认识HBase
-
NoSQL与关系型数据库的区别
-
HBase是什么?
-
HBase架构
-
HBase原理
-
HBase写入和读取数据
1. 什么是NoSQL?
- NoSQL的全称是Not Only SQL,这个概念早就有人提出,在09年的时候比较火,NoSQL指的是关系型数据库,而我们常用的都是关系型数据库。就像我们常用的MySQL一样,这些数据库一般用来存储重要信息,应对普通的业务是没有问题的。但是随着互联网的高速发展,传统的关系型数据库在应付超大规模,超大流量,高并发的时候力不从心。在这个时候NoSQL得到长足的发展。
它与关系型数据库的区别
- 存储方式
- 关系型数据库是表格式的,因此存储在表的行和列中。他们之间很容易关联协作存储,提取数据很方便。而NoSQL数据库则与其相反,他是大块的组合在一起。通常存储在数据集中,就像文档,键值对或者图结构
- 存储结构
- 关系型数据库对应的是结构化数据,数据表都预先定义了结构(列的定义),结构描述了数据的形式和内容。这一点对数据建模至关重要,虽然预定义结构带来了可靠性和稳定性,但是修改这些数据比较困难。而NoSQL数据库基于动态结构,使用与非结构化数据。因为NoSQL 数据库是动态结构,可以很容易适应数据类型和结构的变化
- 存储规范
- 关系型数据库的数据存储为了更高的规范性,把数据分割为最小的关系表以避免重复,获得精简的空间利用。虽然管理起来很清晰,但是单个操作设计到多张表的时候,数据管理就显得有点麻烦。而NoSQL 数据存储在平面数据集中,数据经常可能会重复。单个数据库很少被分隔开,而是存储成了一个整体, 这样整块数据更加便于读
- 存储扩展
- 这可能是两者之间最大的区别,关系型数据库是纵向扩展,也就是说想要提高处理能力,要使用速度更快的计算机。因为数据存储在关系表中,操作的性能瓶颈可能涉及到多个表,需要通过提升计算机性能来克服。虽然有很大的扩展空间,但是最终会达到纵向扩展的上限。而NoSQL 数据库是横向扩展的,它的存储天然就是分布式的,可以通过给资源池添加更多的普通数据库服务器来分担负载。
- 查询方式
- 这可能是两者之间最大的区别,关系型数据库是纵向扩展,也就是说想要提高处理能力,要使用速度更快的计算机。因为数据存储在关系表中,操作的性能瓶颈可能涉及到多个表,需要通过提升计算机性能来克服。虽然有很大的扩展空间,但是最终会达到纵向扩展的上限。而NoSQL 数据库是横向扩展的,它的存储天然就是分布式的,可以通过给资源池添加更多的普通数据库服务器来分担负载。
- 事务
- 这可能是两者之间最大的区别,关系型数据库是纵向扩展,也就是说想要提高处理能力,要使用速度更快的计算机。因为数据存储在关系表中,操作的性能瓶颈可能涉及到多个表,需要通过提升计算机性能来克服。虽然有很大的扩展空间,但是最终会达到纵向扩展的上限。而NoSQL 数据库是横向扩展的,它的存储天然就是分布式的,可以通过给资源池添加更多的普通数据库服务器来分担负载。
- 性能
- 关系型数据库为了维护数据的致性付出了巨大的代价,读写性能比较差。在面对高并发读写性能非常差,面对海量数据的时候效率非常低。而NoSQL存储的格式都是key-value类型的,并且存储在内存中,非常容易存储,而且对于数据的一致性是弱要求。NoSQL无需sg!的解析,提高了读写性能。
- 授权方式
- 关系型数据库通常有SQL Server, Mysal, Oracle。 主流的NoSQL数据库有redis,memcache, MongoDb。 大多数的关系型数据库都是付费的并且价格昂贵,成本较大,而NoSQL数据库通常都是开源的。
