
Linux 命令
more 分页显示大文本文件
格式:
more [-OPTION] [FILE]
参数:
-f:强制打开特殊文件,如目录或二进制文件
-n:每页行数。(可以理解为每按一下空格,跳转的行数)
+n:从第n行开始显示
-s:将连续空行显示为一行
+/pattern: 搜索字符串(pattern), more的搜索功能好难用,还是用less的吧。
操作:
空格键:下一页
Enter:向下一行
q:退出
less 分页显示大文本文件,支持后退到上一页
格式:
less [-OPTION] [FILE]
参数:
-f:强制打开特殊文件,如目录或二进制文件
-i: 忽略搜索时的大小写
-s:将连续空行显示为一行
-N:显示行号
操作:
空格键:向下滚动一页
Enter:向下滚动一行
pageup:向上滚动一页
pagedown:向下滚动一页
?:向上搜索字符串
/:向下搜索字符串
n:上一个搜索结果
N:下一个搜索结果
more和less区别
1. less可以按键盘上下方向键显示上下内容,more不能通过上下方向键控制显示
2. less不必读整个文件,加载速度会比more更快
3. less退出后shell不会留下刚显示的内容,而more退出后会在shell上留下刚显示的内容
firewall防火墙相关命令
firewall-cmd --state ##查看防火墙状态,是否是running
firewall-cmd --reload ##重新载入配置,比如添加规则之后,需要执行此命令
firewall-cmd --get-zones ##列出支持的zone
firewall-cmd --get-services ##列出支持的服务,在列表中的服务是放行的
firewall-cmd --query-service ftp ##查看ftp服务是否支持,返回yes或者no
firewall-cmd --add-service=ftp ##临时开放ftp服务
firewall-cmd --add-service=ftp --permanent ##永久开放ftp服务
firewall-cmd --remove-service=ftp --permanent ##永久移除ftp服务
firewall-cmd --add-port=80/tcp --permanent ##永久添加80端口
iptables -L -n ##查看规则,这个命令是和iptables的相同的
man firewall-cmd ##查看帮助
systemctl status firewalld.service ##查看防火墙状态
systemctl [start|stop|restart] firewalld.service ##启动|关闭|重新启动 防火墙
##查询端口号80 是否开启
firewall-cmd --query-port=80/tcp
nohup
nohup命令用于不挂断地运行命令(关闭当前session不会中断改程序,只能通过kill等命令删除)。
使用nohup命令提交作业,那么在缺省情况下该作业的所有输出都被重定向到一个名为nohup.out的文件中,除非另外指定了输出文件。
&
&用于后台执行程序,但是关闭当前session程序也会结束
2>&1
bash中:
- /dev/null 表示空设备文件(详解)
- 0 代表STDIN_FILENO 标准输入(一般是键盘),
- 1 代表STDOUT_FILENO 标准输出(一般是显示屏,准确的说是用户终端控制台),
- 2 三代表STDERR_FILENO (标准错误(出错信息输出)。
2>&1就是用来将标准错误2重定向到标准输出1中的。此处1前面的&就是为了让bash将1解释成标准输出而不是文件1。
网络分析 - tcpdump \ telnet \ (netstat \ ss \ lsof) \ nload
netstat
常用参数
-a (all) 显示所有选项,默认不显示LISTEN相关。
-t (tcp) 仅显示tcp相关选项。
-u (udp) 仅显示udp相关选项。
-n 拒绝显示别名,能显示数字的全部转化成数字。
-l 仅列出有在 Listen (监听) 的服务状态。
-p 显示建立相关链接的程序名
-r 显示路由信息,路由表
-e 显示扩展信息,例如uid等
-s 按各个协议进行统计
-c 每隔一个固定时间,执行该netstat命令。
LISTEN和LISTENING的状态只有用-a或者-l才能看到
ss ( Socket Statistics)
ss 命令可以用来获取 socket 统计信息,它显示的内容和 netstat 类似。但 ss 的优势在于它能够显示更多更详细的有关 TCP 和连接状态的信息,而且比 netstat 更快。
