
文件IO中的direct和sync标志位——O_DIRECT和O_SYNC详析
man手册里介绍O_DIRECT标志是这么介绍的:
O_DIRECT (since Linux 2.4.10)
Try to minimize cache effects of the I/O to and from this file. In general this will degrade performance, but it is useful in special situations, such as when applications do their own
caching. File I/O is done directly to/from user-space buffers. The O_DIRECT flag on its own makes an effort to transfer data synchronously, but does not give the guarantees of the O_SYNC
flag that data and necessary metadata are transferred. To guarantee synchronous I/O, O_SYNC must be used in addition to O_DIRECT. See NOTES below for further discussion.
大意就是说,无法保证数据写入磁盘。如果想要保证数据写入磁盘,必须追加O_SYNC标志。
而大多数自缓存应用为了能够自己设计缓存架构,必须绕过页高速缓存。那么必然使用O_DIRECT标志。但实际上数据库等等这些自缓存应用可能也没有使用O_SYNC标志。实际上,在《深入理解linux内核》第三版上也有说明:即认为一般情况下direct_IO可以保证数据落盘。
这似乎形成了一个矛盾。我也被这个问题困扰了很久,在研究相关代码后,大概得出了结论。
首先我先大致介绍一下,之后贴出相应的代码,有耐心的朋友可以看完所有代码。
简单的调用关系可以表示如下:
|--ext4_file_write_iter
|--__generic_file_write_iter
| (direct)
|--generic_file_direct_write
|--direct_IO(ext4_direct_IO)
|--ext4_direct_IO_write
|--__blockdev_direct_IO(注册回调函数__blockdev_direct_IO)
|--do_blockdev_direct_IO
| (O_DSYNC)
|--dio_set_defer_completion(加入队列)
|--dio_await_completion
简单的分析如下:
direct标志在__generic_file_write_iter函数内检测并进入if分支。之后调用generic_file_direct_write进行写操作,最终调用submit_bio将该bio提交给通用块层。一般来说,提交之后,函数不会立即返回,而是在do_blockdev_direct_IO内调用dio_await_completion等待每个bio完成,在所有bio完成之后调用dio_complete完成整个dio。因此该direct_io能够保证下发的bio已经完成。但是具体通用块层之下是否有缓存无法感知。
而sync的处理还在__generic_file_write_iter函数的封装函数 里。如果__generic_file_write_iter返回大于零的值,即IO操作成功。之后会进入generic_write_sync函数内。该函数内会判断是否sync,如果设置了sync或者dsync,都将进入fsync函数的流程。
fsync的实现由各文件系统负责。以ext4为例,fsync的实现是ext4_sync_file。该函数会搜寻需要刷新的脏页,强制将所有的脏页最终通过submit_bio提交给调度器,并等待完成。
分析:direct是绕过页高速缓存,直接将数据通过submit_bio发送出去。sync标志是在处理完IO之后(不论这个IO是不是direct),调用fsync强制刷新。sync标志同样无法感知底层的缓存情况,如果底层有仍然有缓存,同样sync无法保证一定落入磁盘。
广泛意义上理解direct无法保证同步I/O的原因是什么呢?我认为是在这种情况下:
即当前IO为异步IO的情况下,异步IO在处理完成的情况下,不会进行等待。
在使用dd命令产生IO时,dd命令不使用aio接口,因此,仅仅direct的情况下,就可以保证数据的落盘,加上sync,多了额外的消耗,性能降低。测试如下所示:
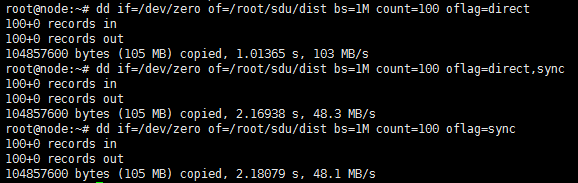
在使用fio进行测试时,因为默认使用libaio引擎,因此会使用aio接口,产生异步aio,仅仅加上direct,不能保证数据落盘。但是也没有别的办法保证落盘。只能通过加上sync标志调用fsync来等待。可以看到,同样是仅仅只有direct,dd和fio的性能相差很大。但是仅调用sync的情况,相差不大。而既有direct又有sync的情况,和dd下只有direct的情况相差不大。

但是如果将引擎修改成sync引擎将变成于dd结果相近的数据。

上述同时有sync和direct 或者 只有sync的时候,性能差不多。我的理解是sync需要的时间大于不设置direct需要的时间,由于sync的fsync函数和真正的落盘几乎是并行的。因此可以看做sync时间包含了不使用direct多出来的时间。因此两者表现一致。但是这是我的个人理解,还有待商榷。
结论:如果direct和sync标志同时置位,实际上direct已经能保证数据的落盘(但是可能落入更下层的缓冲区)。加上sync标志,会浪费系统资源,搜索缓存池内的脏页,强制刷新到下层。由于搜索算法的原因,有可能会导致多余的IO操作。
下面将具体分析代码。
首先看__generic_file_write_iter函数,这个函数在每个IO路径上必然经过。
2790 ssize_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
2791 {
2792 struct file *file = iocb->ki_filp;
2793 struct address_space * mapping = file->f_mapping;
2794 struct inode *inode = mapping->host;
2795 ssize_t written = 0;
2796 ssize_t err;
2797 ssize_t status;
2798
2799 /* We can write back this queue in page reclaim */
2800 current->backing_dev_info = inode_to_bdi(inode);
2801 err = file_remove_privs(file);
2802 if (err)
2803 goto out;
2804
2805 err = file_update_time(file);
2806 if (err)
2807 goto out;
2808
2809 if (iocb->ki_flags & IOCB_DIRECT) {
2810 loff_t pos, endbyte;
2811
2812 written = generic_file_direct_write(iocb, from);
2813 /*
2814 * If the write stopped short of completing, fall back to
2815 * buffered writes. Some filesystems do this for writes to
2816 * holes, for example. For DAX files, a buffered write will
2817 * not succeed (even if it did, DAX does not handle dirty
2818 * page-cache pages correctly).
2819 */
2820 if (written < 0 || !iov_iter_count(from) || IS_DAX(inode))
2821 goto out;
2822
2823 status = generic_perform_write(file, from, pos = iocb->ki_pos);
2824 /*
2825 * If generic_perform_write() returned a synchronous error
2826 * then we want to return the number of bytes which were
2827 * direct-written, or the error code if that was zero. Note
2828 * that this differs from normal direct-io semantics, which
2829 * will return -EFOO even if some bytes were written.
2830 */
2831 if (unlikely(status < 0)) {
2832 err = status;
2833 goto out;
2834 }
2835 /*
2836 * We need to ensure that the page cache pages are written to
2837 * disk and invalidated to preserve the expected O_DIRECT
2838 * semantics.
2839 */
2840 endbyte = pos + status - 1;
2841 err = filemap_write_and_wait_range(mapping, pos, endbyte);
2842 if (err == 0) {
2843 iocb->ki_pos = endbyte + 1;
2844 written += status;
2845 invalidate_mapping_pages(mapping,
2846 pos >> PAGE_SHIFT,
2847 endbyte >> PAGE_SHIFT);
2848 } else {
2849 /*
2850 * We don't know how much we wrote, so just return
2851 * the number of bytes which were direct-written
2852 */
2853 }
2854 } else {
2855 written = generic_perform_write(file, from, iocb->ki_pos);
2856 if (likely(written > 0))
2857 iocb->ki_pos += written;
2858 }
2859 out:
2860 current->backing_dev_info = NULL;
2861 return written ? written : err;
2862 }
在2809行可以看到,如果由direct标志,将进入if分支调用generic_file_direct_write。
2592 ssize_t
2593 generic_file_direct_write(struct kiocb *iocb, struct iov_iter *from)
2594 {
2595 struct file *file = iocb->ki_filp;
2596 struct address_space *mapping = file->f_mapping;
2597 struct inode *inode = mapping->host;
2598 loff_t pos = iocb->ki_pos;
2599 ssize_t written;
2600 size_t write_len;
2601 pgoff_t end;
2602 struct iov_iter data;
2603
2604 write_len = iov_iter_count(from);
2605 end = (pos + write_len - 1) >> PAGE_SHIFT;
2606
2607 written = filemap_write_and_wait_range(mapping, pos, pos + write_len - 1);
2608 if (written)
2609 goto out;
2610
2611 /*
2612 * After a write we want buffered reads to be sure to go to disk to get
2613 * the new data. We invalidate clean cached page from the region we're
2614 * about to write. We do this *before* the write so that we can return
2615 * without clobbering -EIOCBQUEUED from ->direct_IO().
