

一、MF介绍
(1)实验的主要任务:使用MF模型在数据集合上的评分预测(movielens,随机80%训练数据,20%测试数据,随机构造 Koren的经典模型)
(2)参考论文:MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS
简单模型:难点在于构造qi与pu,通过![]() 来预测评分rui。在构造qi与pu时,对于每个user或item构造为包含k个特征因子的vector。
来预测评分rui。在构造qi与pu时,对于每个user或item构造为包含k个特征因子的vector。
目标函数为:![]()
(3)部署环境:python37 + pytorch1.3
(4)数据集:Movielen的small数据集,数据集按照8:2的比例进行划分,随机挑选80%的数据当做训练集,剩余的20%当做测试集。(数据下载网址:https://grouplens.org/datasets/movielens/)
(5)代码结构:
进行数据预处理以及数据划分的代码在load_data.py文件中,划分之后得到rating_train.csv与rating_test.csv两个文件(数据集的划分是在抽样之后的数据集ratings_sample.csv上进行划分的)。(data文件夹下的ratings.csv为原始数据集,其中会得到一些中间文件:ratingsNoHead.csv文件为去掉数据集的表头得到的文件;ratings_sample.csv文件为从原始数据中选取1%的数据作为实验数据。)
mf.py文件是读取训练集以及测试集,并使用pytorch框架编写MF训练模型,最后使用rmse作为评价指标,使用测试集对模型进行测试。模型训练过程中采用batch对数据集进行分批训练,最终以曲线的形式展现出来。最终测试集的曲线图如下图所示:
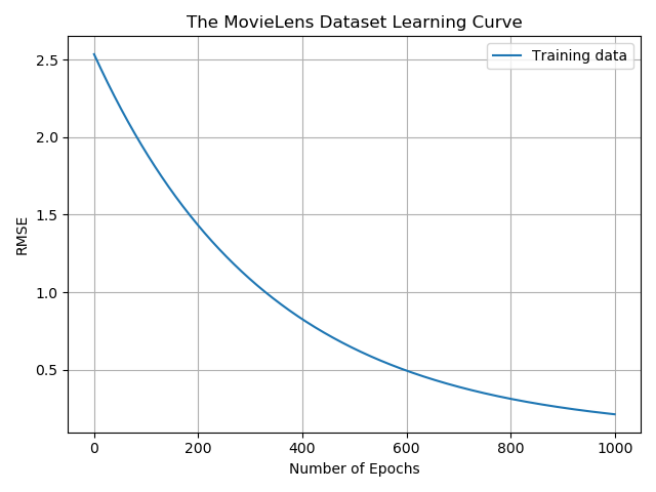
(6)评价标准:采用rmse作为评价指标,使用测试集对模型进行测试。(实验只使用了数据集中的一部分数据,同样也使用了完整的数据集进行了测试,测试误差为0.46。由于数据集较大,这里只上传使用的部分数据集。)训练集与测试集的rmse结果为:
![]()
二、代码
1.代码结构:
2.load_data.py代码:
# coding: utf-8 """ 该文件主要是对数据进行预处理,将评分数据按照8:2分为训练数据与测试数据 """ import pandas as pd import csv import random import os # 删除文件中的表头 origin_f = open('data/ratings.csv','rt',encoding='utf-8',errors="ignore") new_f = open('data/ratingsNoHead.csv','wt+',encoding='utf-8',errors="ignore",newline="") reader = csv.reader(origin_f) writer = csv.writer(new_f) i=0 for i,row in enumerate(reader): if i>0: writer.writerow(row) origin_f.close() new_f.close() #从原始数据集中选取1%作为实验数据 df = pd.read_csv('data/ratingsNoHead.csv', encoding='utf-8') df=df.sample(frac=1.0) #全部打乱 cut_idx=int(round(0.01*df.shape[0])) df_sample=df.iloc[:cut_idx] #将数据存储到csv文件中 df_sample=pd.DataFrame(df_sample) print("sample shape:",df_sample.shape) df_sample.to_csv('data/ratings_sample_tmp.csv',index=False) #去掉第一行 origin_f = open('data/ratings_sample_tmp.csv','rt',encoding='utf-8',errors="ignore") new_f = open('data/ratings_sample.csv','wt+',encoding='utf-8',errors="ignore",newline="") #必须加上newline=""否则会多出空白行 reader = csv.reader(origin_f) writer = csv.writer(new_f) for i,row in enumerate(reader): if i>0: writer.writerow(row) origin_f.close() new_f.close() os.remove('data/ratings_sample_tmp.csv') #将数据按照8:2的比例进行划分得到训练数据集与测试数据集 df = pd.read_csv('data/ratings_sample.csv', encoding='utf-8') # df.drop_duplicates(keep='first', inplace=True) # 去重,只保留第一次出现的样本 # print(df) df = df.sample(frac=1.0) # 全部打乱 cut_idx = int(round(0.2 * df.shape[0])) df_test, df_train = df.iloc[:cut_idx], df.iloc[cut_idx:] # 打印数据集中的数据记录数 print("df shape:",df.shape,"test