-
ss -pl查看每个进程及其监听的端口 -
ss -t -a查看所有的tcp连接 -
ss -u -a查看所有的udp连接
lsof(list open files)
是一个列出当前系统打开文件的工具
命令参数:
-a 列出打开文件存在的进程
-c<进程名> 列出指定进程所打开的文件
-g 列出GID号进程详情
-d<文件号> 列出占用该文件号的进程
+d<目录> 列出目录下被打开的文件
+D<目录> 递归列出目录下被打开的文件
-n<目录> 列出使用NFS的文件
-i<条件> 列出符合条件的进程。(4、6、协议、:端口、 @ip )
-p<进程号> 列出指定进程号所打开的文件
-u 列出UID号进程详情
-h 显示帮助信息
-v 显示版本信息
lsof输出各列信息的意义如下:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE:文件的大小
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
列出谁在使用某个端口
命令:lsof -i :3306
网络传输 - scp \ rsync \ (rz \ sz) \ nc
内存检查 - free \ meminfo
系统监控 - vmstat \ iostat \ top \ ps \ sar \ dstat
top
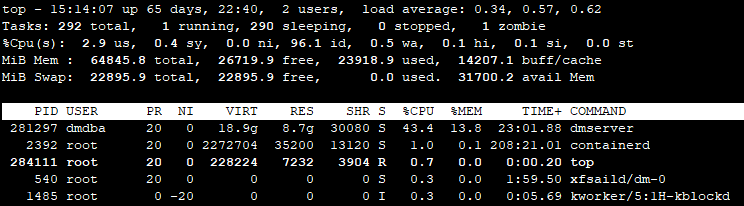
第一行:系统运行信息,显示系统运行当前时间是16:51分,系统运行了34days,当前有2个用户登录,系统平均负载压力情况为0.46(1min的平均负载压力)、0.9.0(5min的平均负载压力)、0.9.0(15min的平均负载压力)
注:load average:每隔5s检查一次活跃的进程数,然后按特定算法计算出来的。一般当这个数值除以CPU的核数得到的值大于3~5时,就标明系统的负载压力已经很高了。
第二行:显示的是任务信息,总共256个进程,1个进程正在执行,255个进程正在休眠,0个进程停止,0个进程假死
第三行:显示的是CPU运行信息,3.5us表示用户模式下CPU占比为3.5%,1.0sy标识系统模式下CPU占比1.0%,0.0ni表示改变过优先级的进程的CPU占比为0.0%,93.3id表示空闲状态的CPU占比为93.3%,2.1wa表示因为I/O等待造成的CPU占用比为2.1%,0.0st表示CPU等待虚拟机调度的时间占比,这个指标一般在虚拟机中才有,在物理机中该值一般为0
第四行:显示的是内存信息,16343540 total显示的是物理内存总量,16144616 used显示已使用的物理内存,198924 free表示空闲物理内存,171348 buffers 表示用于缓存内存大小,以上单位都是kb
第五行:显示虚拟内存使用信息,29355004 total 表示虚拟内存空间总大小,504536 used 表示虚拟内存使用大小,28850468 free 表示空闲虚拟内存,11936408 cached Mem表示缓存虚拟内存,以上单位都是kb
第六行:
列说明
| 序号 | 列名 | 含义 |
|---|---|---|
| a | PID | 进程id |
| b | PPID | 父进程id |
| c | RUSER | Real user name |
| d | UID | 进程所有者的用户id |
| e | USER | 进程所有者的用户名 |
| f | GROUP | 进程所有者的组名 |
| g | TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| h | PR | 优先级 |
| i | NI | nice值。越小优先级越高,最小-20,最大20(用户设置最大19) |
| j | P | 最后使用的CPU,仅在多CPU环境下有意义 |
| k | %CPU | 上次更新到现在的CPU时间占用百分比 |
| l | TIME | 进程使用的CPU时间总计,单位秒 |
| m | TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| n | %MEM | 进程使用的物理内存百分比 |
| o | VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| p | SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb |
| q | RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| r | CODE | 可执行代码占用的物理内存大小,单位kb |