2616 */
2617 if (mapping->nrpages) {
2618 written = invalidate_inode_pages2_range(mapping,
2619 pos >> PAGE_SHIFT, end);
2620 /*
2621 * If a page can not be invalidated, return 0 to fall back
2622 * to buffered write.
2623 */
2624 if (written) {
2625 if (written == -EBUSY)
2626 return 0;
2627 goto out;
2628 }
2629 }
2630
2631 data = *from;
2632 written = mapping->a_ops->direct_IO(iocb, &data);
2633
2634 /*
2635 * Finally, try again to invalidate clean pages which might have been
2636 * cached by non-direct readahead, or faulted in by get_user_pages()
2637 * if the source of the write was an mmap'ed region of the file
2638 * we're writing. Either one is a pretty crazy thing to do,
2639 * so we don't support it 100%. If this invalidation
2640 * fails, tough, the write still worked...
2641 */
2642 if (mapping->nrpages) {
2643 invalidate_inode_pages2_range(mapping,
2644 pos >> PAGE_SHIFT, end);
2645 }
2646
2647 if (written > 0) {
2648 pos += written;
2649 iov_iter_advance(from, written);
2650 if (pos > i_size_read(inode) && !S_ISBLK(inode->i_mode)) {
2651 i_size_write(inode, pos);
2652 mark_inode_dirty(inode);
2653 }
2654 iocb->ki_pos = pos;
2655 }
2656 out:
2657 return written;
2658 }
该函数在2632行调用具体的direct_IO操作,这个操作可以由各个具体的文件系统所定义。例如ext4定义为ext4_direct_IO。
3369 static ssize_t ext4_direct_IO_write(struct kiocb *iocb, struct iov_iter *iter)
3370 {
3371 struct file *file = iocb->ki_filp;
3372 struct inode *inode = file->f_mapping->host;
3373 struct ext4_inode_info *ei = EXT4_I(inode);
3374 ssize_t ret;
3375 loff_t offset = iocb->ki_pos;
3376 size_t count = iov_iter_count(iter);
3377 int overwrite = 0;
3378 get_block_t *get_block_func = NULL;
3379 int dio_flags = 0;
3380 loff_t final_size = offset + count;
3381 int orphan = 0;
3382 handle_t *handle;
3383
3384 if (final_size > inode->i_size) {
3385 /* Credits for sb + inode write */
3386 handle = ext4_journal_start(inode, EXT4_HT_INODE, 2);
3387 if (IS_ERR(handle)) {
3388 ret = PTR_ERR(handle);
3389 goto out;
3390 }
3391 ret = ext4_orphan_add(handle, inode);
3392 if (ret) {
3393 ext4_journal_stop(handle);
3394 goto out;
3395 }
3396 orphan = 1;
3397 ei->i_disksize = inode->i_size;
3398 ext4_journal_stop(handle);
3399 }
3400
3401 BUG_ON(iocb->private == NULL);
3402
3403 /*
3404 * Make all waiters for direct IO properly wait also for extent
3405 * conversion. This also disallows race between truncate() and
3406 * overwrite DIO as i_dio_count needs to be incremented under i_mutex.
3407 */
3408 inode_dio_begin(inode);
3409
3410 /* If we do a overwrite dio, i_mutex locking can be released */
3411 overwrite = *((int *)iocb->private);
3412
3413 if (overwrite)
3414 inode_unlock(inode);
3415
3416 /*
3417 * For extent mapped files we could direct write to holes and fallocate.
3418 *
3419 * Allocated blocks to fill the hole are marked as unwritten to prevent
3420 * parallel buffered read to expose the stale data before DIO complete
3421 * the data IO.
3422 *
3423 * As to previously fallocated extents, ext4 get_block will just simply
3424 * mark the buffer mapped but still keep the extents unwritten.
