
第十一周总结
数据汇总
透视表功能

pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
data:指定需要构造透视表的数据集
values:指定需要拉入“数值”框的字段列表
index:指定需要拉入“行标签”框的字段列表
columns:指定需要拉入“列标签”框的字段列表
aggfunc:指定数值的统计函数,默认为统计均数,也可以指定numpy模块中的其他统计函数
fill_value:指定一个标量,用于填充缺失值
margins:bool类型参数,是否需要显示行或列的总计值,默认为False
dropna:bool类型参数,是否需要删除整列为缺失的字段,默认为True
margins_name:指定行或列的总计名称,默认为ALL
分组与聚合
import numpy as np
# 通过groupby方法,指定分组变量
grouped = data06.groupby(by = ['color','cut'])
# 对分组变量进行统计汇总
result = grouped.aggregate({'color':np.size, 'carat':np.min,
'price':np.mean, 'table':np.max})
调整变量名的顺序
result = pd.DataFrame(result, columns=['color','carat','price','table'])
数据集重命名
result.rename(columns={'color':'counts',
'carat':'min_weight',
'price':'avg_price',
'table':'max_table'},
inplace=True)
处理列字段名称
drop方法使用
针对冠军字段分组
champion.groupby('冠军').groups
获取分组之后的各分组大小
champion.groupby('冠军').size()
获取各组冠军次数
champion.groupby('冠军').size().sort_values(ascending=False) # 升序
分组字段可以一次性取多个
champion.groupby(['冠军', 'FMVP']).size()
数据的合并
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None)
objs:指定需要合并的对象,可以是序列,数据框或面板数据构成的列表
axis:指定数据合并的轴,默认为0,表示合并多个数据的行,如果为1,就表示合并多个数据的列
join:指定合并的方式,默认为outer,表示合并所有数据,如果改为inner,表示合并公共部分的数据
join_axes:合并数据后,指定保留的数据轴
ignore_index:bool类型的参数,表示是否忽略原数据集的索引,默认为False,如果设为True,就表示忽略原索引,用于区分各个数据部分
数据的连接
pd.merge(left,
right,
how='inner',
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False,
sort=False,
suffixes=('_x', '_y'))
left:指定需要连接的主表,right:指定需要连接的辅表
how:指定连接方式,默认为inner内连,还有其他选项,比如左连left,右连right和外链outer on:指定连接两张表的共同字段
left_on:指定主表中需要连接的共同字段
right_on:指定辅表中需要连接的共同字段
left_index:bool类型参数,是否将主表中的行索引用作表连接的共同字段,默认为False
right_index:bool类型参数,是否将辅表中的行索引用作表连接的共同字段,默认为False
sort:bool类型参数,是否对连接后的数据按照共同字段排序,默认为False
suffixes:如果数据连接的结果中存在重叠的变量名,则使用各自的前缀进行区分
matplotlib简介
是一个强大的python绘图和数据可视化工具包,数据可视化也是我们数据分析重要环节之一,可以帮助我们分析出很多价值信息,也是数据分析的最后一个可视化阶段
下载
python纯开发环境下
pip3 install matplotlib
anaconda环境下
conda install matplotlib
(anaconda已经自动帮助我们下载好了数据分析相关的模块,其实无需我们再下载)
导入
import matplotlib.pyplot as plt
解决作图乱码
jupyter 画图轴标题不显示中文(显示方框)_singghet的博客-CSDN博客
文件这里面有:C:\Windows\Fonts
matplotlib绘图
import matplotlib.pyplot as plt
饼图 plt.pie
垂直条形图 plt.bar
水平条形图 plt.barh
直方图 plt.hist
箱线图 plt.boxplot
折线图 plt.plot
散点图 plt.scatter
组合图 plt.subplot2grid
import seaborn as sns
热力图 sns.heatmap
以弹框的形式显示图形 %matplotlib
饼图的绘制
pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, labeldistance=1.1)
x:指定绘图的数据
explode:指定饼图某项部分的突出显示,即呈现爆炸式
labels:为饼图添加标签说明,类似于图例说明
colors:指定饼图的填充色
autopct:自动添加百分比显示,可以采用格式化的方法显示
pctdistance:设置百分比标签与圆心的距离
labeldistance:设置各扇形标签(图例)与圆心的距离
条形图的绘制
bar(x, height, width=0.8, bottom=None, color=None, edgecolor=None, tick_label=None, label = None, ecolor=None)
x:传递数值序列,指定条形图中x轴上的刻度值
height:传递数值序列,指定条形图y轴上的高度
width:指定条形图的宽度,默认为0.8
bottom:用于绘制堆叠条形图
color:指定条形图的填充色
edgecolor:指定条形图的边框色
tick_label:指定条形图的刻度标签
label:指定条形图的标签,一般用以添加图例
垂直条形图
import pandas as pd
import matplotlib.pyplot as plt
# 读入数据
GDP = pd.read_excel(r'Province GDP 2017.xlsx')
# 设置绘图风格(不妨使用R语言中的ggplot2风格)
plt.style.use('ggplot')
# 绘制条形图
plt.bar(x = range(GDP.shape[0]), # 指定条形图x轴的刻度值
height = GDP.GDP, # 指定条形图y轴的数值
tick_label = GDP.Province, # 指定条形图x轴的刻度标签
color = 'steelblue', # 指定条形图的填充色
)
# 添加y轴的标签
plt.ylabel('GDP(万亿)')
# 添加条形图的标题
plt.title('2017年度6个省份GDP分布')
# 为每个条形图添加数值标签
for x,y in enumerate(GDP.GDP):
plt.text(x,y+0.1,'%s' %round(y,1),ha='center')
# 显示图形
plt.show()
水平条形图
# 对读入的数据做升序排序
GDP.sort_values(by = 'GDP', inplace = True)
# 绘制条形图
plt.barh(y = range(GDP.shape[0]), # 指定条形图y轴的刻度值
width = GDP.GDP, # 指定条形图x轴的数值
tick_label = GDP.Province, # 指定条形图y轴的刻度标签
color = 'steelblue', # 指定条形图的填充色
)
# 添加x轴的标签
plt.xlabel('GDP(万亿)')
# 添加条形图的标题
plt.title('2017年度6个省份GDP分布')
# 为每个条形图添加数值标签
for y,x in enumerate(GDP.GDP):
plt.text(x+0.1,y,'%s' %round(x,1),va='center')
# 显示图形
plt.show()
交叉条形图
HuRun = pd.read_excel('HuRun.xlsx')
# Pandas模块之水平交错条形图
HuRun_reshape = HuRun.pivot_table(index = 'City', columns='Year',
values='Counts').reset_index()
# 对数据集降序排序
HuRun_reshape.sort_values(by = 2016, ascending = False, inplace = True)
HuRun_reshape.plot(x = 'City', y = [2016,2017], kind = 'bar',
color = ['steelblue', 'indianred'],
# 用于旋转x轴刻度标签的角度,0表示水平显示刻度标签
rot = 0,
width = 0.8, title = '近两年5个城市亿万资产家庭数比较')
# 添加y轴标签
plt.ylabel('亿万资产家庭数')
plt.xlabel('')
plt.show()