shape:",df_test.shape,"train shape:",df_train.shape) # print(df_train) # 将数据记录存储到csv文件中 # 存储训练数据集 df_train=pd.DataFrame(df_train) df_train.to_csv('data/ratings_train_tmp.csv',index=False) # 由于一些不知道为什么的原因,使用pandas读取得到的数据多了一行,在存储时也会将这一行存储起来,所以应该删除这一行(如果有时间在查一查看能不能解决这个问题) origin_f = open('data/ratings_train_tmp.csv','rt',encoding='utf-8',errors="ignore") new_f = open('data/ratings_train.csv','wt+',encoding='utf-8',errors="ignore",newline="") #必须加上newline=""否则会多出空白行 reader = csv.reader(origin_f) writer = csv.writer(new_f) for i,row in enumerate(reader): if i>0: writer.writerow(row) origin_f.close() new_f.close() os.remove('data/ratings_train_tmp.csv') # 存储测试数据集 df_test=pd.DataFrame(df_test) df_test.to_csv('data/ratings_test_tmp.csv',index=False) origin_f = open('data/ratings_test_tmp.csv','rt',encoding='utf-8',errors="ignore") new_f = open('data/ratings_test.csv','wt+',encoding='utf-8',errors="ignore",newline="") reader = csv.reader(origin_f) writer = csv.writer(new_f) for i,row in enumerate(reader): if i>0: writer.writerow(row) origin_f.close() new_f.close() os.remove('data/ratings_test_tmp.csv')
3.模型文件mf.py代码:
import pandas as pd import torch as pt import numpy as np import torch.utils.data as Data import matplotlib.pyplot as plt BATCH_SIZE=100 # 读取测试以及训练数据 cols=['user','item','rating','timestamp'] train=pd.read_csv('data/ratings_train.csv',encoding='utf-8',names=cols) test=pd.read_csv('data/ratings_test.csv',encoding='utf-8',names=cols) # 去掉时间戳 train=train.drop(['timestamp'],axis=1) test=test.drop(['timestamp'],axis=1) print("train shape:",train.shape) print("test shape:",test.shape) #userNo的最大值 userNo=max(train['user'].max(),test['user'].max())+1 print("userNo:",userNo) #movieNo的最大值 itemNo=max(train['item'].max(),test['item'].max())+1 print("itemNo:",itemNo) rating_train=pt.zeros((itemNo,userNo)) rating_test=pt.zeros((itemNo,userNo)) for index,row in train.iterrows(): #train数据集进行遍历 rating_train[int(row['item'])][int(row['user'])]=row['rating'] print(rating_train[0:3][1:10]) for index,row in test.iterrows(): rating_test[int(row['item'])][int(row['user'])] = row['rating'] def normalizeRating(rating_train): m,n=rating_train.shape # 每部电影的平均得分 rating_mean=pt.zeros((m,1)) #所有电影的评分 all_mean=0 for i in range(m): #每部电影的评分 idx=(rating_train[i,:]!