
MR框架-->初始MR
-
认识Mapreduce
-
Mapreduce编程思想
-
Mapreduce执行流程
-
java版本WordCount实例
1. 简介:
Mapreduce源于Google一遍论文,是谷歌Mapreduce的克隆版,他充分借鉴了分而治之的思想,讲一个数据处理过程拆分为主要的Map(映射)和Reduce(归并)两步,只需要编写map函数和reduce函数即可。
2. Mapreduce优势:
分布式带来了三个复杂:1.程序的分布和启动
2.任务的监控和失败处理
3.中间数据的缓存和调度
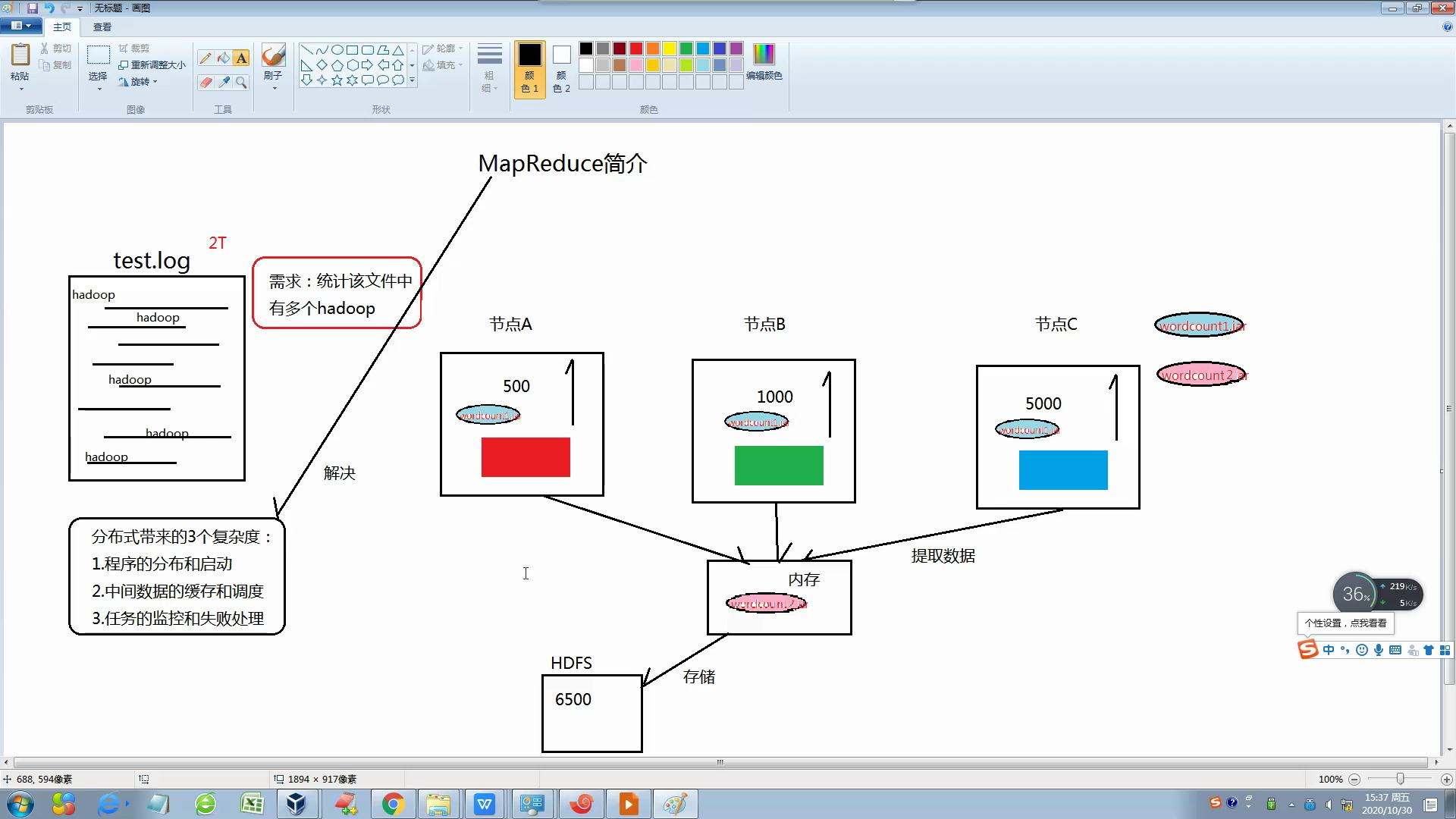
然后Mapreduce是一个并行程序设计模型与方法和好的解决了以上的缺点,并具有:1开发简单
2可扩展性强
3.容错性强
3 Mapreduce的执行流程图:

3-2 Mapreduce的实现过程图:
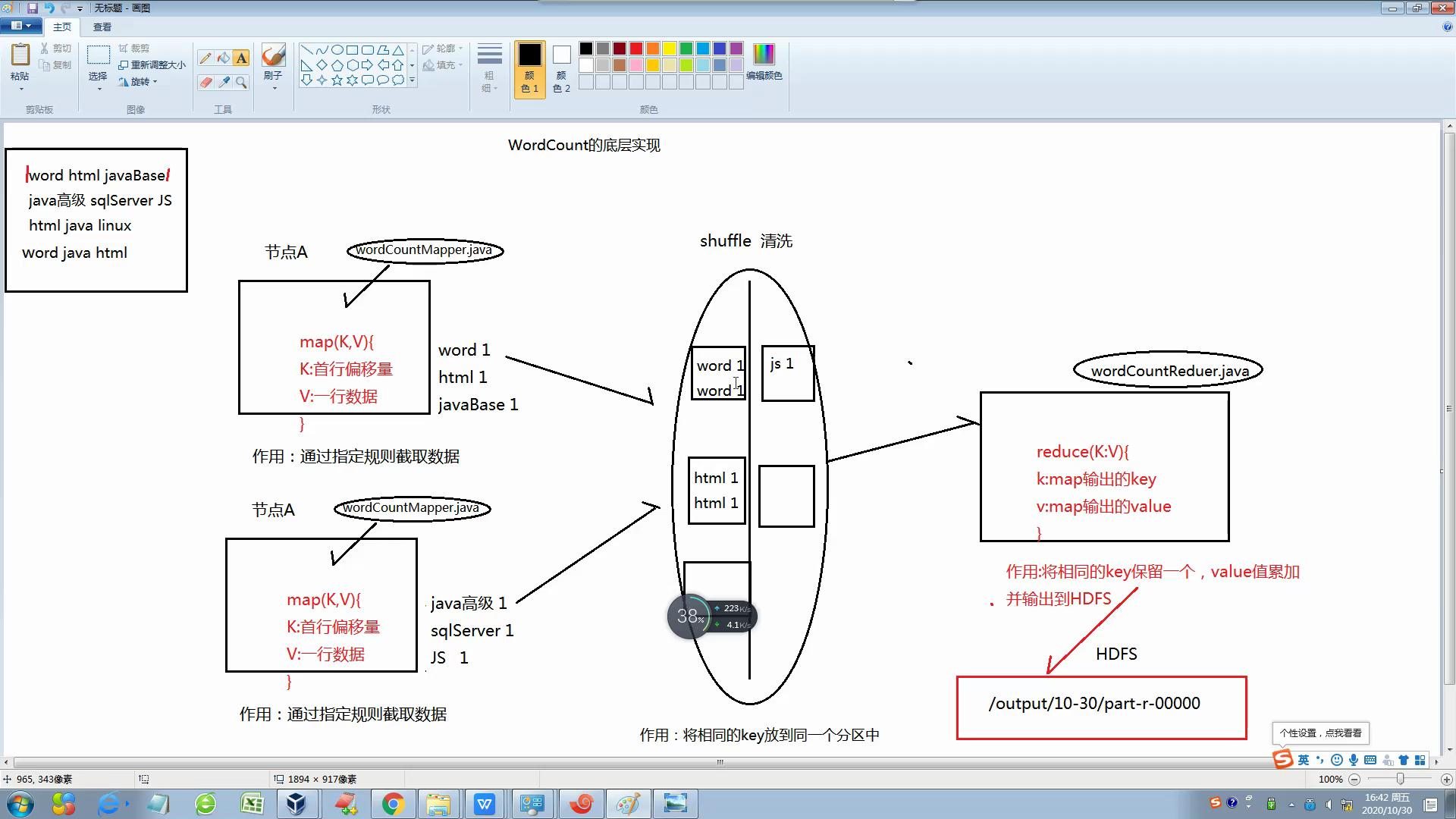
4 基层案例:
- 开发步骤:
- 1.新建项目导入所需的jar包
- 2.编写Mapper类
- 3.编写Reduce类
- 4.提交任务
- 5.观察结果
4-1 Mapper类:继承Mapper类重写map方法在父类中需要定义个泛型,含别4个设置,分别是:KEYIN,VALUEIN,KEYOUT,VALUEOUT
- KEYIN:读入每行文件开头的偏移量(首行偏移量)
- VALUEIN:读入每行文件内容的类型
- KEYOUT:表示Mapper完毕后,输出的文件作为KEY的数据类型
- VALUEOUT:表示Mapper完毕后,输出的文件作为VALUE的数据类型
执行流程:
- 读取一行数据
- 按照规则截取
- 获取有效数据
- 将数据写到上下文中
实例:
public class WordCount { static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { //读取一行数据 String line = value.toString(); //根据指定规则截取数据 String [] words = line.split(" "); //获取有效数据 for (int i = 0; i < words.length; i++) { //将数据写入上下文 context.write(new Text(words[i]), new IntWritable(1)); } } } }
4-2 Reduce类:在写的时候需要继承Reducer类重写ducer方法在父类中需要定义个泛型,含别4个设置,分别是:KEYIN,VALUEIN,KEYOUT,VALUEOUT