| s | DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| t | SHR | 共享内存大小,单位kb |
| u | nFLT | 页面错误次数 |
| v | nDRT | 最后一次写入到现在,被修改过的页面数 |
| w | S | 进程状态 D:不可中断的睡眠状态 R:运行 S:睡眠 T:跟踪/停止 Z:僵尸进程 |
| x | COMMAND | 命令名/命令行 |
| y | WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| z | Flags | 任务标志,参考 sched.h |
vmstat
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如图没2s采样一次,直到停止
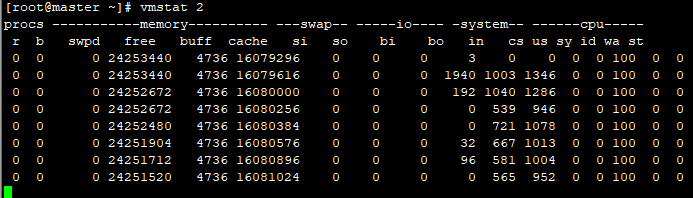
procs
r:运行队列中进程的数量,这些进程都是可运行状态,都在等待CPU的分配
解释:当这个值超过了CPU数目,就会出现CPU瓶颈,如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高
b:被blocked(阻塞)的进程数,正在等待IO
memory
swpd:使用的虚拟内存的大小,单位是KB
解释:如果该值大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器
free:可用的物理内存大小,单位是KB
buff:物理内存用来缓存读写操作的buffer大小,单位是KB
cache:物理内存用来缓存进程地址空间的cache大小,单位是KB
swap
si(换入):每秒从SWAP(交换分区)读入到RAM(swap in)的大小,单位是KB
so(换出):每秒从RAM写出到SWAP(swap out)的大小,单位是KB
解释:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响。有些朋友看到空闲内存(free)很少时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响。
io
bi:每秒从文件系统或SWAP读入到RAM(blocks in)的块数,block(1KB磁盘块)为单位
bo:每秒从RAM写出到文件系统或SWAP(blocks out)的块数,block(1KB磁盘块)为单位
解释:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
system
in:每秒的中断数
cs:系统每秒进行上下文切换的次数
解释:cs表示每秒上下文切换的次数,例如,当我们调用系统函数,就要进行上下文切换;当进行线程的切换,也要进行上下文切换,这个值越小越好。例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程或线程数就是比较合适的值了。系统调用也是如此,每次调用系统函数,我们的代码就会进入到内核空间(内核态),导致上下文切换,这个过程很耗资源,所以要尽量避免频繁的系统调用。上下文切换次数过多表示你的CPU大部分时间浪费在上下文切换中,导致CPU干正经事的时间少了。
cpu
us:用户空间占用CPU的百分比
解释:us的值比较高时,说明用户进程消耗的CPU时间比较多,但是如果长期超过50%,那么我们就该考虑优化程序算法或者进行加速。
sy:内核空间占用CPU的百分比
解释:sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
id:CPU空闲的百分比
wa:CPU等待IO的百分比
解释:wa的值高时,说明CPU等待IO的时间比较多,这可能是大量的磁盘随机访问造成的,也有可能是磁盘出现瓶颈。
st:来自于虚拟机偷取的CPU所占的百分比
系统调用追踪 - strace \ gcore
文件相关 - find \ awk \ sed \ grep \ tail \ df \ du \ locate
awk
https://blog.csdn.net/bocai8058/article/details/82934177
du
disk usage,是通过搜索文件来计算每个文件的大小,然后累加,du能看到的文件只是一些当前存在的,没有被删除的。他计算的大小就是,当前他认为存在的所有文件大小的累加和。
du [-ahskm] 文件或目录名称
常用参数
-s : 列出总量而已,而不列出每个个别的目录占用容量 !!!!
