resource,dba to test; --将dba权限授权给内部管理员账号和密码;
ALTER PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED; --设置密码永不过期:
alter system set processes=1000 scope=spfile; --修改数据库最大连接数据;
#远程登录时
登录时:SID:helowin
User: test
PassWord:test
conn /as sysdba;--保存数据库
shutdown immediate; --关闭数据库
startup; --启动数据库
show user;
# 如果出现问题,可以使用以下方式删除用户以及用户下所有的表`drop user ciss cascade;`
以下操作可不做
8. 导入数据到oracle中
Ⅰ上传CISS库备份文件
Ⅱ 上传到docker容器中
# 将资料中的CISS_2021.dmp文件上传到Linux系统中
docker cp ./CISS_2021.dmp '容器名称或者id':/home/
Ⅲ 进入到Docker容器并执行导入
-- 再进入到容器中
docker exec -it oracle bash
-- 查看DUMP目录是否存在
select * from dba_directories where DIRECTORY_NAME='DB_DUMP';
no rows selected
-- 在SQLPLUS中创建DUMP目录
create directory DB_DUMP as '/home/db_dump';
# 在Docker容器中创建DUMP目录文件夹
su root
mkdir -p /home/db_dump
chown oracle /home/db_dump
# 导入数据到DUMP目录
cd /home/db_dump
# 将DMP文件移动到DUMP目录
mv /home/CISS_2021.dmp /home/db_dump/
exit
# 使用oracle用户执行导入
source /etc/profile
impdp ciss/123456@localhost/helowin DIRECTORY=DB_DUMP DUMPFILE=CISS_2021.dmp
# 导入完成后删除dmp文件
rm -rf /home/db_dump/CISS_2021.dmp
9. 查询数据测试
select TABLE_NAME from all_tables where TABLE_NAME LIKE 'CISS_%';
(二). Mysql数据库部署
1. 拉取mysql镜像
docker pull mysql:5.7
2. 创建容器,设置端口映射、目录映射
docker run -d --name mysql --net docker-bd0 --ip 172.33.0.101 -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci
# 在/root目录下创建mysql目录用于存储mysql数据信息
mkdir /opt/mysql
cd /opt/mysql
docker run \
--restart always \
--net docker-bd0 --ip 172.33.0.101 \
-p 3306:3306 \
-v /opt/mysql/conf:/etc/mysql/conf.d \
-v /opt/mysql/logs:/var/log/mysql \
-v /opt/mysql/data:/var/lib/mysql \
-e MYSQL_DATABASE=data \
-e MYSQL_ROOT_PASSWORD=123456 \
-d -it --name mysql mysql:5.7 \
--character-set-server=utf8mb4 \
--collation-server=utf8mb4_unicode_ci
3. 进入容器,操作Mysql
docker exec -it mysql bash
mysql -uroot -p
123456
4.修改字符编码
# 1.查看当前MYSQL的默认编码
show variables like 'character%';
# 2.退出当前mysql,但不退出mysql容器
exit
cd /opt/mysql/conf
vim /mysql.cnf
# 内容如下
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
5. 连接测试
四、大数据环境部署
(一)Hadoop 环境容器搭建
1. 拉取镜像
docker pull centos:7
2. 将安装包上传到 /mnt/docker_share中
# mkdir /mnt/docker_share
cd /mnt/docker_share
3. 将jdk 和hadoop 解压
# 若没有解压工具 yum install lrzsz
tar -xvzf jdk-8u141-linux-x64.tar.gz -C /opt
tar -xvzf hadoop-2.7.0.tar.gz -C /opt
4. 创建用于保存数据的文件夹
mkdir -p /data/dfs/nn
mkdir -p /data/dfs/dn
5. 启动hadoop容器
docker run \
--net docker-bd0 --ip 172.33.0.121 \
-p 50070:50070 -p 8088:8088 -p 19888:19888 \
-v /mnt/docker_share:/mnt/docker_share \
-v /etc/hosts:/etc/hosts \
-v /opt/hadoop-2.7.0:/opt/hadoop-2.7.0 \
-v /opt/jdk1.8.0_141:/opt/jdk1.8.0_141 \
-v /data/dfs:/data/dfs \
--privileged=true \
-d -it --name hadoop centos:7 \
/usr/sbin/init
# 注意:确保在主机上禁用SELinux
6. 进入hadoop容器
docker exec -it hadoop bash
7. 配置相关文件(准备工作)
# hadoop 容器中:
yum install -y vim
# 免登录
yum install -y openssl openssh-server
yum install -y openssh-client*
# 修改ssh配置文件
vim /etc/ssh/sshd_config
# 在文件最后添加
PermitRootLogin yes
RSAAuthentication yes
PubkeyAuthentication yes
# 启动ssh服务
systemctl start sshd.service
# 设置开机自动启动ssh服务
systemctl enable sshd.service
# 查看服务状态
systemctl status sshd.service
配置免密登录
# hadoop 容器中:
# 1.生成秘钥
ssh-keygen
连续四次回车(不进行其他任何额外操作)
# 成功标志:
The key's randomart image is:
+---[RSA 2048]----+
| ... |
| ... .o . . .|
| . +..= + o +.|
| o =oo* + o o|
| o.S+.. o.E.|
| +o=.. .o+.|
| o ... . .oB|
| + . . +*|
| o.. . ...|
+----[SHA256]-----+
# 2.设置密码
passwd
123456
# 成功标志:
passwd: all authentication tokens updated successfully.