直方图的绘制
直方图一般用来观察数据的分布形态,一般都会与核密度图搭配使用,目的是更加清楚地掌握数据的分布特征
plt.hist(x, bins=10, normed=False, orientation='vertical', color=None, label=None)
x:指定要绘制直方图的数据
bins:指定直方图条形的个数
normed:是否将直方图的频数转换成频率
orientation:设置直方图的摆放方向,默认为垂直方向
color:设置直方图的填充色
edgecolor:设置直方图边框色
label:设置直方图的标签,可通过legend展示其图例
Titanic = pd.read_csv('titanic_train.csv')
# 检查年龄是否有缺失(如果数据中存在缺失值,将无法绘制直方图)
any(Titanic.Age.isnull())
# 不妨删除含有缺失年龄的观察
Titanic.dropna(subset=['Age'], inplace=True)
# 绘制直方图
plt.hist(x = Titanic.Age, # 指定绘图数据
bins = 20, # 指定直方图中条块的个数
color = 'steelblue', # 指定直方图的填充色
edgecolor = 'black' # 指定直方图的边框色
)
# 添加x轴和y轴标签
plt.xlabel('年龄')
plt.ylabel('频数')
# 添加标题
plt.title('乘客年龄分布')
# 显示图形
plt.show()

箱线图的绘制
箱线图是另一种体现数据分布的图形,通过该图可以得知数据的下须值(Q1-1.5IQR)、下四 分位数(Q1)、中位数(Q2)、均值、上四分位(Q3)数和上须值(Q3+1.5IQR),更重要的是,箱线图还可以发现数据中的异常点;
plt.boxplot(x, vert=None, whis=None, patch_artist=None, meanline=None, showmeans=None, showcaps=None, showbox=None, showfliers=None, boxprops=None, labels=None, flierprops=None, medianprops=None, meanprops=None, capprops=None, whiskerprops=None)
x:指定要绘制箱线图的数据
vert:是否需要将箱线图垂直摆放,默认垂直摆放
whis:指定上下须与上下四分位的距离,默认为1.5倍的四分位差
patch_artist:bool类型参数,是否填充箱体的颜色,默认为False
meanline:bool类型参数,是否用线的形式表示均值,默认为False
showmeans:bool类型参数,是否显示均值,默认为False
showcaps:bool类型参数,是否显示箱线图顶端和末端的两条线(即上下须),默认为True
showbox:bool类型参数,是否显示箱线图的箱体,默认为True
showfliers:是否显示异常值,默认为True
boxprops:设置箱体的属性,如边框色,填充色等
labels:为箱线图添加标签,类似于图例的作用
filerprops:设置异常值的属性,如异常点的形状,大小,填充色等
medianprops:设置中位数的属性,如线的类型,粗细等
meanprops:设置均值的属性,如点的大小,颜色等
capprops:设置箱线图顶端和末端线条的属性,如颜色,粗细等
whiskerprops:设置须的属性,如颜色,粗细,线的类型等
Sec_Buildings = pd.read_excel('sec_buildings.xlsx')
# 绘制箱线图
plt.boxplot(x = Sec_Buildings.price_unit, # 指定绘图数据
patch_artist=True, # 要求用自定义颜色填充盒形图,默认白色填充
showmeans=True, # 以点的形式显示均值
boxprops = {'color':'black','facecolor':'steelblue'},# 设置箱体属性,如边框色和填充色
# 设置异常点属性,如点的形状、填充色和点的大小
flierprops = {'marker':'o','markerfacecolor':'red', 'markersize':3,'markeredgecolor':'red'},
# 设置均值点的属性,如点的形状、填充色和点的大小
meanprops = {'marker':'D','markerfacecolor':'indianred', 'markersize':4},
# 设置中位数线的属性,如线的类型和颜色
medianprops = {'linestyle':'--','color':'orange'},
labels = [''] # 删除x轴的刻度标签,否则图形显示刻度标签为1
)
# 添加图形标题
plt.title('二手房单价分布的箱线图')
# 显示图形
plt.show()