-h : 以易读的方式(G/M)显示
-a : 列出所有的文件与目录容量,默认仅统计目录下的文件量
-S: 不包括目录下的总计,与-s 有差别
-k: 以KB列出容量显示
-m: 以MB列出容量显示
–exclude=<目录或文件> 略过指定的目录或文件
–max-depth=<目录层数> 超过指定层数的目录后,予以忽略
例:
1.查看当前目录下user目录的大小,并不想看其他目录以及其子目录:
du -sh user
-s表示总结的意思,即只列出一个总结的值
du -h --max-depth=0 user
–max-depth=n表示只深入到第n层目录,此处设置为0,即表示不深入到子目录
2.列出当前目录中的目录名不包括xyz字符串的目录的大小:
du -h --exclude=‘xyz’
3.查看各文件夹大小:du -h --max-depth=1
df
disk free,通过文件系统来快速获取空间大小的信息。当我们删除一个文件的时候,这个文件不是马上就在文件系统当中消失了,而是暂时消失了,当所有程序都不用时,才会根据OS的规则释放掉已经删除的文件。 df记录的是通过文件系统获取到的文件的大小,他比du强的地方就是能够看到已经删除 的文件,而且计算大小的时候,把这一部分的空间也加上了,更精确了。
df [-ahikHTm] [目录或者文件夹]
参数:
-h : 以交较易识别的方式展示使用量 1111000KB -> XXXMB , 默认以KB的方式显示
-i : 不使用磁盘容量,用inode 的数量来显示
-a : 列出所有的文件系统, 包括系统特有的 /proc 等文件系统
-k : 以KB的容量显示 文件系统 (默认)
-m: 以MB的容量显示 文件系统
-H : 以 1000的进制代替1024的进制方式
-T : 连同该分区的文件系统的名称(ext3)等也列出
开发效率 - tmux
service network restart 重启网卡
dd
用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。
参数注释:
- if=文件名:输入文件名,缺省为标准输入。即指定源文件。< if=input file >
- of=文件名:输出文件名,缺省为标准输出。即指定目的文件。< of=output file >
- ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。
obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。
bs=bytes:同时设置读入/输出的块大小为bytes个字节。 - cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
- skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
- seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
注意:通常只用当输出文件是磁盘或磁带时才有效,即备份到磁盘或磁带时才有效。 - count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
- conv=conversion:用指定的参数转换文件。
- ascii:转换ebcdic为ascii
- ebcdic:转换ascii为ebcdic
- ibm:转换ascii为alternate ebcdic
- block:把每一行转换为长度为cbs,不足部分用空格填充
- unblock:使每一行的长度都为cbs,不足部分用空格填充
- lcase:把大写字符转换为小写字符
- ucase:把小写字符转换为大写字符
- swab:交换输入的每对字节
- noerror:出错时不停止
- notrunc:不截短输出文件
- sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
实例:
1.将本地的/dev/hdb整盘备份到/dev/hdd dd if=/dev/hdb of=/dev/hdd
2.销毁磁盘数据 dd if=/dev/urandom of=/dev/hda1 ( /dev/urandom 生成随机数据 详细说明 )
历史命令使用技巧
!!:重复执行上条命令;!N:重复执行 history 历史中第 N 条命令,N 可以通过 history 查看;!pw:重复执行最近一次,以pw开头的历史命令,这个非常有用,小编使用非常高频;!$:表示最近一次命令的最后一个参数;
!$ 使用例子
$ vim /root/sniffer/src/main.c $ mv !$ !$.bak # 相当于 $ mv /root/sniffer/src/main.c /root/sniffer/src/main.c.bak
快速搜索历史命令 Ctrl + r
sort
可针对文本文件的内容,以行为单位来排序。
语法
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件][-k field1[,field2]]
参数说明:
- -b 忽略每行前面开始出的空格字符。
- -c 检查文件是否已经按照顺序排序。
- -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f 排序时,将小写字母视为大写字母。
- -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m 将几个排序好的文件进行合并。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。
- -u 意味着是唯一的(unique),输出的结果是去完重了的。
- -o<输出文件> 将排序后的结果存入指定的文件。
- -r 以相反的顺序来排序。
- -t<分隔字符> 指定排序时所用的栏位分隔字符。
- +<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- --help 显示帮助。
- --version 显示版本信息。
- [-k field1[,field2]] 按指定的列进行排序。
sort 参数 详解:https://www.cnblogs.com/51linux/archive/2012/05/23/2515299.html