# 3.拷贝公钥
# 需要在(如果没有在宿主机准备阶段配置的话)
vi /etc/hosts
172.33.0.121 hadoop.bigdata.cn
# 然后
ssh-copy-id hadoop.bigdata.cn
# 出现内容
Are you sure you want to continue connecting (yes/no)? yes
root@hadoop.bigdata.cn's password: 123456
# 最后一步:配置jdk
vim /etc/profile
# 配置jdk的环境变量
export JAVA_HOME=/opt/jdk1.8.0_141
export CLASSPATH=${JAVA_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# 让上一步配置生效
source /etc/profile
8.修改Hadoop相关配置文件(可以直接导入)
cd /opt/hadoop-2.7.0/etc/hadoop
(1) core-site.xml
vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop.bigdata.cn:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
(2) hdfs-site.xm
vi hdfs-site.xm
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop.bigdata.cn:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop.bigdata.cn:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/dfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/dfs/dn</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
(3) yarn-site.xml
vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-yarn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop.bigdata.cn</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/user/container/logs</value>
</property>
(4) mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop.bigdata.cn:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop.bigdata.cn:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/tmp/mr-history</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/tmp/mr-done</value>
</property>
(5) hadoop-env.sh
vi hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_141
(6) slaves
vi slaves
hadoop.bigdata.cn
(7) 配置环境变量
vim /etc/profile
export HADOOP_HOME=/opt/hadoop-2.7.0
export PATH=${HADOOP_HOME}/sbin:${HADOOP_HOME}/bin:$PATH
source /etc/profile
9.初始化并启动Hadoop
# 1.初始化
hdfs namenode -format
# 2.启动 也可以找到 cd /opt/hadoop-2.7.0/sbin
start-all.sh
# 启动history server
mr-jobhistory-daemon.sh start historyserver
# 3.测试hadoop
cd $HADOOP_HOME
# 然后
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar pi 2 1
# 4.查看进程- 有以下几个进程,说明已经启动成功了
jps
561 ResourceManager
659 NodeManager
2019 Jps
1559 NameNode
1752 SecondaryNameNode
249 DataNode
# 6.查看web ui
- HDFS
- http://192.168.149.88:50070
- http://node1:50070
- YARN
- http://192.168.149.88:8088
- http://hadoop.bigdata.cn:50070
- Job History Server
- http://192.168.149.88:19888
-
配置开启容器启动Hadoop脚本
# (可在宿主机上搭建一个开机自启的容器脚本) # 1.配置启动脚本 touch /etc/bootstrap.sh chmod a+x /etc/bootstrap.sh # 2.配置文件:bootstrap.sh vim /etc/bootstrap.sh # 文件内容 #!/bin/bash source /etc/profile cd /opt/hadoop-2.7.0 #stop-all.sh start-dfs.sh start-yarn.sh mr-jobhistory-daemon.sh start historyserver # 2.将脚本添加到自动启动服务中 vim /etc/rc.d/rc.local /etc/bootstrap.sh # 3.开启执行权限 chmod 755 /etc/rc.d/rc.local # 4.为宿主机配置域名映射(在宿主机准备阶段的最后有补充) 192.168.149.88 oracle.bigdata.cn 192.168.149.88 hadoop.bigdata.cn 192.168.149.88 hive.bigdata.cn 192.168.149.88 mysql.bigdata.cn 192.168.149.88 node1 # 退出容器 ctrl + p ctrl + d # 查看容器状态 docker ps -a # 启动容器 docker start '容器名或id' docker strop '容器名或id' # 删除容器(需要先停止容器) docker rm '容器名或id' # 查看镜像 docker images # 删除镜像(先删除关联的容器后,才能删除) docker rmi '镜像名或id'
10. 创建hadoop镜像