3425 *
3426 * For non AIO case, we will convert those unwritten extents to written
3427 * after return back from blockdev_direct_IO. That way we save us from
3428 * allocating io_end structure and also the overhead of offloading
3429 * the extent convertion to a workqueue.
3430 *
3431 * For async DIO, the conversion needs to be deferred when the
3432 * IO is completed. The ext4 end_io callback function will be
3433 * called to take care of the conversion work. Here for async
3434 * case, we allocate an io_end structure to hook to the iocb.
3435 */
3436 iocb->private = NULL;
3437 if (overwrite)
3438 get_block_func = ext4_dio_get_block_overwrite;
3439 else if (IS_DAX(inode)) {
3440 /*
3441 * We can avoid zeroing for aligned DAX writes beyond EOF. Other
3442 * writes need zeroing either because they can race with page
3443 * faults or because they use partial blocks.
3444 */
3445 if (round_down(offset, 1<<inode->i_blkbits) >= inode->i_size &&
3446 ext4_aligned_io(inode, offset, count))
3447 get_block_func = ext4_dio_get_block;
3448 else
3449 get_block_func = ext4_dax_get_block;
3450 dio_flags = DIO_LOCKING;
3451 } else if (!ext4_test_inode_flag(inode, EXT4_INODE_EXTENTS) ||
3452 round_down(offset, 1 << inode->i_blkbits) >= inode->i_size) {
3453 get_block_func = ext4_dio_get_block;
3454 dio_flags = DIO_LOCKING | DIO_SKIP_HOLES;
3455 } else if (is_sync_kiocb(iocb)) {
3456 get_block_func = ext4_dio_get_block_unwritten_sync;
3457 dio_flags = DIO_LOCKING;
3458 } else {
3459 get_block_func = ext4_dio_get_block_unwritten_async;
3460 dio_flags = DIO_LOCKING;
3461 }
3462 #ifdef CONFIG_EXT4_FS_ENCRYPTION
3463 BUG_ON(ext4_encrypted_inode(inode) && S_ISREG(inode->i_mode));
3464 #endif
3465 if (IS_DAX(inode)) {
3466 ret = dax_do_io(iocb, inode, iter, get_block_func,
3467 ext4_end_io_dio, dio_flags);
3468 } else
3469 ret = __blockdev_direct_IO(iocb, inode,
3470 inode->i_sb->s_bdev, iter,
3471 get_block_func,
3472 ext4_end_io_dio, NULL, dio_flags);
3473
3474 if (ret > 0 && !overwrite && ext4_test_inode_state(inode,
3475 EXT4_STATE_DIO_UNWRITTEN)) {
3476 int err;
3477 /*
3478 * for non AIO case, since the IO is already
3479 * completed, we could do the conversion right here
3480 */
3481 err = ext4_convert_unwritten_extents(NULL, inode,
3482 offset, ret);
3483 if (err < 0)
3484 ret = err;
3485 ext4_clear_inode_state(inode, EXT4_STATE_DIO_UNWRITTEN);
3486 }
3487
3488 inode_dio_end(inode);
3489 /* take i_mutex locking again if we do a ovewrite dio */
3490 if (overwrite)
3491 inode_lock(inode);
3492
3493 if (ret < 0 && final_size > inode->i_size)
3494 ext4_truncate_failed_write(inode);
3495
3496 /* Handle extending of i_size after direct IO write */
3497 if (orphan) {
3498 int err;
3499
3500 /* Credits for sb + inode write */
3501 handle = ext4_journal_start(inode, EXT4_HT_INODE, 2);
3502 if (IS_ERR(handle)) {
3503 /* This is really bad luck. We've written the data
3504 * but cannot extend i_size. Bail out and pretend
3505 * the write failed... */
3506 ret = PTR_ERR(handle);
3507 if (inode->i_nlink)
3508 ext4_orphan_del(NULL, inode);
3509
3510 goto out;
3511 }
3512 if (inode->i_nlink)
3513 ext4_orphan_del(handle, inode);
3514 if (ret > 0) {
3515 loff_t end = offset + ret;
3516 if (end > inode->i_size) {
3517 ei->i_disksize = end;
3518 i_size_write(inode, end);
3519 /*
3520 * We're going to return a positive `ret'
3521 * here due to non-zero-length I/O, so there's
3522 * no way of reporting error returns from
3523 * ext4_mark_inode_dirty() to userspace. So
3524 * ignore it.
