

matplotlib模块补完
解决作图乱码
jupyter 画图轴标题不显示中文(显示方框)_singghet的博客-CSDN博客
文件这里面有:C:\Windows\Fonts
matplotlib绘图
import matplotlib.pyplot as plt
饼图 plt.pie
垂直条形图 plt.bar
水平条形图 plt.barh
直方图 plt.hist
箱线图 plt.boxplot
折线图 plt.plot
散点图 plt.scatter
组合图 plt.subplot2grid
import seaborn as sns
热力图 sns.heatmap
以弹框的形式显示图形 %matplotlib
条形图
对比柱形的高低,柱体越高,代表的数值越大,反之亦然
bar(x, height,
width=0.8,
bottom=None,
color=None,
edgecolor=None,
tick_label=None,
label = None,
ecolor=None)
x:传递数值序列,指定条形图中x轴上的刻度值
height:传递数值序列,指定条形图y轴上的高度
width:指定条形图的宽度,默认为0.8
bottom:用于绘制堆叠条形图
color:指定条形图的边框色
edgecolor:指定条形图的边框色
tick_label:指定条形图的刻度标签
label:指定条形图的标签,一般用以添加图例
垂直条形图
import pandas as pd import matplotlib.pyplot as plt # 读入数据 GDP = pd.read_excel(r'Province GDP 2017.xlsx') # 设置绘图风格(不妨使用R语言中的ggplot2风格) plt.style.use('ggplot') # 绘制条形图 plt.bar(x = range(GDP.shape[0]), # 指定条形图x轴的刻度值 height = GDP.GDP, # 指定条形图y轴的数值 tick_label = GDP.Province, # 指定条形图x轴的刻度标签 color = 'steelblue', # 指定条形图的填充色 ) # 添加y轴的标签 plt.ylabel('GDP(万亿)') # 添加条形图的标题 plt.title('2017年度6个省份GDP分布') # 为每个条形图添加数值标签 for x,y in enumerate(GDP.GDP): plt.text(x,y+0.1,'%s' %round(y,1),ha='center') # 显示图形 plt.show()
水平条形图
# 对读入的数据做升序排序 GDP.sort_values(by = 'GDP', inplace = True) # 绘制条形图 plt.barh(y = range(GDP.shape[0]), # 指定条形图y轴的刻度值 width = GDP.GDP, # 指定条形图x轴的数值 tick_label = GDP.Province, # 指定条形图y轴的刻度标签 color = 'steelblue', # 指定条形图的填充色 ) # 添加x轴的标签 plt.xlabel('GDP(万亿)') # 添加条形图的标题 plt.title('2017年度6个省份GDP分布') # 为每个条形图添加数值标签 for y,x in enumerate(GDP.GDP): plt.text(x+0.1,y,'%s' %round(x,1),va='center') # 显示图形 plt.show()
交叉条形图
HuRun = pd.read_excel('HuRun.xlsx') # Pandas模块之水平交错条形图 HuRun_reshape = HuRun.pivot_table(index = 'City', columns='Year', values='Counts').reset_index() # 对数据集降序排序 HuRun_reshape.sort_values(by = 2016, ascending = False, inplace = True) HuRun_reshape.plot(x = 'City', y = [2016,2017], kind = 'bar', color = ['steelblue', 'indianred'], # 用于旋转x轴刻度标签的角度,0表示水平显示刻度标签 rot = 0, width = 0.8, title = '近两年5个城市亿万资产家庭数比较') # 添加y轴标签 plt.ylabel('亿万资产家庭数') plt.xlabel('') plt.show()