# 提交镜像,方便后续部署使用
# 容器 镜像命名
docker commit hadoop hadoop:2.7.0
# 查看镜像
docker images
(二)Hive环境容器搭建
1. 将hive安装包上传并解压
# mkdir /mnt/docker_share
cd /mnt/docker_share
tar -xvzf apache-hive-2.1.0-bin.tar.gz -C /opt/
2. 修改hive配置文件
cd /opt/apache-hive-2.1.0-bin/conf
touch hive-site.xml
vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop.bigdata.cn:9000</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://mysql.bigdata.cn:3306/hive?createDatabaseIfNotExist=true&useSSL=false&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hive.bigdata.cn</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hive.bigdata.cn:9083</value>
</property>
</configuration>
3. 上传配置mysql驱动
cp /mnt/docker_share/mysql-connector-java-5.1.38.jar /opt/apache-hive-2.1.0-bin/lib
ll /opt/apache-hive-2.1.0-bin/lib | grep mysql
4. 启动mysql 和hadoop容器
# 启动msyql容器
docker start mysql
# 启动hadoop容器
docker start hadoop
5. 创建hive容器
docker run \
--privileged=true \
--net docker-bd0 \
--ip 172.33.0.131 \
-v /mnt/docker_share:/mnt/docker_share \
-v /etc/hosts:/etc/hosts \
-v /opt/hadoop-2.7.0:/opt/hadoop-2.7.0 \
-v /opt/jdk1.8.0_141:/opt/jdk1.8.0_141 \
-v /opt/apache-hive-2.1.0-bin:/opt/apache-hive-2.1.0-bin \
-p 10000:10000 \
--name hive -d hadoop:2.7.0
6. 进入hive容器
docker exec -it hive bash
7.配置hive环境变量
vim /etc/profile
export HIVE_HOME=/opt/apache-hive-2.1.0-bin
export PATH=$HIVE_HOME/bin:$PATH
source /etc/profile
8.初始化mysql元数据
# 初始化mysql元数据命令(还是在hive中)
schematool -initSchema -dbType mysql
# 进入到mysql容器中,设置hive相关表的编码格式
docker exec -it mysql bash
# 进入到mysql中,执行以下几条语句,修改Hive的默认编码方式
mysql -u root -p123456
use hive;
-- 修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
-- 修改分区字段注解:
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
-- 修改索引注解:
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
-- 查看编码格式
show variables like "%char%";
9.启动hive和使用beeline连接hive
(1) 启动hive
nohup hive --service metastore &
nohup hive --service hiveserver2 &
(2)使用beeline连接hive
beeline
!connect jdbc:hive2://hive.bigdata.cn:10000
10.配置hive自启动脚本
(1) 创建日志保存目录
mkdir -p /opt/apache-hive-2.1.0-bin/logs
(2) 创建启动脚本
vim /etc/bootstrap2.sh
# !/bin/sh
source /etc/profile
DATE_STR=`/bin/date "+%Y%m%d%H%M%S"`
HIVE_METASTORE_LOG=${HIVE_HOME}/logs/hiveserver2-metasvr-${DATE_STR}.log
HIVE_THRIFTSVR_LOG=${HIVE_HOME}/logs/hiveserver2-thriftsvr-${DATE_STR}.log
nohup ${HIVE_HOME}/bin/hive --service metastore >> ${HIVE_METASTORE_LOG} 2>&1 &
nohup ${HIVE_HOME}/bin/hive --service hiveserver2 >> ${HIVE_THRIFTSVR_LOG} 2>&1 &
(3) 设置脚本执行权限
chmod a+x /etc/bootstrap2.sh
(4) 加入自动启动服务
vim /etc/rc.d/rc.local
/etc/bootstrap2.sh
chmod 755 /etc/rc.d/rc.local
(5) 重启容器
docker restart hive
docker exec -it hive bash
(三)sqoop容器环境搭建
1. 上传并解压sqoop安装包
tar -xvzf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt
mv /opt/sqoop-1.4.7.bin__hadoop-2.6.0/ /opt/sqoop
2. 配置oracle驱动
# 后续需要将Oracle中的数据导入到HDFS,所需需要将Oracle的JDBC驱动放入到SQOOP中
# 注意:这个步骤可以直接跳过,为什么呢?因为这个根据你的数据库有关。然后还是有就是,把不同的数据库驱动都要放在sqoop的lib中
tar -xvzf ojdbc-full.tar.gz -C /opt/sqoop/lib/
mv /opt/sqoop/lib/OJDBC-Full/* /opt/sqoop/lib
3. 配置sqoop环境变量
# 修改sqoop配置文件,配置sqoop环境变量,可直接导入
cd /opt/sqoop/conf