市场上常见的NoSQL数据库
-
- Redis
- Memcache
- MongoDb
- HBase
2. HBase是什么?
- HBase是建立在Hadoop文件系统之上的分布式面向列的数据库。它是一个 开源项目,是横向扩展的。
HBase是一个 数据模型,类似于谷歌的大表设计(Big Table),可以提供快速随机访问海量结构化数据。
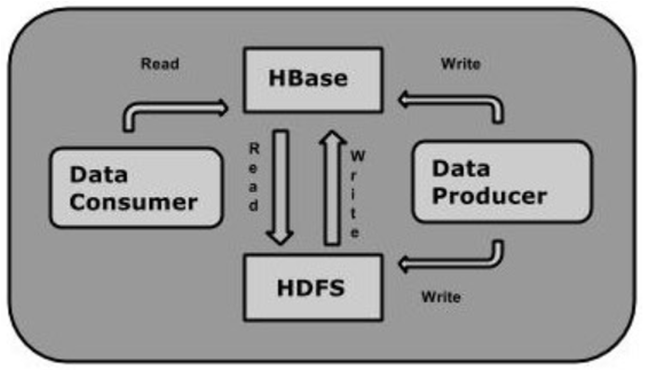
它利用了Hadoop的文件系统(HDFS)提供的容错能力。它是Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的部分。
人们可以直接或通过HBase的存储HDFS数据。使用HBase在HDFS读取消费/随机访问数据。HBase在Hadoop的文件系统之 上,并提供了读写访问。 - HBase的特点
- HBase线性可扩展
- 它具有自动故障支持
- 它提供了一致的读取和写入
- 它集成了Hadoop,作为源和目的地
- 客户端方便的javaAPI
- 它提供了跨集群数据复制
2. HBase架构
HBase是个面向列的数据库, 在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每个列族可以有任意数量的列。 后续列的值连续存储在磁盘上。表中的每个单元格值都具有时间戳。总之,在一个HBase:
-
- 表示行的集合
- 行是列的集合
- 列族是列的集合
- 列是键值对的集合
- 这里说的列式存储或者说面向列,其实就是列族存储,HBase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候必须指定
HBase数据模型示例
-
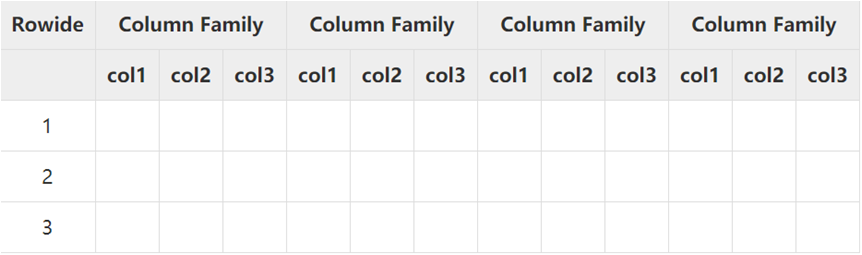
- RowKey(Rowide) 行键
- RowKey是用来表示唯一一行记录的主键,Rowkey行键可以是任意字符串每一行有一个唯一列Row key,必须是唯一的,按照字典序来排序的,按位比较的(有比没有大)
- ColumnsFamily 列族
- 列族:HBase表中的每个列,都归属于某个列族,必须在使用表之前定义。列名都以列族作为前缀。
- Cell 列
- HBase表中唯一确定的单元,cell中的数据时没有类型的,全部是字节码形式存储
- TimeStamp 时间戳
- 每个cell都保存这同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是64整型,时间戳可以有HBASE(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显示赋值。每个cell中,不同版本的数据按照时间倒序排序,最新的排在最前面
-
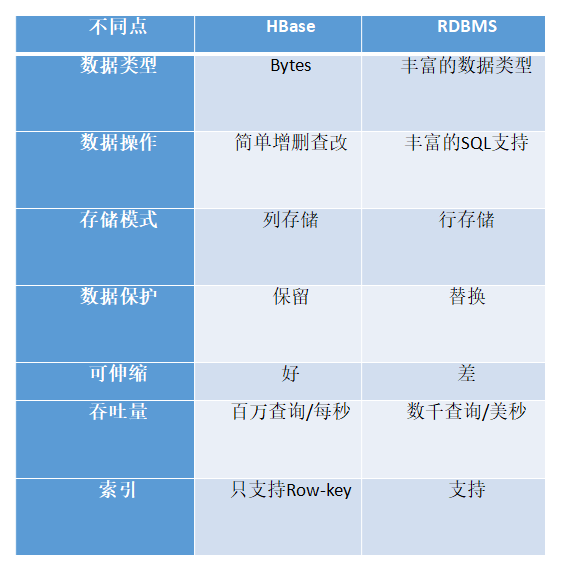
HBase和RDBM(关系型数据库)的比较
-
HBase表模型的要点
- 1、一个表,有表名
2、一个表可以分为多个列族(不同列族的数据会存储在不同文件中)3.表中的每行有个”行键rowkey" ,而且行键在表中不能重复4、表中的每对kv数据称作一个cell
5. hbase可以对数据存储多个历史版本(历史版本数量可配置)
6.整张表由于数据量过大,会被横向切分成若干个region (用rowkey范围标识), 不同region的数据也存储在不同文件中
7. hbase会对插入的数据按顺序存储:
要点一:首先会按行键排序
要点二:同一行里面的kv会按列族排序,再按k排序
- 1、一个表,有表名
3. 执行流行图
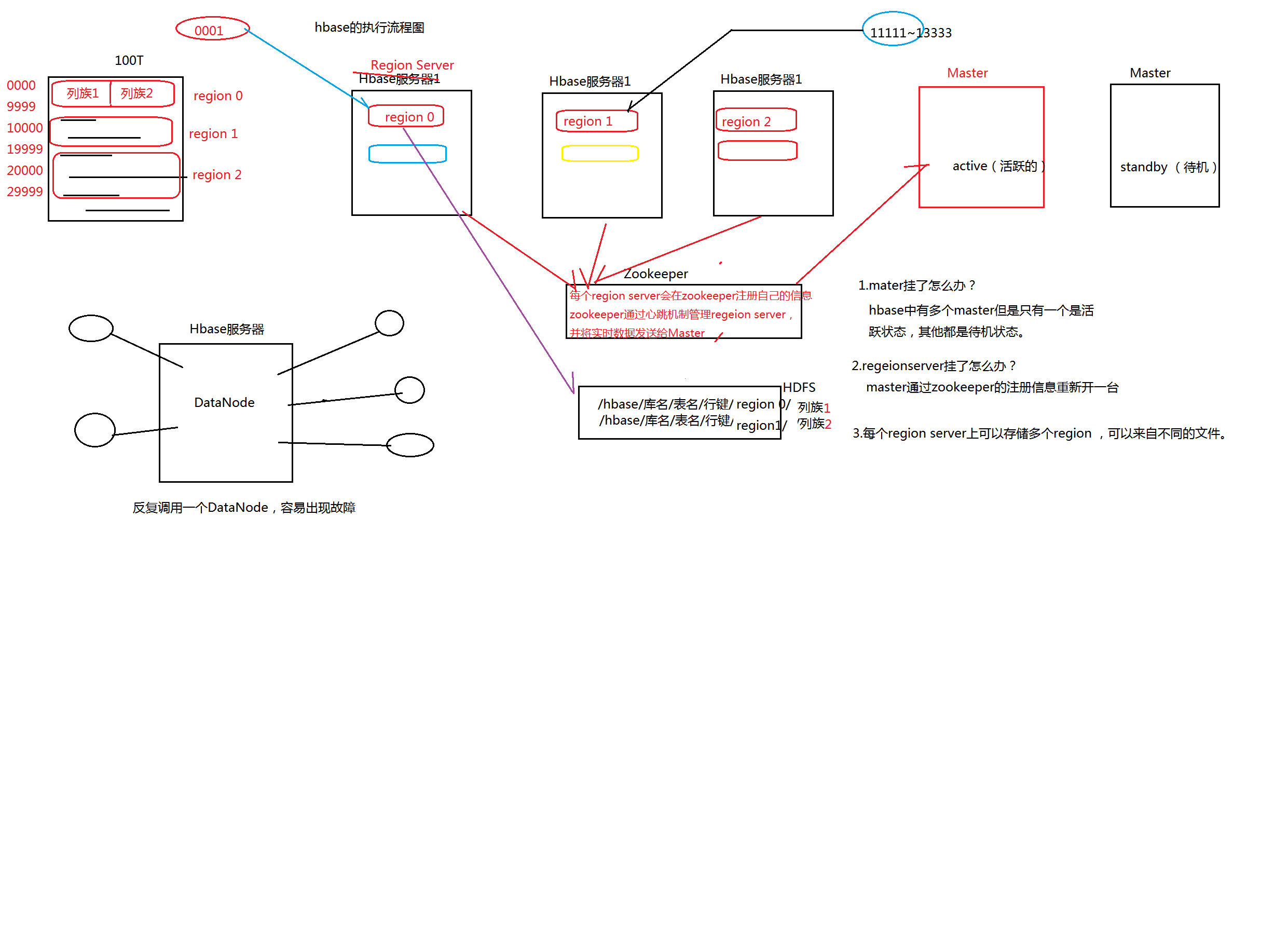
- Client
- 使用HBaseRPC机制与HMAster和HRegionServer进行通信
- Client与HMaster进行管理类操作
- Client与HRegionServer进行数据读写类操作
- Zookeeper
- ZookeeperQuorum存储-ROOT-表地址,HMaster地址
- HRegionServer把自己注册到Zookeeper中,HMaster随时感知各个HRegionServer的健康状况
- Zookeeper避免HMaster单节点问题
- HMaster
- HMaster没有单点问题,HMaster可以启动多个HMaster,通过Zookeeper保证总有一个Master在运行,主要负责:
- 主要负责Table和Region的管理工作
- 管理用户对表的增删改查
- 管理HRegionServer的负载均衡,调整Region分布
- RegionSplit后,负责新Region的分布
- 在HRegionServer停机后,负责失效HRegionServer上Region迁移
- HMaster没有单点问题,HMaster可以启动多个HMaster,通过Zookeeper保证总有一个Master在运行,主要负责:
- HRegionServer
- HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写
- HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写
- Column Family