直方图的绘制
直方图一般用来观察数据的分布形态,一般都会与核密度图搭配使用,目的是更加清楚地掌握数据的分布特征
plt.hist(x, bins=10, normed=False, orientation='vertical', color=None, label=None)
x:指定要绘制直方图的数据
bins:指定直方图条形的个数
normed:是否将直方图的频数转换成频率
orientation:设置直方图的摆放方向,默认为垂直方向
color:设置直方图的填充色
edgecolor:设置直方图边框色
label:设置直方图的标签,可通过legend展示其图例
Titanic = pd.read_csv('titanic_train.csv') # 检查年龄是否有缺失(如果数据中存在缺失值,将无法绘制直方图) any(Titanic.Age.isnull()) # 不妨删除含有缺失年龄的观察 Titanic.dropna(subset=['Age'], inplace=True) # 绘制直方图 plt.hist(x = Titanic.Age, # 指定绘图数据 bins = 20, # 指定直方图中条块的个数 color = 'steelblue', # 指定直方图的填充色 edgecolor = 'black' # 指定直方图的边框色 ) # 添加x轴和y轴标签 plt.xlabel('年龄') plt.ylabel('频数') # 添加标题 plt.title('乘客年龄分布') # 显示图形 plt.show()

箱线图的绘制
箱线图是另一种体现数据分布的图形,通过该图可以得知数据的下须值(Q1-1.5IQR)、下四 分位数(Q1)、中位数(Q2)、均值、上四分位(Q3)数和上须值(Q3+1.5IQR),更重要的是,箱线图还可以发现数据中的异常点;
plt.boxplot(x, vert=None, whis=None, patch_artist=None, meanline=None, showmeans=None, showcaps=None, showbox=None, showfliers=None, boxprops=None, labels=None, flierprops=None, medianprops=None, meanprops=None, capprops=None, whiskerprops=None)
x:指定要绘制箱线图的数据
vert:是否需要将箱线图垂直摆放,默认垂直摆放
whis:指定上下须与上下四分位的距离,默认为1.5倍的四分位差
patch_artist:bool类型参数,是否填充箱体的颜色,默认为False
meanline:bool类型参数,是否用线的形式表示均值,默认为False
showmeans:bool类型参数,是否显示均值,默认为False
showcaps:bool类型参数,是否显示箱线图顶端和末端的两条线(即上下须),默认为True
showbox:bool类型参数,是否显示箱线图的箱体,默认为True
showfliers:是否显示异常值,默认为True
boxprops:设置箱体的属性,如边框色,填充色等
labels:为箱线图添加标签,类似于图例的作用
filerprops:设置异常值的属性,如异常点的形状,大小,填充色等
medianprops:设置中位数的属性,如线的类型,粗细等
meanprops:设置均值的属性,如点的大小,颜色等
capprops:设置箱线图顶端和末端线条的属性,如颜色,粗细等
whiskerprops:设置须的属性,如颜色,粗细,线的类型等