折线图的绘制
对于时间序列数据而言,一般都会使用折线图反应数据背后的趋势
通常折线图的横坐标指代如期数据,纵坐标代表某个数值型变量,当然还可以使用第三个离散变量对折线图进行分组处理
plt.plot(x,
y, linestyle, linewidth, color, marker, markersize, markeredgecolor, markerfactcolor, markeredgewidth, label, alpha)
x:指定折线图的x轴数据
y:指定折线图的y轴数据
linestyle:指定折线图的类型,可以是实线,虚线,点虚线,点点线等,默认为实线
linewidth:指定折线的宽度
marker:可以为折线图添加点,该参数是设置点的形状
markersize:设置点的大小
markeredgecolor:设置点的边框色
markerfactcolor:设置点的填充色
markeredgewidth:设置点的边框宽度
label:为折线图添加标签,类似于图例的作用
# 数据读取
wechat = pd.read_excel(r'wechat.xlsx')
# 绘制单条折线图
plt.plot(wechat.Date, # x轴数据
wechat.Counts, # y轴数据
linestyle = '-', # 折线类型
linewidth = 2, # 折线宽度
color = 'steelblue', # 折线颜色
marker = 'o', # 折线图中添加圆点
markersize = 6, # 点的大小
markeredgecolor='black', # 点的边框色
markerfacecolor='brown') # 点的填充色
# 获取图的坐标信息
ax = plt.gca()
# 设置日期的显示格式
date_format = mpl.dates.DateFormatter("%m-%d")
ax.xaxis.set_major_formatter(date_format)
# 设置x轴每个刻度的间隔天数
xlocator = mpl.ticker.MultipleLocator(7)
ax.xaxis.set_major_locator(xlocator)
# 添加y轴标签
plt.ylabel('人数')
# 添加图形标题
plt.title('每天微信文章阅读人数趋势')
# 显示图形
plt.show()
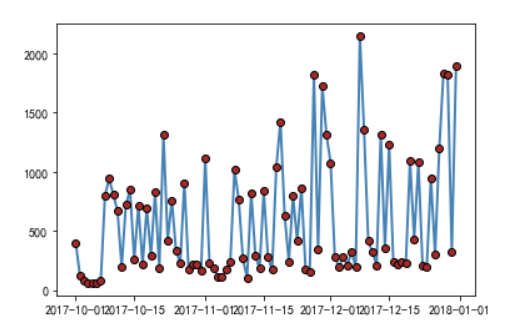
绘制两条直线图
# 导入模块,用于日期刻度的修改
import matplotlib as mpl
# 绘制阅读人数折线图
plt.plot(wechat.Date, # x轴数据
wechat.Counts, # y轴数据
linestyle = '-', # 折线类型,实心线
color = 'steelblue', # 折线颜色
label = '阅读人数'
)
# 绘制阅读人次折线图
plt.plot(wechat.Date, # x轴数据
wechat.Times, # y轴数据
linestyle = '--', # 折线类型,虚线
color = 'indianred', # 折线颜色
label = '阅读人次'
)
# 获取图的坐标信息
ax = plt.gca()
# 设置日期的显示格式
date_format = mpl.dates.DateFormatter("%m-%d")
ax.xaxis.set_major_formatter(date_format)
# 设置x轴显示多少个日期刻度
# xlocator = mpl.ticker.LinearLocator(10)
# 设置x轴每个刻度的间隔天数
xlocator = mpl.ticker.MultipleLocator(7)
ax.xaxis.set_major_locator(xlocator)
# 为了避免x轴刻度标签的紧凑,将刻度标签旋转45度
plt.xticks(rotation=45)
# 添加y轴标签
plt.ylabel('人数')
# 添加图形标题
plt.title('每天微信文章阅读人数与人次趋势')
# 添加图例
plt.legend()
# 显示图形
plt.show()

散点图的绘制
如果需要研究两个数值型变量之间是否存在某种关系,例如正向的线性关系,或者是趋势性的非线关系,那么散点图将是最佳的选择
scatter(x, y, s=20, c=None, marker='o', alpha=None, linewidths=None, edgecolors=None)
x:指定散点图的x轴数据
y:指定散点图的y轴数据
s:指定散点图点的大小,默认为20,通过传入其他数值型变量,可以实现气泡图的绘制
c:指定散点图点的颜色,默认为蓝色,也可以传递其他数值型变量,通过cmap参数的色阶表示数值大小
marker:指定散点图点的形状,默认为空心圆
alpha:设置散点的透明度
linewidths:设置散点边界线的宽度
edgecolors:设置散点边界线的颜色
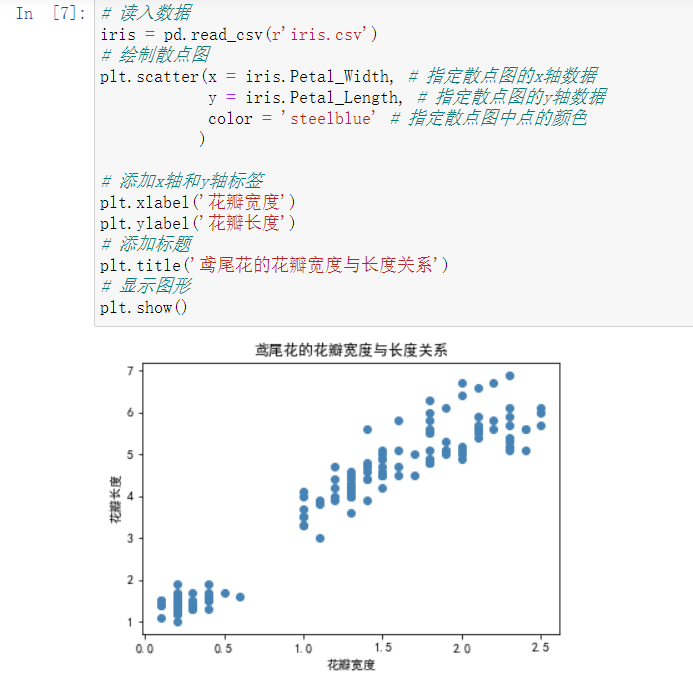
# 读入数据
iris = pd.read_csv(r'iris.csv')
# 绘制散点图
plt.scatter(x = iris.Petal_Width, # 指定散点图的x轴数据
y = iris.Petal_Length, # 指定散点图的y轴数据
color = 'steelblue' # 指定散点图中点的颜色
)
# 添加x轴和y轴标签
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
# 添加标题
plt.title('鸢尾花的花瓣宽度与长度关系')
# 显示图形
plt.show()
气泡图的绘制
气泡图的实质就是通过第三个数值型变量控制每个散点的大小,点越大,代表的第三维数值越高,反之亦然
气泡图的绘制,使用的依然是scatter函数,区别在于函数的s参数被赋予了具体的数值型变量
热力图的绘制
热力图也称为交叉填充表,图形最典型的用法就是实现联表的可视化,即通过图形的方式展示两个离散变量之间的组合关系
matplotlib绘制热力图不太方便需要借助于seaborn模块
sns.heatmap(data, cmap=None, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor ='white)
data:指定绘制热力图的数据集
cmap:指定一个colormap对象,用于热力图的填充色
annot:指定一个bool类型的值或与data参数形状一样的数组,如果为True,就在热力图的每个单元上显示数值
fmt:指定单元格中数据的显示格式
annot_kws:有关单元格中数值标签的其他属性描述,如颜色,大小等
linewidths:指定每个单元格的边框宽度
linecolor:指定每个单元格的边框颜色
import numpy as np
import seaborn as sns
# 读取数据
Sales = pd.read_excel(r'Sales.xlsx')
# 根据交易日期,衍生出年份和月份字段
Sales['year'] = Sales.Date.dt.year
Sales['month'] = Sales.Date.dt.month
# 统计每年各月份的销售总额(绘制热力图之前,必须将数据转换为交叉表形式)
Summary = Sales.pivot_table(index = 'month', columns = 'year', values = 'Sales', aggfunc = np.sum)
Summary
# 绘制热力图
sns.heatmap(data = Summary, # 指定绘图数据
cmap = 'PuBuGn', # 指定填充色
linewidths = .1, # 设置每个单元格边框的宽度
annot = True, # 显示数值
fmt = '.1e' # 以科学计算法显示数据
)
#添加标题
plt.title('每年各月份销售总额热力图')
# 显示图形
plt.show()

组合图的绘制
工作中往往会根据业务需求,将绘制的多个图形组合到一个大图框内,形成类似仪表盘的效果
plt.subplot2grid(shape, loc, rowspan=1, colspan=1, **kwargs)
shape:指定组合图的框架形状,以元组形式传递,如2*3的矩阵可以表示成(2,3)
loc:指定子图所在的位置,如shape中第一行第一列可以表示成(0,0)
rowspan:指定某个子图需要跨几行
colspan:指定某个子图需要跨几列
演示:
# 设置大图框的长和高 plt.figure(figsize = (12,6)) # 设置第一个子图的布局 ax1 = plt.subplot2grid(shape = (2,3), loc = (0,0)) # 设置第二个子图的布局 ax2 = plt.subplot2grid(shape = (2,3), loc = (0,1)) # 设置第三个子图的布局 ax3 = plt.subplot2grid(shape = (2,3), loc = (0,2), rowspan = 2) # 设置第四个子图的布局 ax4 = plt.subplot2grid(shape = (2,3), loc = (1,0), colspan = 2)
# 读取数据
Prod_Trade = pd.read_excel(r'Prod_Trade.xlsx')
# 衍生出交易年份和月份字段
Prod_Trade['year'] = Prod_Trade.Date.dt.year
Prod_Trade['month'] = Prod_Trade.Date.dt.month
# 设置大图框的长和高
plt.figure(figsize = (12,6))
# 设置第一个子图的布局
ax1 = plt.subplot2grid(shape = (2,3), loc = (0,0))
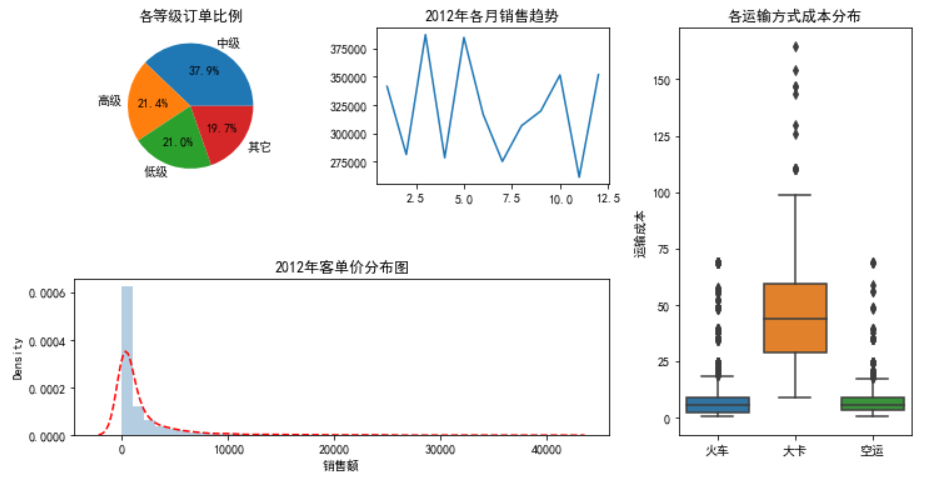
# 统计2012年各订单等级的数量
Class_Counts = Prod_Trade.Order_Class[Prod_Trade.year == 2012].value_counts()
Class_Percent = Class_Counts/Class_Counts.sum()
# 绘制订单等级饼图
ax1.pie(x = Class_Percent.values, labels = Class_Percent.index, autopct = '%.1f%%')
# 添加标题
ax1.set_title('各等级订单比例')
# 设置第二个子图的布局
ax2 = plt.subplot2grid(shape = (2,3), loc = (0,1))
# 统计2012年每月销售额
Month_Sales = Prod_Trade[Prod_Trade.year == 2012].groupby(by = 'month').aggregate({'Sales':np.sum})
# 绘制销售额趋势图
Month_Sales.plot(title = '2012年各月销售趋势', ax = ax2, legend = False)
# 删除x轴标签
ax2.set_xlabel('')
# 设置第三个子图的布局
ax3 = plt.subplot2grid(shape = (2,3), loc = (0,2), rowspan = 2)
# 绘制各运输方式的成本箱线图
sns.boxplot(x = 'Transport', y = 'Trans_Cost', data = Prod_Trade, ax = ax3)
# 添加标题
ax3.set_title('各运输方式成本分布')
# 删除x轴标签
ax3.set_xlabel('')
# 修改y轴标签
ax3.set_ylabel('运输成本')
# 设置第四个子图的布局
ax4 = plt.subplot2grid(shape = (2,3), loc = (1,0), colspan = 2)
# 2012年客单价分布直方图
sns.distplot(Prod_Trade.Sales[Prod_Trade.year == 2012], bins = 40, norm_hist = True, ax = ax4, hist_kws = {'color':'steelblue'}, kde_kws=({'linestyle':'--', 'color':'red'}))
# 添加标题
ax4.set_title('2012年客单价分布图')
# 修改x轴标签
ax4.set_xlabel('销售额')
# 调整子图之间的水平间距和高度间距
plt.subplots_adjust(hspace=0.6, wspace=0.3)
# 图形显示
plt.show()
可视化相关模块
1.matplotlib
2.seaborn
3.highcharts
4.echarts
pyecharts 可以通过python代码直接调用
5.ds.js
数据清洗的概念
专业定义
数据清洗是从记录表,表格,数据库中检查,纠正或删除损坏或不准确记录的过程
专业名称
脏数据
没有经过处理自身含有一定问题的数据(缺失,异常,重复...)
干净数据
经过处理完全符合规范要求的数据
常用方法
1.读取外部数据
read_csv read_excel read_sql read_html
2.数据概览
index columns head tail shape describe info dtypes
3.简单处理
移除首尾空格,大小写转换...
4.重复值处理
duplicated()查看是否含有重复数据
drop_duplicates()删除重复数据
5.缺失值处理
删除缺失值,填充缺失值
6.异常值处理
删除异常值,修正异常值(当做缺失值处理)
7.字符串处理
切割,筛选...
8.时间格式处理
Y m d H M S
(步骤3到8没有固定的顺序,只不过前期不熟练的情况下可以如此执行)
数据概览
import numpy as np import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv(r'qunar_freetrip.csv') # 1.查看前五条数据,掌握大概 df.head() # 2.查看表的行列总数 df.shape # 3.查看所有的列字段 df.columns # 发现列字段有一些是有空格的 # 4.查看数据整体信息 df.info() # 发现去程时间和回程时间是字符串类型,需要做日期类型转换 # 5.快速统计 df.describe() df.columns

列字段处理
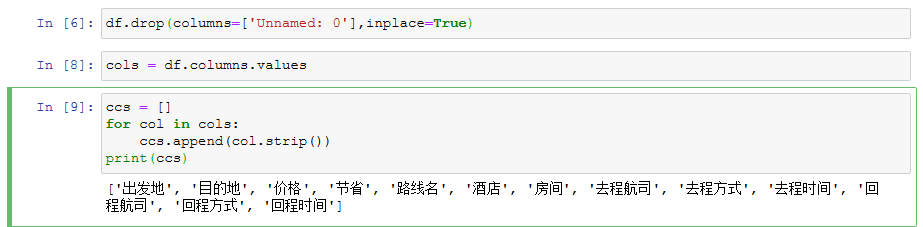
1.删除无用列字段
df.drop(columns=['Unnamed: 0'],inplace=True)
2.获取列字段
cols = df.columns.values
3.for循环依次取出列字段首位的空格
方法1 比较繁琐
ccs = []
for col in cols:
ccs.append(col.strip())
print(ccs)
方式2 列表生成式
df.columns = [col.strip() for col in cols]
重复值处理
# 4.重复数据查找 df.duplicated() # 5.简单的楼一眼重复数据的模样(布尔值索引) 可以忽略 df[df.duplicated()] # 6.针对重复的数据,一般情况下都是直接删除的 df.drop_duplicates(inplace=True) # 7.确认是否删除 df.shape # 8.行索引会不会因为数据的删除而自动重置(删除完数据之后行索引是不会自动重置的) # 如何获取表的行索引值 df.index # 右侧加上赋值符号就是修改行索引值 df.index = range(0,df.shape[0]) df.tail()

异常值处理
利用快速统计大致筛选出可能有异常数据的字段
df.describe() # 价格小于节省,那么可能是价格有问题或者节省有问题

利用公式求证我们的猜想(固定公式)
sd = (df['价格'] - df['价格'].mean()) / df['价格'].std() # 判断的标准
利用逻辑索引筛选数据
df[(sd > 3)|(sd < -3)]

利用绝对值
df[abs(sd) > 3] # abs就是绝对值的意思(移除正负号)

同理验证节省是否有异常(不一定要使用)
sd1 = (df['节省'] - df['节省'].mean()) / df['节省'].std() # 判断的标准 # 利用逻辑索引筛选数据 df[(sd > 3)|(sd < -3)] # 利用绝对值 df[abs(sd1) > 3] # abs就是绝对值的意思(移除正负号)
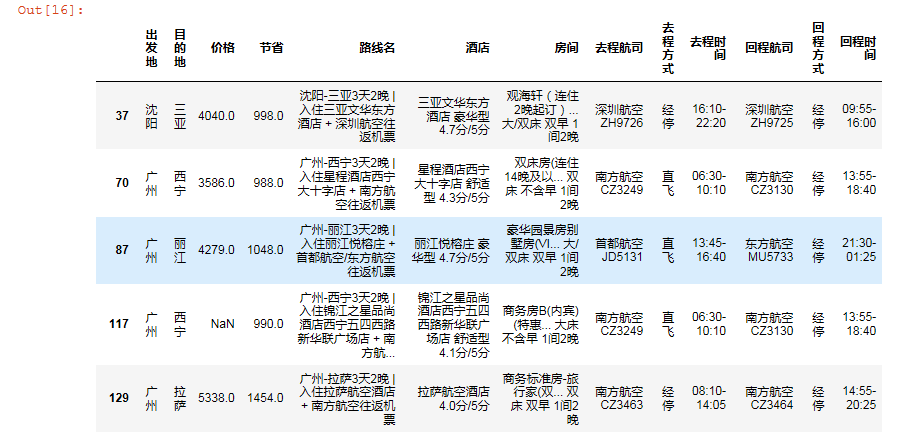
直接简单粗暴找节省大于价格的数据(推荐下列方式)
df[df['节省'] > df['价格']]
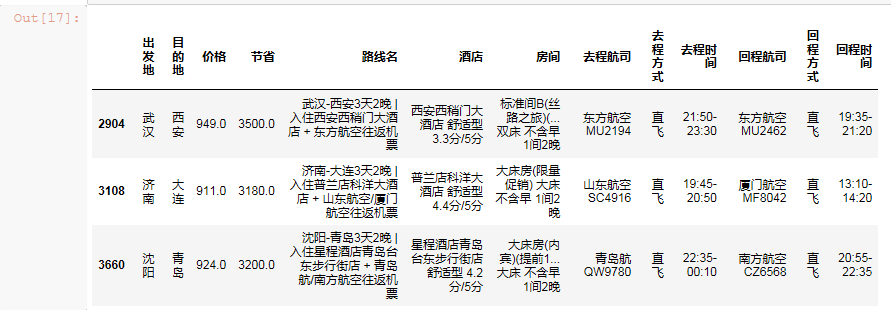
删除价格和节省都有异常的数据
方法1:先拼接,再一次性删除
横向合并:pd.merge()
纵向合并:pd.concat()
res = pd.concat([df[df['节省'] > df['价格']],df[abs(sd) > 3]]) # 获取要删除的行数据,索引值 del_index = res.index # 根据索引删除数据 df.drop(index = del_index,inplace = True) # 再次重置索引 df.index = range(0,df.shape[0])
方法2:得出一个结果就删一个
出发地缺失值处理
# 查找具有缺失值的列名称
df.isnull().sum() # 统计每个字段缺失数据条数
# 利用布尔值索引筛选出出发地有缺失的数据
df[df.出发地.isnull()]
# 获取出发地缺失的数据的路线数据
df.loc[df.出发地.isnull(),'路线名'].values
# 利用字符串切割替换出发地缺失数据
df.loc[df.出发地.isnull(),'出发地'] = [i.split('-')[0] for i in df.loc[df.出发地.isnull(),'路线名'].values]
操作数据的列字段需要使用loc方法
针对缺失值的处理
1.采用数学公式,依据其他数据填充
2.缺失值可能在其他单元格中含有
3.如果缺失值数量展示很小可删除
数据符号网站:
https://symbol.91maths.com/
因变量与自变量:
函数关系式中,某些特定的数会随另一个(或另几个)会变动的数的变动而变动
可以自己随意调整变动数值的是自变量,用来展示变化的是因变量
ep:y = 2x+3
y是因变量,x是自变量
哑变量:
用以反映质的属性的一个人工变量,是量化了的自变量,通常取值为0或1。
ep:
观察地区对某个数值的影响,地区的地名是中午字符,无法计算
因此将每个地名归为一个类,观察不同类中的数据的区别
如何判断两个变量之间是否存在线性关系与非线性关系
1.散点图
2.公式计算:
np.corrcoef(数据列表1,数据列表2)
计算两组数据之间的相关程度
返回的结果绝对值越接近1则表示两组数据的相关性越强
绝对值大于等于0.8表示高度相关
绝对值大于等于0.5,小于0.8表示中度相关
绝对值大于等于0.3,小于0.5表示弱相关
绝对值小于0.3表示几乎不相关(需要注意这里的不相关指的是没有线性关系,可能两者之间有其他关系)
线性关系判断
import numpy import pandas X = [52,19,7,33,2] Y = [162,61,22,100,6] XMean = numpy.mean(X) YMean = numpy.mean(Y) # 标准差 XSD = numpy.std(X) YSD = numpy.std(Y) # z分数 ZX = (X-XMean)/XSD ZY = (Y-YMean)/YSD
相关系数
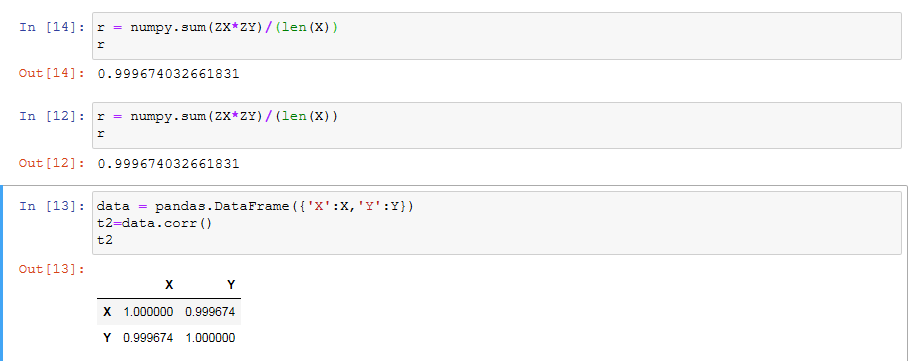
方法1:
r = numpy.sum(ZX*ZY)/(len(X)) r
方法2:
r = numpy.sum(ZX*ZY)/(len(X)) r
方法3:
data = pandas.DataFrame({'X':X,'Y':Y})
t2=data.corr()
t2
训练集与测试集
训练集用于模型的训练创建,测试集用于模型的测试检验
一般情况下训练集占总数据的80%,测试集占总数占20%
哑变量
在生成算法模型的时候有些变量可能并不是数字无法直接带入公式计算,因此可以构造哑变量:
C(State)
自定义哑变量
# 生成由State变量衍生的哑变量
dummies = pd.get_dummies(Profit.State)
# 将哑变量与原始数据集水平合并
Profit_New = pd.concat([Profit,dummies], axis = 1)
# 删除State变量和California变量(因为State变量已被分解为哑变量,New York变量需要作为参照组)
Profit_New.drop(labels = ['State','New York'], axis = 1, inplace = True)
# 拆分数据集Profit_New
train, test = model_selection.train_test_split(Profit_New, test_size = 0.2, random_state=1234)
# 建模
model2 = sm.formula.ols('Profit~RD_Spend+Administration+Marketing_Spend+Florida+California', data = train).fit()
print('模型的偏回归系数分别为:\n', model2.params)
在几个数值相互关联的情况下,省去某个数值并不会影响整体判断,反而能增加计算效率,因此系统会将其省去
ep: 男 女
小明 1 0
小红 0 1
单独去除男或女中的某一列,并不会影响用户判断小明和小红的性别
线性回归模型
import numpy as np import pandas as pd import matplotlib.pyplot as plt df1 = pd.read_csv(r'Salary_Data.csv') # 读取数据 df1.head()

判断数据是否存在线性关系:
方法1:
plt.scatter(x=df1['YearsExperience'],y=df1['Salary']) # 使用散点图判断数据是否存在线性关系 plt.show()
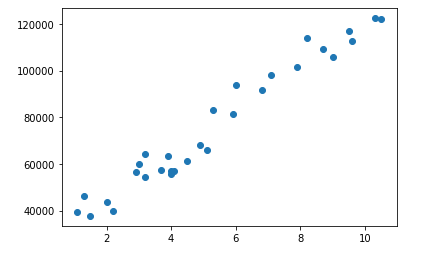
方法2:
np.corrcoef(df1['YearsExperience'],df1['Salary']) # 使用corrcoef公式判断数据是否存在线性关系
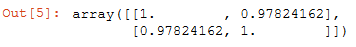
import statsmodels.api as sm
fit = sm.formula.ols('Salary~YearsExperience',data=df1).fit()
fit.params

因此,薪资预测:
25792.200199 + 工作年数 * 9449.962321
df1

训练集与测试集
profit = pd.read_excel(r'Predict to Profit.xlsx') # profit.head() # profit.shape profit.columns

from sklearn import model_selection
# 将数据划分为训练集和测试集
train,test = model_selection.train_test_split(profit,test_size=0.2,random_state=1234)
model = sm.formula.ols('Profit~RD_Spend+Administration+Marketing_Spend+C(State)',data=train).fit()
model.params

test_x = test.drop(columns=['Profit'])
pred = model.predict(exog=test_x)
pd.DataFrame({"预测值":pred,'真实值':test.Profit})