3525 */
3526 ext4_mark_inode_dirty(handle, inode);
3527 }
3528 }
3529 err = ext4_journal_stop(handle);
3530 if (ret == 0)
3531 ret = err;
3532 }
3533 out:
3534 return ret;
3535 }
在3469行进入__blockdev_direct_IO。
1338 ssize_t __blockdev_direct_IO(struct kiocb *iocb, struct inode *inode,
1339 struct block_device *bdev, struct iov_iter *iter,
1340 get_block_t get_block,
1341 dio_iodone_t end_io, dio_submit_t submit_io,
1342 int flags)
1343 {
1344 /*
1345 * The block device state is needed in the end to finally
1346 * submit everything. Since it's likely to be cache cold
1347 * prefetch it here as first thing to hide some of the
1348 * latency.
1349 *
1350 * Attempt to prefetch the pieces we likely need later.
1351 */
1352 prefetch(&bdev->bd_disk->part_tbl);
1353 prefetch(bdev->bd_queue);
1354 prefetch((char *)bdev->bd_queue + SMP_CACHE_BYTES);
1355
1356 return do_blockdev_direct_IO(iocb, inode, bdev, iter, get_block,
1357 end_io, submit_io, flags);
1358 }
1116 static inline ssize_t
1117 do_blockdev_direct_IO(struct kiocb *iocb, struct inode *inode,
1118 struct block_device *bdev, struct iov_iter *iter,
1119 get_block_t get_block, dio_iodone_t end_io,
1120 dio_submit_t submit_io, int flags)
1121 {
1122 unsigned i_blkbits = ACCESS_ONCE(inode->i_blkbits);
1123 unsigned blkbits = i_blkbits;
1124 unsigned blocksize_mask = (1 << blkbits) - 1;
1125 ssize_t retval = -EINVAL;
1126 size_t count = iov_iter_count(iter);
1127 loff_t offset = iocb->ki_pos;
1128 loff_t end = offset + count;
1129 struct dio *dio;
1130 struct dio_submit sdio = { 0, };
1131 struct buffer_head map_bh = { 0, };
1132 struct blk_plug plug;
1133 unsigned long align = offset | iov_iter_alignment(iter);
1134
1135 /*
1136 * Avoid references to bdev if not absolutely needed to give
1137 * the early prefetch in the caller enough time.
1138 */
1139
1140 if (align & blocksize_mask) {
1141 if (bdev)
1142 blkbits = blksize_bits(bdev_logical_block_size(bdev));
1143 blocksize_mask = (1 << blkbits) - 1;
1144 if (align & blocksize_mask)
1145 goto out;
1146 }
1147
1148 /* watch out for a 0 len io from a tricksy fs */
1149 if (iov_iter_rw(iter) == READ && !iov_iter_count(iter))
1150 return 0;
1151
1152 dio = kmem_cache_alloc(dio_cache, GFP_KERNEL);
1153 retval = -ENOMEM;
1154 if (!dio)
1155 goto out;
1156 /*
1157 * Believe it or not, zeroing out the page array caused a .5%
1158 * performance regression in a database benchmark. So, we take
1159 * care to only zero out what's needed.
1160 */
1161 memset(dio, 0, offsetof(struct dio, pages));
1162
1163 dio->flags = flags;
1164 if (dio->flags & DIO_LOCKING) {
1165 if (iov_iter_rw(iter) == READ) {
1166 struct address_space *mapping =
1167 iocb->ki_filp->f_mapping;
1168
1169 /* will be released by direct_io_worker */
1170 inode_lock(inode);
1171
1172 retval = filemap_write_and_wait_range(mapping, offset,
1173 end - 1);
1174 if (retval) {
1175 inode_unlock(inode);
1176 kmem_cache_free(dio_cache, dio);
1177 goto out;
1178 }
1179 }
1180 }
1181
1182 /* Once we sampled i_size check for reads beyond EOF */
1183 dio->i_size = i_size_read(inode);
1184 if (iov_iter_rw(iter) == READ && offset >= dio->i_size) {
1185 if (dio->flags & DIO_LOCKING)
1186 inode_unlock(inode);
1187 kmem_cache_free(dio_cache, dio);
1188 retval = 0;
1189 goto out;
1190 }
1191
1192 /*
1193 * For file extending writes updating i_size before data writeouts
1194 * complete can expose uninitialized blocks in dumb filesystems.