Sec_Buildings = pd.read_excel('sec_buildings.xlsx') # 绘制箱线图 plt.boxplot(x = Sec_Buildings.price_unit, # 指定绘图数据 patch_artist=True, # 要求用自定义颜色填充盒形图,默认白色填充 showmeans=True, # 以点的形式显示均值 boxprops = {'color':'black','facecolor':'steelblue'},# 设置箱体属性,如边框色和填充色 # 设置异常点属性,如点的形状、填充色和点的大小 flierprops = {'marker':'o','markerfacecolor':'red', 'markersize':3,'markeredgecolor':'red'}, # 设置均值点的属性,如点的形状、填充色和点的大小 meanprops = {'marker':'D','markerfacecolor':'indianred', 'markersize':4}, # 设置中位数线的属性,如线的类型和颜色 medianprops = {'linestyle':'--','color':'orange'}, labels = [''] # 删除x轴的刻度标签,否则图形显示刻度标签为1 ) # 添加图形标题 plt.title('二手房单价分布的箱线图') # 显示图形 plt.show()

折线图的绘制
对于时间序列数据而言,一般都会使用折线图反应数据背后的趋势
通常折线图的横坐标指代如期数据,纵坐标代表某个数值型变量,当然还可以使用第三个离散变量对折线图进行分组处理
plt.plot(x,
y,
linestyle,
linewidth,
color,
marker,
markersize,
markeredgecolor,
markerfactcolor,
markeredgewidth,
label,
alpha)
x:指定折线图的x轴数据
y:指定折线图的y轴数据
linestyle:指定折线图的类型,可以是实线,虚线,点虚线,点点线等,默认为实线
linewidth:指定折线的宽度
marker:可以为折线图添加点,该参数是设置点的形状
markersize:设置点的大小
markeredgecolor:设置点的边框色
markerfactcolor:设置点的填充色
markeredgewidth:设置点的边框宽度
label:为折线图添加标签,类似于图例的作用
# 数据读取 wechat = pd.read_excel(r'wechat.xlsx') # 绘制单条折线图 plt.plot(wechat.Date, # x轴数据 wechat.Counts, # y轴数据 linestyle = '-', # 折线类型 linewidth = 2, # 折线宽度 color = 'steelblue', # 折线颜色 marker = 'o', # 折线图中添加圆点 markersize = 6, # 点的大小 markeredgecolor='black', # 点的边框色 markerfacecolor='brown') # 点的填充色 # 获取图的坐标信息 ax = plt.gca() # 设置日期的显示格式 date_format = mpl.dates.DateFormatter("%m-%d") ax.xaxis.set_major_formatter(date_format) # 设置x轴每个刻度的间隔天数 xlocator = mpl.ticker.MultipleLocator(7) ax.xaxis.set_major_locator(xlocator) # 添加y轴标签 plt.ylabel('人数') # 添加图形标题 plt.title('每天微信文章阅读人数趋势') # 显示图形 plt.show()
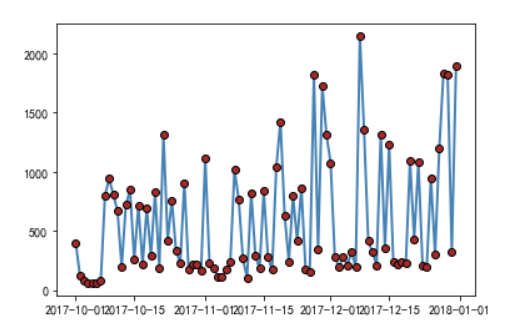
绘制两条直线图