- 就是一个集中存储单元,将具有相同IO特性的Column放在一个ColumnFamily会更高效
- HStore
- HBase存储的核心。由MemStore和StoreFile组成。MemStore是Stored Memory Buffer
- HLog
- 引入HLog的原因:在分布式环境中,无法避免系统出错或者待机,一旦HRegionServer意外退出,MemStore的内存数据就会丢失,引入HLog就是防止这种情况的发生
- HBase存储什么数据类型
- 只支持byte[]
- 包括了:rowkey,key,value,列族名,表名
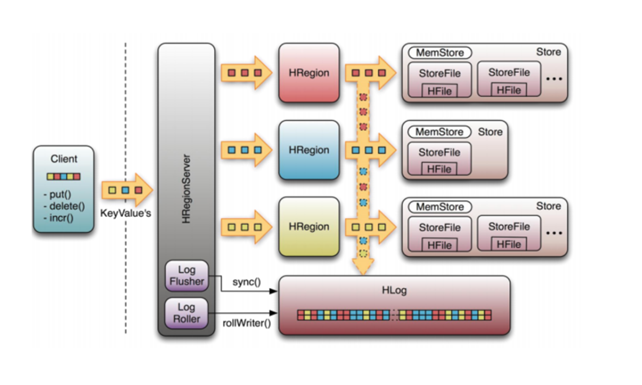
4. HBase写入和读取数据
-
写入操作:
- Client通过Zookeeper的调度,向RegionServer发出写数据请求, 在Region中写数据;
- 数据被写入Region的MemStore,知道MemStore达到预设阀值(即MemStore满);
- MemStore中的数据被Flush成-一个StoreFile;
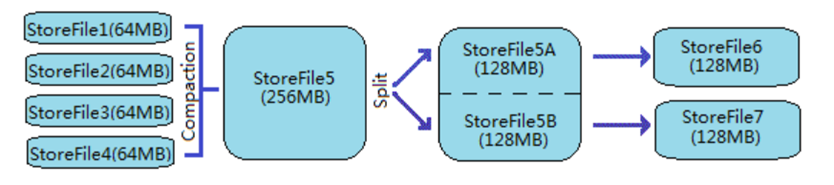
- 随着StoreFile文件的不断增多,当其数量增长到定阀值后,触发Compact合并操作, 将多个StoreFile台并成一个StoreFile, 同时进行版本合并和数据删除;
-
StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile;
-
⑤单个StoreFle大小超过一定祸值后,触发splt操作,把当前Regio Splt成2个新的hReg on。父Region会下线,新 lit出的2个子BReion会被HMlaster分百到相应的Regionsever上,使候
原先1个Region的压力得以分流到2个Region上。
-
读出操作
- Client访问Zookeeper,查找-ROOT-表,获取.META.表信息;
- 从.META.表查找,获取存放目标数据的Region信息,从而找到对应的RegionServer;通过RegionServer获取需要查找的数据;
- 通过RegionServer获取需要查找的数据
- RegionServer的内存分为MemStore和]BlocCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。读请求先到MemStore中查数据
- 寻址过程: client—>Zookeeper—>ROOT表—>.META.表—>RegionServer—>Region—>client