- KEYIN:表示从mapper中传递过来的key的数据的数据类型
- VALUEIN:表示从mapper中传递过来的value的数据的数据类型
- KEYOUT:表示Reducer完毕后,输出的文件作为KEY的数据类型
- VALUEOUT:表示Reducer完毕后,输出的文件作为VAKUE的数据类型
执行流程:
- 定义一个空的变量来接受定义的值(累加器)
- 遍历values集合,累加统计
- 将结果写入上下文中
实例:
static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { //定义空变量 int i = 0 ; //遍历values集合,累加统计 for (IntWritable value : values) { i += value.get(); } //写入上下文 context.write(key, new IntWritable(i)); } }
4-3 提交类编写流程:
- 创建Configuration
- 准备清理已存在的输出目录
- 创建Jop
- 设置job的提交类
- 设置mapper相关的类和参数
- 设置reduce相关的类和参数
- 提交任务
实例:
public static void main(String[] args) throws Exception { //加载配置文件 Configuration config = new Configuration(); //创建job对象 Job job = Job.getInstance(config); //设置提交主类 job.setJarByClass(wordCountApp.class); //设置mapper相关设置提交主类 job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置reducer相关 job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置输入路径(必须存在hdfs上) FileInputFormat.setInputPaths(job, new Path("/score.txt")); //设置输出路径 FileOutputFormat.setOutputPath(job, new Path("/ouput10")); //提交任务 job.waitForCompletion(true); }
使用eclipse导出架包,并通关传输软件到LinuX上最后完成上传