# 生成由State变量衍生的哑变量 dummies = pd.get_dummies(profit.State) dummies

模型的假设检验(F与T)
F检验:提出原假设和备择假设 之后计算统计量与理论值 最后比较
(F检验主要检验的是模型是否合理)
# 导⼊第三⽅模块
import numpy as np
# 计算建模数据中因变量的均值
ybar=train.Profit.mean()
# 统计变量个数和观测个数
p=model2.df_model
n=train.shape[0]
# 计算回归离差平⽅和
RSS=np.sum((model2.fittedvalues-ybar)**2)
# 计算误差平⽅和
ESS=np.sum(model2.resid**2)
# 计算F统计量的值
F=(RSS/p)/(ESS/(n-p-1))
print('F统计量的值:',F)
F统计量的值:174.6372
# 导⼊模块
from scipy.stats import f
# 计算F分布的理论值
F_Theroy = f.ppf(q=0.95, dfn = p,dfd = n-p-1)
print('F分布的理论值为:',F_Theroy)
out:
F分布的理论值为: 2.5026
计算出来的F统计量值174.64远远⼤于F分布的理论值2.50
所以应当拒绝原假设(先假设模型不合理)
T检验更加侧重于检验模型的各个参数是否合理
model.summary() # 绝对值越小影响越大
1.自变量的个数大于样本量
表头数据列数大于数据条数,算式会无法计算
2.自变量之间存在多重共线性
数据列数之间存在特殊联系,算式会无法计算
岭回归模型
在线性回归模型的基础之上添加一个l2惩罚项(平方项、正则项)
(该模型最终转变成求解圆柱体与椭圆抛物线的焦点问题)
Lasso回归模型
在线性回归模型的基础之上添加一个l1惩罚项(绝对值项、正则项)
相较于岭回归降低了模型的复杂度
(该模型最终转变成求解正方体与椭圆抛物线的焦点问题)
交叉验证
将所有数据都参与到模型的构建和测试中 最后生成多个模型
(从所有数据中随机移除一小部分后制作模型,重复多次,生产多个模型)
再从多个模型中筛选出得分最高(准确度)的模型
将线性回归模型的公式做Logit变换即为Logistic回归模型
将预测问题变成了0到1之间的概率问题
准确率:表示正确预测的正负例样本数与所有样本数量的⽐值,即(A+D)/(A+B+C+D)。
正例覆盖率:表示正确预测的正例数在实际正例数中的⽐例,即D/(B+D)。
负例覆盖率:表示正确预测的负例数在实际负例数中的⽐例,即A/(A+C)。
正例命中率:表示正确预测的正例数在预测正例数中的⽐例,即D/(C+D),
1.ROC曲线
通过计算AUC阴影部分的面积来判断模型是否合理(通常大于0.8表示OK)
2.KS曲线
通过计算两条折现之间最大距离来衡量模型是否合理(通常大于0.4表示OK)
默认情况下解决分类问题(买与不买、带与不带、走与不走)
也可以切换算法解决预测问题(具体数值多少)
(树其实是一种计算机底层的数据结构,与现实不同
计算机里面的树都是自上而下的生长)
决策树则是算法模型中的一种概念,有三个主要部分
根节点、枝节点、叶子节点
(根节点与枝节点用于存放条件,叶子节点存放真正的数据结果)
1.信息熵
eg:信息熵小相当于红绿灯情况,信息熵大相当于买彩票中奖情况
2.条件熵
条件熵其实就是由信息熵再次细分而来
比如有九个用户购买了商品五个没有购买 那么条件熵就是继续从购买不购买的用户中再选择一个条件
(比如按照性别计算男和女的熵)
3.信息增益
信息增益可以反映出某个条件是否对最终的分类有决定性的影响
在构建决策树时根节点与枝节点所放的条件按照信息增益由大到小排
4.信息增益率
决策树中的ID3算法使⽤信息增益指标实现根节点或中间节点的字段选择,但是该指标存在⼀个⾮常明显的缺点,即信息增益会偏向于取值较多的字段。
为了克服信息增益指标的缺点,提出了信息增益率的概念,它的思想很简单,就是在信息增益的基础上进⾏相应的惩罚。
基尼指数
可以让模型解决预测问题
基尼指数增益
与信息增益类似,还需要考虑⾃变量对因变量的影响程度,即因变量的基尼指数下降速度的快慢,下降得越快,⾃变量对因变量的影响就越强
随机森林中每颗决策树都不限制节点字段选择,有多棵树组成的随机森林
在解决分类问题的时候采用投票法、解决预测问题的时候采用均值法
思想:根据位置样本点周边K个邻居样本完成预测或者分类
K值的选择
1.先猜测
2.交叉验证
3.作图选择最合理的k值
准确率(越大越好) MSE(越小越好)
过拟合与欠拟合
过拟合:过于精确,导致容易被误导
欠拟合:太模糊,导致得到的结果准确性太差
距离
欧式距离
两点之间的直线距离
曼哈顿距离
默认两点直接有障碍物
余弦相似度
论文查重

 浙公网安备 33010602011771号
浙公网安备 33010602011771号