1195 * In that case we need to wait for I/O completion even if asked
1196 * for an asynchronous write.
1197 */
1198 if (is_sync_kiocb(iocb))
1199 dio->is_async = false;
1200 else if (!(dio->flags & DIO_ASYNC_EXTEND) &&
1201 iov_iter_rw(iter) == WRITE && end > i_size_read(inode))
1202 dio->is_async = false;
1203 else
1204 dio->is_async = true;
1205
1206 dio->inode = inode;
1207 if (iov_iter_rw(iter) == WRITE) {
1208 dio->op = REQ_OP_WRITE;
1209 dio->op_flags = WRITE_ODIRECT;
1210 } else {
1211 dio->op = REQ_OP_READ;
1212 }
1213
1214 /*
1215 * For AIO O_(D)SYNC writes we need to defer completions to a workqueue
1216 * so that we can call ->fsync.
1217 */
1218 if (dio->is_async && iov_iter_rw(iter) == WRITE &&
1219 ((iocb->ki_filp->f_flags & O_DSYNC) ||
1220 IS_SYNC(iocb->ki_filp->f_mapping->host))) {
1221 retval = dio_set_defer_completion(dio);
1222 if (retval) {
1223 /*
1224 * We grab i_mutex only for reads so we don't have
1225 * to release it here
1226 */
1227 kmem_cache_free(dio_cache, dio);
1228 goto out;
1229 }
1230 }
1231
1232 /*
1233 * Will be decremented at I/O completion time.
1234 */
1235 if (!(dio->flags & DIO_SKIP_DIO_COUNT))
1236 inode_dio_begin(inode);
1237
1238 retval = 0;
1239 sdio.blkbits = blkbits;
1240 sdio.blkfactor = i_blkbits - blkbits;
1241 sdio.block_in_file = offset >> blkbits;
1242
1243 sdio.get_block = get_block;
1244 dio->end_io = end_io;
1245 sdio.submit_io = submit_io;
1246 sdio.final_block_in_bio = -1;
1247 sdio.next_block_for_io = -1;
1248
1249 dio->iocb = iocb;
1250
1251 spin_lock_init(&dio->bio_lock);
1252 dio->refcount = 1;
1253
1254 dio->should_dirty = (iter->type == ITER_IOVEC);
1255 sdio.iter = iter;
1256 sdio.final_block_in_request =
1257 (offset + iov_iter_count(iter)) >> blkbits;
1258
1259 /*
1260 * In case of non-aligned buffers, we may need 2 more
1261 * pages since we need to zero out first and last block.
1262 */
1263 if (unlikely(sdio.blkfactor))
1264 sdio.pages_in_io = 2;
1265
1266 sdio.pages_in_io += iov_iter_npages(iter, INT_MAX);
1267
1268 blk_start_plug(&plug);
1269
1270 retval = do_direct_IO(dio, &sdio, &map_bh);
1271 if (retval)
1272 dio_cleanup(dio, &sdio);
1273
1274 if (retval == -ENOTBLK) {
1275 /*
1276 * The remaining part of the request will be
1277 * be handled by buffered I/O when we return
1278 */
1279 retval = 0;
1280 }
1281 /*
1282 * There may be some unwritten disk at the end of a part-written
1283 * fs-block-sized block. Go zero that now.
1284 */
1285 dio_zero_block(dio, &sdio, 1, &map_bh);
1286
1287 if (sdio.cur_page) {
1288 ssize_t ret2;
1289
1290 ret2 = dio_send_cur_page(dio, &sdio, &map_bh);
1291 if (retval == 0)
1292 retval = ret2;
1293 put_page(sdio.cur_page);
1294 sdio.cur_page = NULL;
1295 }
1296 if (sdio.bio)
1297 dio_bio_submit(dio, &sdio);
1298
1299 blk_finish_plug(&plug);
1300
1301 /*
1302 * It is possible that, we return short IO due to end of file.