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/hadoop-2.7.0
export HADOOP_MAPRED_HOME=/opt/hadoop-2.7.0
export HIVE_HOME=/opt/apache-hive-2.1.0-bin
4. 创建sqoop容器
docker run \
--privileged=true \
--net docker-bd0 \
--ip 172.33.0.110 \
-v /mnt/docker_share:/mnt/docker_share \
-v /etc/hosts:/etc/hosts \
-v /opt/hadoop-2.7.0:/opt/hadoop-2.7.0 \
-v /opt/jdk1.8.0_141:/opt/jdk1.8.0_141 \
-v /opt/apache-hive-2.1.0-bin:/opt/apache-hive-2.1.0-bin \
-v /opt/sqoop:/opt/sqoop \
--name sqoop -d hadoop:2.7.0
5. 配置环境变量
# 进入容器
docker exec -it sqoop bash
# 配置环境变量
vim /etc/profile
export HIVE_HOME=/opt/apache-hive-2.1.0-bin
export SQOOP_HOME=/opt/sqoop
export PATH=${SQOOP_HOME}/bin:$PATH
source /etc/profile
6. 测试sqoop
# 1.启动oracle、sqoop、hadoop服务
docker start oracle sqoop hadoop
# 2.进入容器,加载环境变量
source /etc/profile
# 3.执行以下sqoop导出脚本
#(1) 测试Oracle连接
sqoop list-databases \
--connect jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin \
--username ciss \
--password 123456
# (2) 测试sqoop导入oracle表到HDFS
hdfs dfs -mkdir -p /data/test
# 导出一个表测试
sqoop import \
--connect jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin \
--username ciss \
--password 123456 \
--warehouse-dir /data/test/CISS_BASE_AREAS \
--table CISS4.CISS_BASE_AREAS -m 1
hdfs dfs -rm -r /data/test/CISS_BASE_AREAS
(四) Spark环境容器搭建
1.上传并解压spark压缩包
-
上传压缩包
- spark-2.4.7-bin-hadoop2.7.tgz
-
解压压缩包
tar -xvzf spark-2.4.7-bin-hadoop2.7.tgz -C /opt/
2. 配置Spark HistoryServer
cd /opt/spark-2.4.7-bin-hadoop2.7/conf
cp spark-defaults.conf.template spark-defaults.conf
# spark-defaults.conf
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop.bigdata.cn:9000/tmp/spark-history
3.设置默认读取HDFS
cd /opt/spark-2.4.7-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
# vim spark-env.sh
export JAVA_HOME=/opt/jdk1.8.0_141/
export SPARK_HOME=/opt/spark-2.4.7-bin-hadoop2.7
export SPARK_MASTER_IP=spark.bigdata.cn
export SPARK_EXECUTOR_MEMORY=2G
export HADOOP_CONF_DIR=/opt/hadoop-2.7.0/etc/hadoop
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=200 -Dspark.history.fs.logDirectory=hdfs://hadoop.bigdata.cn:9000/tmp/spark-history"
4. 配置集群节点
cp slaves.template slaves
vim slaves
spark.bigdata.cn
5.创建Spark容器
-
创建spark容器,指定IP
docker run \ --privileged=true \ --net docker-bd0 \ --ip 172.33.0.133 \ -v /mnt/docker_share:/mnt/docker_share \ -v /etc/hosts:/etc/hosts \ -v /opt/hadoop-2.7.0:/opt/hadoop-2.7.0 \ -v /opt/jdk1.8.0_141:/opt/jdk1.8.0_141 \ -v /opt/apache-hive-2.1.0-bin:/opt/apache-hive-2.1.0-bin \ -v /opt/spark-2.4.7-bin-hadoop2.7:/opt/spark-2.4.7-bin-hadoop2.7 \ -p 18080:18080 -p 8080:8080 -p 7077:7077 -p 4040:4040 -p 10001:10001 \ --name spark -d hadoop:2.7.0
6.容器配置环境变量
-
进入容器中
docker exec -it spark bash -
配置环境变量
vim /etc/profile export HIVE_HOME=/opt/apache-hive-2.1.0-bin export PATH=$HIVE_HOME/bin:$PATH export SPARK_HOME=/opt/spark-2.4.7-bin-hadoop2.7 export PATH=${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH source /etc/profile
7.启动spark
-
创建spark history目录
hadoop fs -mkdir -p /tmp/spark-history start-all.sh start-history-server.sh
8.查看spark web ui
- Spark Web UI:
- Spark HistoryServer:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号