=0) rating_mean[i]=pt.mean(rating_train[i,idx]) tmp=rating_mean.numpy() tmp=np.nan_to_num(tmp) #对值为NaN进行处理,改成数值0 rating_mean=pt.tensor(tmp) no_zero_rating=np.nonzero(tmp) #numpyy提取非0元素的位置 # print("no_zero_rating:",no_zero_rating) no_zero_num=np.shape(no_zero_rating)[1] #非零元素的个数 print("no_zero_num:",no_zero_num) all_mean=pt.sum(rating_mean)/no_zero_num return rating_mean,all_mean rating_mean,all_mean=normalizeRating(rating_train) print("all mean:",all_mean) #训练集分批处理 loader = Data.DataLoader( dataset=rating_train, # torch TensorDataset format batch_size=BATCH_SIZE, # 最新批数据 shuffle=False # 是否随机打乱数据 ) loader2 = Data.DataLoader( dataset=rating_test, # torch TensorDataset format batch_size=BATCH_SIZE, # 最新批数据 shuffle=False # 是否随机打乱数据 ) class MF(pt.nn.Module): def __init__(self,userNo,itemNo,num_feature=20): super(MF, self).__init__() self.num_feature=num_feature #num of laten features self.userNo=userNo #user num self.itemNo=itemNo #item num self.bi=pt.nn.Parameter(pt.rand(self.itemNo,1)) #parameter self.bu=pt.nn.Parameter(pt.rand(self.userNo,1)) #parameter self.U=pt.nn.Parameter(pt.rand(self.num_feature,self.userNo)) #parameter self.V=pt.nn.Parameter(pt.rand(self.itemNo,self.num_feature)) #parameter def mf_layer(self,train_set=None): # predicts=all_mean+self.bi+self.bu.t()+pt.mm(self.V,self.U) predicts =self.bi + self.bu.t() + pt.mm(self.V, self.U) return predicts def forward(self, train_set): output=self.mf_layer(train_set) return output num_feature=2 #k mf=MF(userNo,itemNo,num_feature) mf print("parameters len:",len(list(mf.parameters()))) param_name=[] params=[] for name,param in mf.named_parameters(): param_name.append(name) print(name) params.append(param) # param_name的参数依次为bi,bu,U,V lr=0.3 _lambda=0.001 loss_list=[] optimizer=pt.optim.SGD(mf.parameters(),lr) # 对数据集进行训练 for epoch in range(1000): optimizer.zero_grad() output=mf(train) loss_func=pt.nn.MSELoss() # loss=loss_func(output,rating_train)+_lambda*(pt.sum(pt.pow(params[2],2))+pt.sum(pt.pow(params[3],2))) loss = loss_func(output, rating_train) loss.backward() optimizer.step() loss_list.append(loss) print("train loss:",loss) #评价指标rmse def rmse(pred_rate,real_rate): #使用均方根误差作为评价指标 loss_func=pt.nn.MSELoss() mse_loss=loss_func(pred_rate,real_rate) rmse_loss=pt.sqrt(mse_loss) return rmse_loss # 测试网络 #测试时测试的是原来评分矩阵为0的元素,通过模型将为0的元素预测一个评分,所以需要找寻评分矩阵中原来元素为0的位置。 prediction=output[np.where(rating_train==0)] #评分矩阵中元素为0的位置对应测试集中的评分 rating_test=rating_test[np.where(rating_train==0)] rmse_loss=rmse(prediction,rating_test) print("test loss:",rmse_loss) plt.clf() plt.plot(range(epoch+1),loss_list,label='Training data') plt.title("The MovieLens Dataset Learning Curve") plt.xlabel('Number of Epochs') plt.ylabel('RMSE') plt.legend() plt.grid() plt.show()
如果有疑问,欢迎留言。