1303 * In that case, we need to release all the pages we got hold on.
1304 */
1305 dio_cleanup(dio, &sdio);
1306
1307 /*
1308 * All block lookups have been performed. For READ requests
1309 * we can let i_mutex go now that its achieved its purpose
1310 * of protecting us from looking up uninitialized blocks.
1311 */
1312 if (iov_iter_rw(iter) == READ && (dio->flags & DIO_LOCKING))
1313 inode_unlock(dio->inode);
1314
1315 /*
1316 * The only time we want to leave bios in flight is when a successful
1317 * partial aio read or full aio write have been setup. In that case
1318 * bio completion will call aio_complete. The only time it's safe to
1319 * call aio_complete is when we return -EIOCBQUEUED, so we key on that.
1320 * This had *better* be the only place that raises -EIOCBQUEUED.
1321 */
1322 BUG_ON(retval == -EIOCBQUEUED);
1323 if (dio->is_async && retval == 0 && dio->result &&
1324 (iov_iter_rw(iter) == READ || dio->result == count))
1325 retval = -EIOCBQUEUED;
1326 else
1327 dio_await_completion(dio);
1328
1329 if (drop_refcount(dio) == 0) {
1330 retval = dio_complete(dio, retval, false);
1331 } else
1332 BUG_ON(retval != -EIOCBQUEUED);
1333
1334 out:
1335 return retval;
1336 }
在1270行调用do_direct_IO,到这里,就是把dio下发下去了,最终要调用相应的make_request_fn函数进行排序、合并等操作,但这具体的细节不关注,我们直接看到1323行。在大部分情况,会调用1327行的dio_await_completion。该函数是对所下发的所有io等待完成。因此,directIO可以让数据落盘。这句话没有说错。但为什么又无法保证数据落盘呢?可以看看1323的具体条件,我们发现如果一个异步的IO在正确完成的情况下,一般是直接返回的。在这种情况下,我们不得不添加O_SYNC标志来强制刷新。
我们来看看O_SYNC是在哪里作用的。我们先看generic_file_write_iter函数,我们发现这个函数里调用了__generic_file_write_iter函数,而这个函数正式本文介绍的第一个函数。
2874 ssize_t generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
2875 {
2876 struct file *file = iocb->ki_filp;
2877 struct inode *inode = file->f_mapping->host;
2878 ssize_t ret;
2879
2880 inode_lock(inode);
2881 ret = generic_write_checks(iocb, from);
2882 if (ret > 0)
2883 ret = __generic_file_write_iter(iocb, from);
2884 inode_unlock(inode);
2885
2886 if (ret > 0)
2887 ret = generic_write_sync(iocb, ret);
2888 return ret;
2889 }
2886行进入generic_write_sync,这里的ret大于零表示有成功提交bio,当然并一定全部提交。继续看这个函数:
2543 static inline ssize_t generic_write_sync(struct kiocb *iocb, ssize_t count)
2544 {
2545 if (iocb->ki_flags & IOCB_DSYNC) {
2546 int ret = vfs_fsync_range(iocb->ki_filp,
2547 iocb->ki_pos - count, iocb->ki_pos - 1,
2548 (iocb->ki_flags & IOCB_SYNC) ? 0 : 1);
2549 if (ret)
2550 return ret;
2551 }
2552
2553 return count;
2554 }
183 int vfs_fsync_range(struct file *file, loff_t start, loff_t end, int datasync)
184 {
185 struct inode *inode = file->f_mapping->host;
186
187 if (!file->f_op->fsync)
188 return -EINVAL;
189 if (!datasync && (inode->i_state & I_DIRTY_TIME)) {
190 spin_lock(&inode->i_lock);
191 inode->i_state &= ~I_DIRTY_TIME;
192 spin_unlock(&inode->i_lock);
193 mark_inode_dirty_sync(inode);
194 }
195 return file->f_op->fsync(file, start, end, datasync);
196 }
在195行可以看到,函数最终调用fsync函数。fsync函数同样由具体的文件系统实现。这里不做详细分析,留待文件系统相关的专门文章说明。
到了这里,其实也就清楚了。