# 导入模块,用于日期刻度的修改 import matplotlib as mpl # 绘制阅读人数折线图 plt.plot(wechat.Date, # x轴数据 wechat.Counts, # y轴数据 linestyle = '-', # 折线类型,实心线 color = 'steelblue', # 折线颜色 label = '阅读人数' ) # 绘制阅读人次折线图 plt.plot(wechat.Date, # x轴数据 wechat.Times, # y轴数据 linestyle = '--', # 折线类型,虚线 color = 'indianred', # 折线颜色 label = '阅读人次' ) # 获取图的坐标信息 ax = plt.gca() # 设置日期的显示格式 date_format = mpl.dates.DateFormatter("%m-%d") ax.xaxis.set_major_formatter(date_format) # 设置x轴显示多少个日期刻度 # xlocator = mpl.ticker.LinearLocator(10) # 设置x轴每个刻度的间隔天数 xlocator = mpl.ticker.MultipleLocator(7) ax.xaxis.set_major_locator(xlocator) # 为了避免x轴刻度标签的紧凑,将刻度标签旋转45度 plt.xticks(rotation=45) # 添加y轴标签 plt.ylabel('人数') # 添加图形标题 plt.title('每天微信文章阅读人数与人次趋势') # 添加图例 plt.legend() # 显示图形 plt.show()

散点图的绘制
如果需要研究两个数值型变量之间是否存在某种关系,例如正向的线性关系,或者是趋势性的非线关系,那么散点图将是最佳的选择
scatter(x, y, s=20, c=None, marker='o', alpha=None, linewidths=None, edgecolors=None)
x:指定散点图的x轴数据
y:指定散点图的y轴数据
s:指定散点图点的大小,默认为20,通过传入其他数值型变量,可以实现气泡图的绘制
c:指定散点图点的颜色,默认为蓝色,也可以传递其他数值型变量,通过cmap参数的色阶表示数值大小
marker:指定散点图点的形状,默认为空心圆
alpha:设置散点的透明度
linewidths:设置散点边界线的宽度
edgecolors:设置散点边界线的颜色
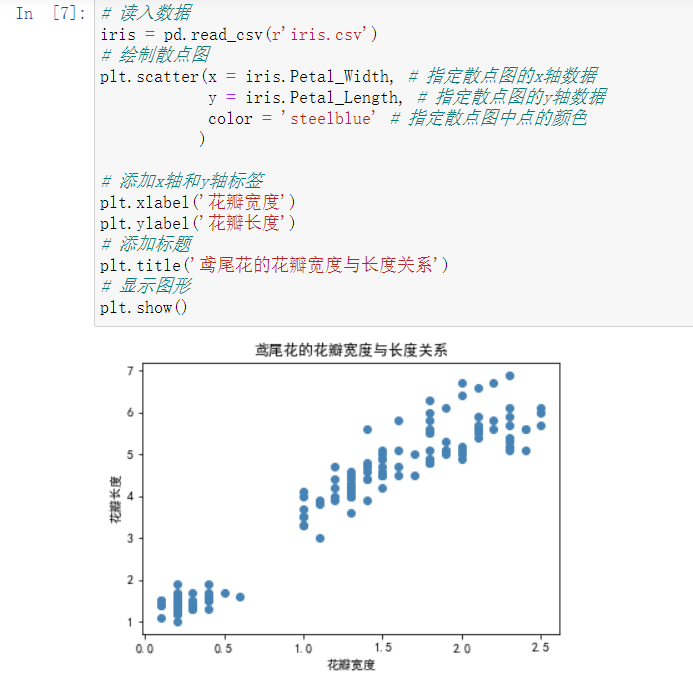
# 读入数据 iris = pd.read_csv(r'iris.csv') # 绘制散点图 plt.scatter(x = iris.Petal_Width, # 指定散点图的x轴数据 y = iris.Petal_Length, # 指定散点图的y轴数据 color = 'steelblue' # 指定散点图中点的颜色 ) # 添加x轴和y轴标签 plt.xlabel('花瓣宽度') plt.ylabel('花瓣长度') # 添加标题 plt.title('鸢尾花的花瓣宽度与长度关系') # 显示图形 plt.show()
气泡图的绘制
气泡图的实质就是通过第三个数值型变量控制每个散点的大小,点越大,代表的第三维数值越高,反之亦然
气泡图的绘制,使用的依然是scatter函数,区别在于函数的s参数被赋予了具体的数值型变量
热力图的绘制
热力图也称为交叉填充表,图形最典型的用法就是实现联表的可视化,即通过图形的方式展示两个离散变量之间的组合关系
matplotlib绘制热力图不太方便需要借助于seaborn模块
sns.heatmap(data, cmap=None, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor ='white)
data:指定绘制热力图的数据集
cmap:指定一个colormap对象,用于热力图的填充色
annot:指定一个bool类型的值或与data参数形状一样的数组,如果为True,就在热力图的每个单元上显示数值
fmt:指定单元格中数据的显示格式
annot_kws:有关单元格中数值标签的其他属性描述,如颜色,大小等
linewidths:指定每个单元格的边框宽度
linecolor:指定每个单元格的边框颜色
