


1.在anaconda下安装scrapy库
首先打开anaconda prompt命令行输入界面
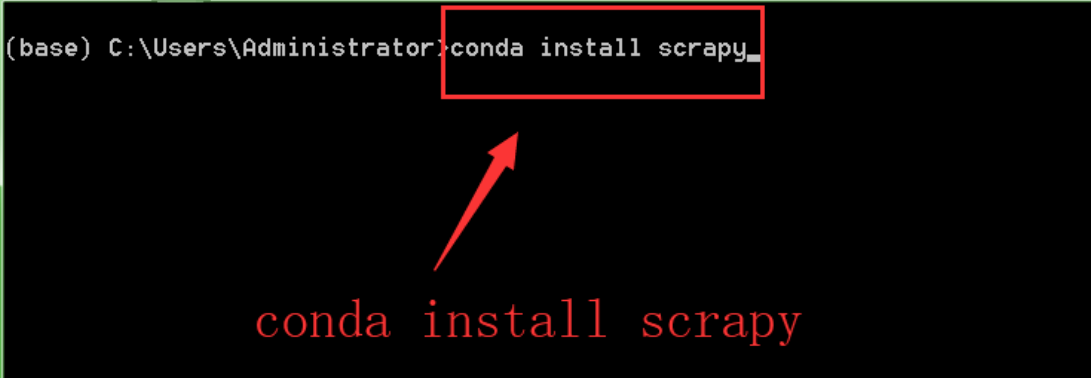
在命令行下输入:
conda install scrapy
输入完成执行该命令后,会进行环境检查.稍等一会:
接着环境监测完成,需要确认继续,输入y
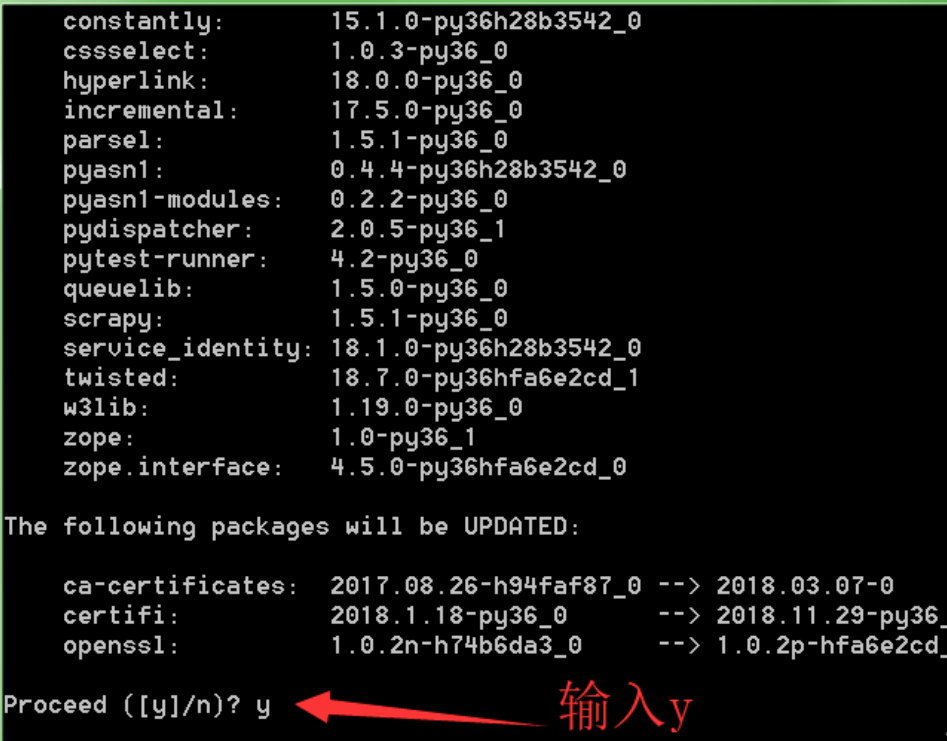
输入y并回车后,自动下载所需文件,等其自动安装。
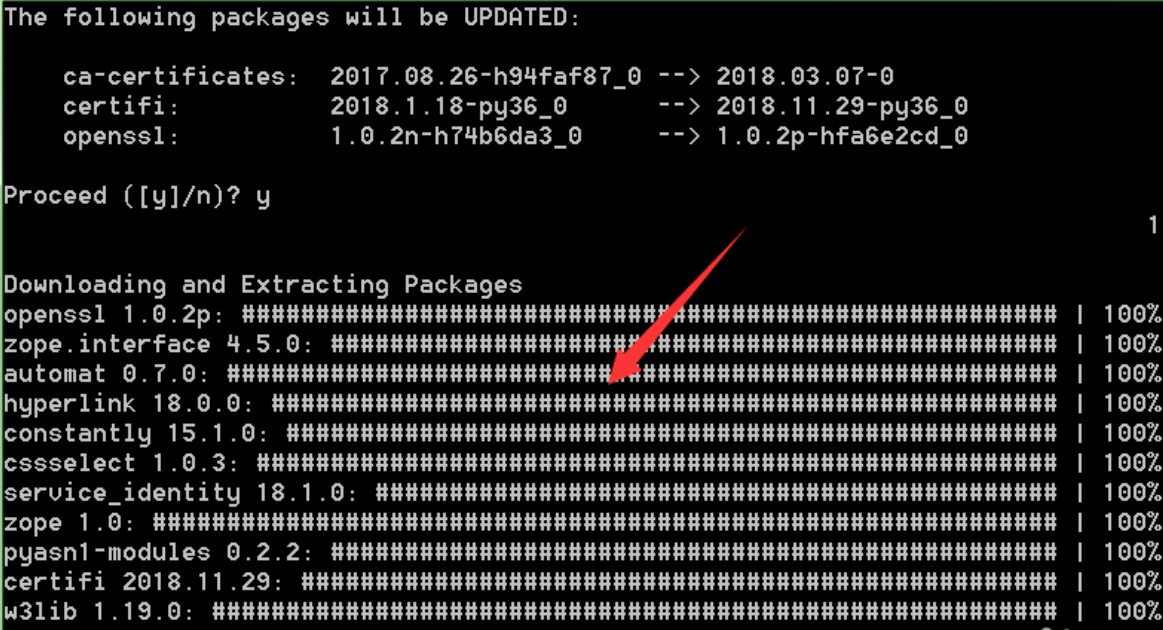
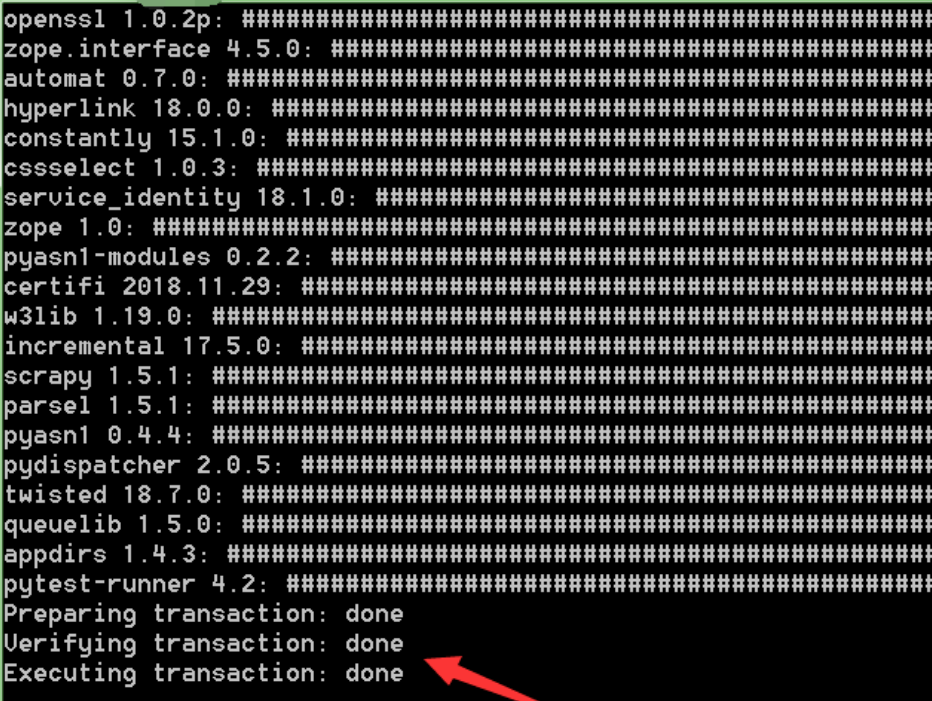
最后,全部组件安装完成后,会有done的标记:
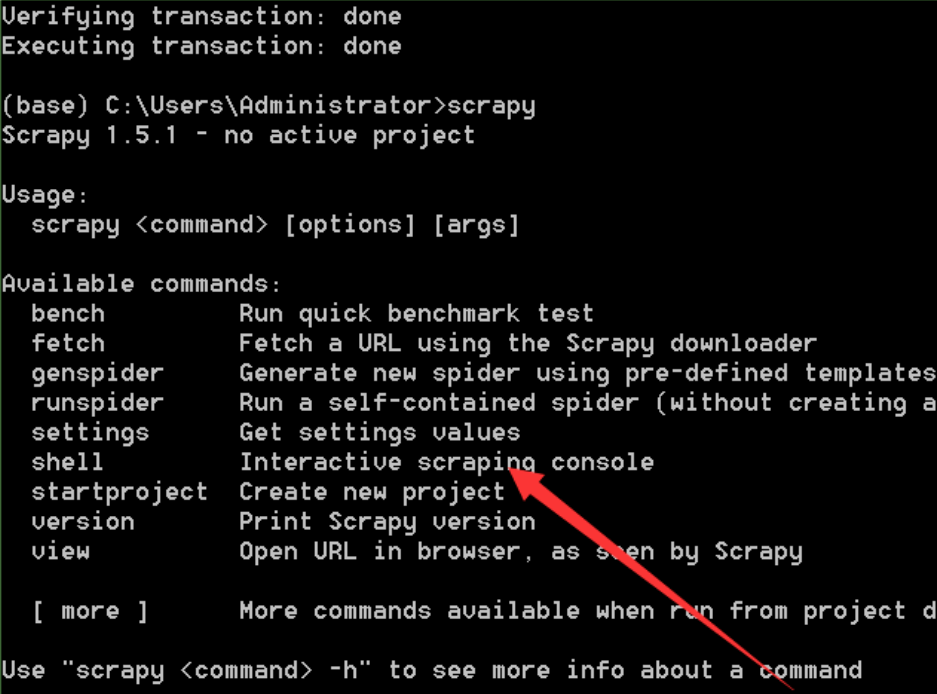
