线性回归模型
数据符号网站:
https://symbol.91maths.com/
因变量与自变量:
函数关系式中,某些特定的数会随另一个(或另几个)会变动的数的变动而变动
可以自己随意调整变动数值的是自变量,用来展示变化的是因变量
ep:y = 2x+3
y是因变量,x是自变量
哑变量:
用以反映质的属性的一个人工变量,是量化了的自变量,通常取值为0或1。
ep:
观察地区对某个数值的影响,地区的地名是中午字符,无法计算
因此将每个地名归为一个类,观察不同类中的数据的区别
如何判断两个变量之间是否存在线性关系与非线性关系
1.散点图
2.公式计算:
np.corrcoef(数据列表1,数据列表2)
计算两组数据之间的相关程度
返回的结果绝对值越接近1则表示两组数据的相关性越强
绝对值大于等于0.8表示高度相关
绝对值大于等于0.5,小于0.8表示中度相关
绝对值大于等于0.3,小于0.5表示弱相关
绝对值小于0.3表示几乎不相关(需要注意这里的不相关指的是没有线性关系,可能两者之间有其他关系)
线性关系判断
import numpy import pandas X = [52,19,7,33,2] Y = [162,61,22,100,6] XMean = numpy.mean(X) YMean = numpy.mean(Y) # 标准差 XSD = numpy.std(X) YSD = numpy.std(Y) # z分数 ZX = (X-XMean)/XSD ZY = (Y-YMean)/YSD
相关系数
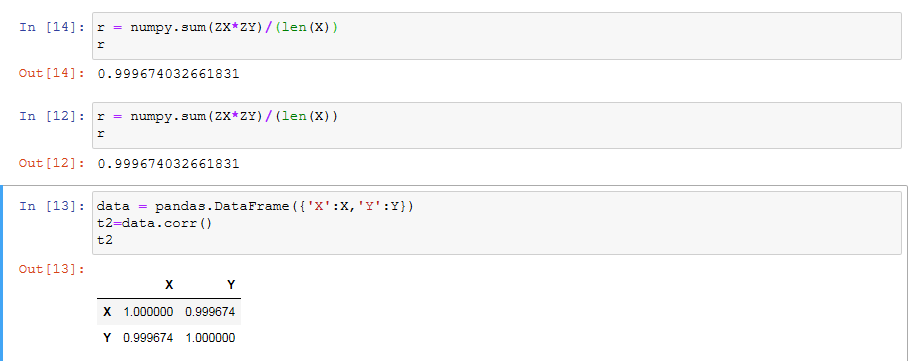
方法1:
r = numpy.sum(ZX*ZY)/(len(X))
r
方法2:
r = numpy.sum(ZX*ZY)/(len(X))
r
方法3:
data = pandas.DataFrame({'X':X,'Y':Y})
t2=data.corr()
t2
训练集与测试集
训练集用于模型的训练创建,测试集用于模型的测试检验
一般情况下训练集占总数据的80%,测试集占总数占20%
哑变量
在生成算法模型的时候有些变量可能并不是数字无法直接带入公式计算,因此可以构造哑变量:
C(State)
自定义哑变量
# 生成由State变量衍生的哑变量 dummies = pd.get_dummies(Profit.State) # 将哑变量与原始数据集水平合并 Profit_New = pd.concat([Profit,dummies], axis = 1) # 删除State变量和California变量(因为State变量已被分解为哑变量,New York变量需要作为参照组) Profit_New.drop(labels = ['State','New York'], axis = 1, inplace = True) # 拆分数据集Profit_New train, test = model_selection.train_test_split(Profit_New, test_size = 0.2, random_state=1234) # 建模 model2 = sm.formula.ols('Profit~RD_Spend+Administration+Marketing_Spend+Florida+California', data = train).fit() print('模型的偏回归系数分别为:\n', model2.params)
在几个数值相互关联的情况下,省去某个数值并不会影响整体判断,反而能增加计算效率,因此系统会将其省去
ep: 男 女
小明 1 0
小红 0 1
单独去除男或女中的某一列,并不会影响用户判断小明和小红的性别
线性回归模型
import numpy as np import pandas as pd import matplotlib.pyplot as plt df1 = pd.read_csv(r'Salary_Data.csv') # 读取数据 df1.head()

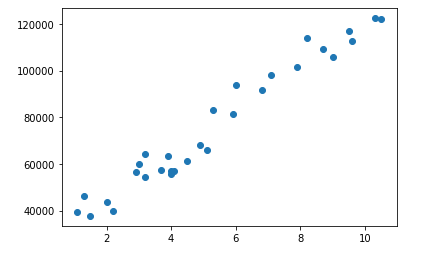
判断数据是否存在线性关系:
方法1:
plt.scatter(x=df1['YearsExperience'],y=df1['Salary']) # 使用散点图判断数据是否存在线性关系 plt.show()
方法2:
np.corrcoef(df1['YearsExperience'],df1['Salary']) # 使用corrcoef公式判断数据是否存在线性关系
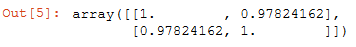
import statsmodels.api as sm fit = sm.formula.ols('Salary~YearsExperience',data=df1).fit() fit.params

因此,薪资预测:
25792.200199 + 工作年数 * 9449.962321
df1

训练集与测试集
profit = pd.read_excel(r'Predict to Profit.xlsx') # profit.head() # profit.shape profit.columns

from sklearn import model_selection # 将数据划分为训练集和测试集 train,test = model_selection.train_test_split(profit,test_size=0.2,random_state=1234) model = sm.formula.ols('Profit~RD_Spend+Administration+Marketing_Spend+C(State)',data=train).fit() model.params

test_x = test.drop(columns=['Profit']) pred = model.predict(exog=test_x) pd.DataFrame({"预测值":pred,'真实值':test.Profit})

# 生成由State变量衍生的哑变量 dummies = pd.get_dummies(profit.State) dummies


 浙公网安备 33010602011771号
浙公网安备 33010602011771号