
你真的了解【HashMap】么?-二
1、currentHashMap内部结构
(1)在JDK1.7版本中,CurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,每一个HashEntry可以看成一个HashMap(数组+链表)
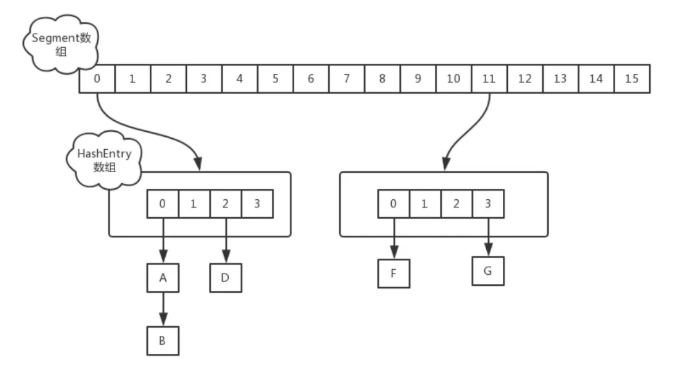
实现并发原理:
(2)在JDK1.8版本中,摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现(和HashMap数据结构一样),同时值value和next采用了volatile去修饰,保证了可见性;实现了有序性(禁止进行指令重排序);volatile 只能保证对单次读/写的原子性,i++ 这种操作不能保证原子性。

实现并发原理:
抛弃了原有的 Segment 分段锁,而采用了 CAS + Synchronized 来保证并发安全性
CAS(compare and swap)的缩写,也就是我们说的比较交换,CAS 是乐观锁的一种实现方式,是一种轻量级锁,java的锁中分为乐观锁和悲观锁:
悲观锁是指将资源锁住,等待当前占用锁的线程释放掉锁,另一个线程才能够获取锁,访问资源
乐观锁是通过某种方式不加锁,比如说添加version字段来获取数据
CAS操作包含三个操作数(内存位置,预期的原值,和新值)。如果内存的值和预期的原值是一致的,那么就转化为新值, CAS 是通过不断的循环来获取新值的,如果线程中的值被另一个线程修改了,那么线程就需要自旋,到下次循环才有可能执行 。
CAS缺点:
(1)ABA问题
CAS对于ABA问题无法判断是否有线程修改过数据(ABA问题:原始数据A,线程1将其修改为B,线程2又将其修改为A),其实很多场景如果只追求最后结果正确,这是没有影响,但是实际过程中还是需要记录修改过程的,比如资金修改,你每次修改的都应该有记录,方便回溯;
解决:修改前去查询他原来的值的时候再带一个版本号或者时间戳,判断成功后更新版本号或者时间戳
(2)循环时间长开销大
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销
(3) 只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,
这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作
2、currentHashMap的put、get、size方法
JDK1.7
get方法:不需要加锁,非常高效,只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
put方法:需要加锁,虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以需要加锁(在 put 之前会进行一次扩容校验,HashMap是插入元素之后再看是否需要扩容,有可能扩容之后后续就没有插入操作了)
size方法:累加每个Segment的count值,因为是并发操作,在你计算size的时候,他还在并发的插入数据,可能会导致你计算出来的size和你实际的size有相差,1.7中有两种解决方案
2、如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回
JDK1.8
get方法:根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值,如果是红黑树那就按照树的方式获取值,都不满足那就按照链表的方式遍历获取值
put方法:
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
- 根据当前 key 定位出对应 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 - 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于
TREEIFY_THRESHOLD则要转换为红黑树
size方法:对于size的计算,在扩容和addCount()方法就已经有处理了,只需要对 baseCount 和 counterCell 进行 CAS 计算,最终通过 baseCount 和 遍历 CounterCell 数组得出 size
3、扩容
JDK1.7
在Segment的锁的保护下进行扩容的,不需要关注并发问题
Segment 数组不能扩容,对segment数组中某一个HashEntry数组进行扩容,扩大为原来的2倍
先对数组的长度增加一倍,然后遍历原来的旧的table数组,把每一个数组元素也就是Node链表迁移到新的数组里面,最后迁移完毕之后,把新数组的引用直接替换旧的
JDK1.8
扩容支持并发迁移节点,每个线程获取一部分桶的迁移任务,如果当前线程的任务完成,查看是否还有未迁移的桶,若有则继续领取任务执行,若没有则退出。在退出时需要检查是否还有其他线程在参与迁移工作,如果有则自己什么也不做直接退出,如果没有了则执行最终的收尾工作;
从old数组的尾部开始,如果该桶被其他线程处理过了,就创建一个 ForwardingNode 放到该桶的首节点,hash值为-1,其他线程判断hash值为-1后就知道该桶被处理过了
4、1.8为什么用synchronized
1.因为锁的粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了。
2.在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据。
3.对于synchronized 获取锁的方式,JVM 使用了锁升级的优化方式,就是先使用偏向锁优先同一线程然后再次获取锁,如果失败,就升级为 CAS 轻量级锁,如果失败就会短暂自旋,防止线程被系统挂起。最后如果以上都失败就升级为重量级锁
感谢
参考:

