
MR框架-->Combiner组件和Partitioner组件
- 认识Combiner组件和Partitioner组件
- 实例场景
1.Combiner组件:
对比:不使用Combiner,那么所有的结果都是reduce完成,效率相对低下
- 为了进一步提升运算速度,使用Combiner组件,减少MapTasks输出的量及数据网络传输量每一个map可能会产生大量的输出,Combiner的作用就是在map端对输出先做一次合并,减少传输到reducer的数据量
- Combiner最基本是实现本地key的归并,Combiner具有类似本地的reduce功能
2.使用场景:
Combiner的输出是Reducer的输出,Combiner是可插拔的,不会影响最终的计算结果,之应对与那种Reducer的输入key/value与输出key/value类型完全一致。一般是在Mapper和Reducer之间加入Combiner的,一般用于:求和,求次数可以使用,但是不能用于求平均数
//设置reducer相关 job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置combiner组件(效果类似于reduce) job.setCombinerClass(WordCountReducer.class);
3.Partitioner组件:
MapReduce框架中,Mapper的输出的结果是根据内部算法自动分配到不同的Reducer上的,而Partitioner组件是可以决定MapTask输出的数据交由哪个ReduceTask处理的,
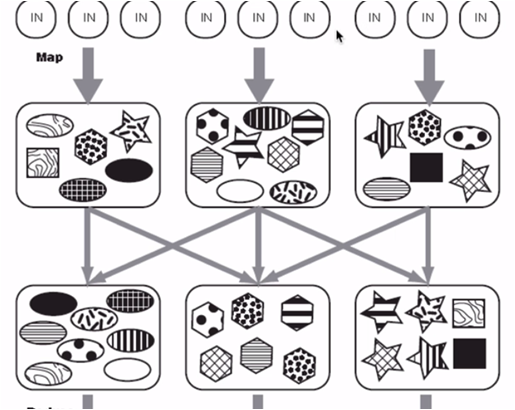
我们可以使用Partitioner对上图进行划分,要写的类如下所示
static class WordCountPartitioner extends Partitioner<Text, IntWritable>{ public int getPartition(Text key, IntWritable value, int arg2) { if(key.toString().equals("java")) {//根据shenm划分 return 0;//第几个区 } if(key.toString().equals("html")) { return 1; } return 2; }
实例:根据名字来进行划分区域和计算值(使用Combiner和Partitioner)
- Mapper类
- Reducer类(和之前没有什么区别)
- Partitioner类
- 提交类
package com.hp.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class wordCountApp { //写一个mapper类 /* * KEYIN 首行偏移量 * VALUEIN 一行数据 * KEYOUT map输出的类 * VALUEOUT map输出的value * MR中的数据类型 * java MR * String Text * int IntWriteable * long LongWiteable */ static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { //读取一行数据 String line = value.toString(); //根据指定规则截取数据 String [] words = line.split(" "); //获取有效数据 for (int i = 0; i < words.length; i++) { //将数据写入上下文 context.write(new Text(words[i]), new IntWritable(1)); } } } static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { //定义空变量 int i = 0 ; //循环累加值 for (IntWritable value : values) { i += value.get(); } //写入上下文 context.write(key, new IntWritable(i)); } } static class WordCountPartitioner extends Partitioner<Text, IntWritable>{ public int getPartition(Text key, IntWritable value, int arg2) { if(key.toString().equals("java")) { return 0; } if(key.toString().equals("html")) { return 1; } return 2; } public static void main(String[] args) throws Exception { //加载配置文件 Configuration config = new Configuration(); //创建job对象 Job job = Job.getInstance(config); //设置提交主类 job.setJarByClass(wordCountApp.class); //设置mapper相关设置提交主类 job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置reducer相关 job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置combiner组件(效果类似于reduce) job.setCombinerClass(WordCountReducer.class); //配置partitioner组件 job.setPartitionerClass(WordCountPartitioner.class); //设置分区个数 job.setNumReduceTasks(3); //设置输入路径 FileInputFormat.setInputPaths(job, new Path("/score.txt")); //设置输出路径 FileOutputFormat.setOutputPath(job, new Path("/ouput10")); //提交任务 job.waitForCompletion(true); } } }