此时键入scrapy会打开下图界面,告知可新建工程,表明安装成功。
这里需要提示的是:当下载包安装时,可能会报如下错误:CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://repo.anaconda.com/pkgs/main/win-64/twisted-19.2.0-py37he774522_0.tar.bz2>,不过不要紧张,是有解决办法的,解决办法可以参考我的博客:
https://i.cnblogs.com/EditPosts.aspx?postid=10858781
2.安装完scrapy库之后就可以新建scrapy工程了,但是要怎样新建工程呢?这里我们采用命令行的形式来创建scrapy工程。
但是要启动哪个命令行工具呢?
(1)之前按照网上的教程在需要新建工程的目录下键入cmd,然后在命令行下输入scrapy startproject 工程名,发现报错。原因是包(import etree)加载失败,找了很久的资料,都没有解决,有博主建议将python3.7换为python3.5版本,但是又不想换版本,怎么解决呢?这里我们就采用第二种方式新建scrapy工程。
(2)同样是打开anaconda prompt命令输入框。在这里我们进入需要新建工程的目录。
我们直接使用cd D:/python命令发现并不能进入到D盘下,解决方案如下:
使用cd ..切换至上级目录,一直到根目录下,才可以由c盘切换至d盘。
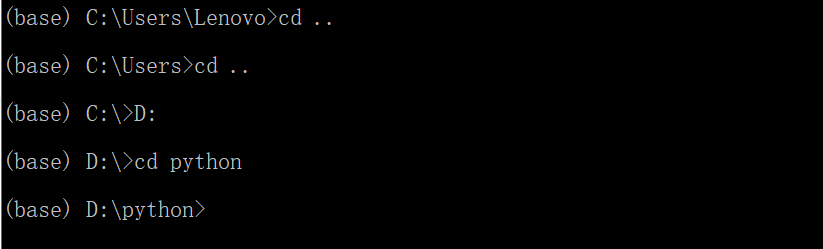
当我们到达了想要新建工程的目录下,在命令行下键入scrapy startproject 工程名就可以新建工程了。