import numpy as np import seaborn as sns # 读取数据 Sales = pd.read_excel(r'Sales.xlsx') # 根据交易日期,衍生出年份和月份字段 Sales['year'] = Sales.Date.dt.year Sales['month'] = Sales.Date.dt.month # 统计每年各月份的销售总额(绘制热力图之前,必须将数据转换为交叉表形式) Summary = Sales.pivot_table(index = 'month', columns = 'year', values = 'Sales', aggfunc = np.sum) Summary # 绘制热力图 sns.heatmap(data = Summary, # 指定绘图数据 cmap = 'PuBuGn', # 指定填充色 linewidths = .1, # 设置每个单元格边框的宽度 annot = True, # 显示数值 fmt = '.1e' # 以科学计算法显示数据 ) #添加标题 plt.title('每年各月份销售总额热力图') # 显示图形 plt.show()

组合图的绘制
工作中往往会根据业务需求,将绘制的多个图形组合到一个大图框内,形成类似仪表盘的效果
plt.subplot2grid(shape, loc, rowspan=1, colspan=1, **kwargs)
shape:指定组合图的框架形状,以元组形式传递,如2*3的矩阵可以表示成(2,3)
loc:指定子图所在的位置,如shape中第一行第一列可以表示成(0,0)
rowspan:指定某个子图需要跨几行
colspan:指定某个子图需要跨几列
演示:
# 设置大图框的长和高 plt.figure(figsize = (12,6)) # 设置第一个子图的布局 ax1 = plt.subplot2grid(shape = (2,3), loc = (0,0)) # 设置第二个子图的布局 ax2 = plt.subplot2grid(shape = (2,3), loc = (0,1)) # 设置第三个子图的布局 ax3 = plt.subplot2grid(shape = (2,3), loc = (0,2), rowspan = 2) # 设置第四个子图的布局 ax4 = plt.subplot2grid(shape = (2,3), loc = (1,0), colspan = 2)
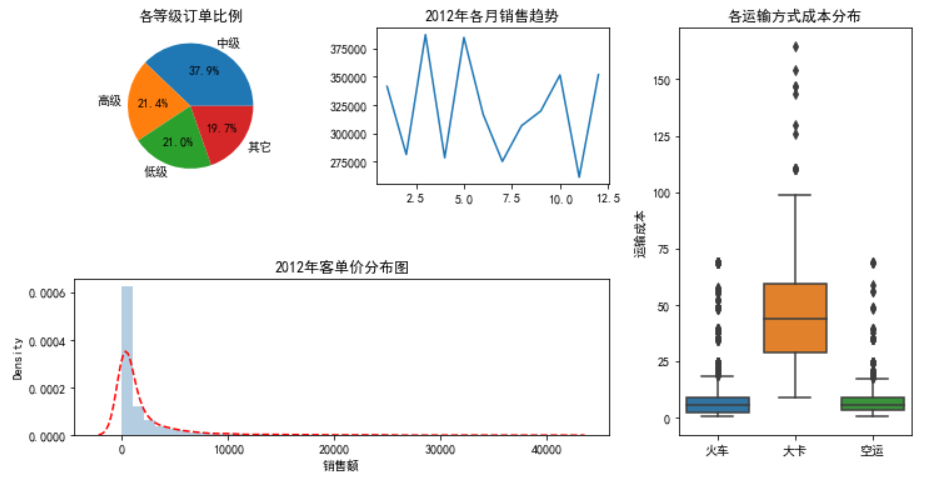
# 读取数据 Prod_Trade = pd.read_excel(r'Prod_Trade.xlsx') # 衍生出交易年份和月份字段 Prod_Trade['year'] = Prod_Trade.Date.dt.year Prod_Trade['month'] = Prod_Trade.Date.dt.month # 设置大图框的长和高 plt.figure(figsize = (12,6)) # 设置第一个子图的布局 ax1 = plt.subplot2grid(shape = (2,3), loc = (0,0)) # 统计2012年各订单等级的数量 Class_Counts = Prod_Trade.Order_Class[Prod_Trade.year == 2012].value_counts() Class_Percent = Class_Counts/Class_Counts.sum() # 绘制订单等级饼图 ax1.pie(x = Class_Percent.values, labels = Class_Percent.index, autopct = '%.1f%%') # 添加标题 ax1.set_title('各等级订单比例') # 设置第二个子图的布局 ax2 = plt.subplot2grid(shape = (2,3), loc = (0,1)) # 统计2012年每月销售额 Month_Sales = Prod_Trade[Prod_Trade.year == 2012].groupby(by = 'month').aggregate({'Sales':np.sum}) # 绘制销售额趋势图 Month_Sales.plot(title = '2012年各月销售趋势', ax = ax2, legend = False) # 删除x轴标签 ax2.set_xlabel('') # 设置第三个子图的布局 ax3 = plt.subplot2grid(shape = (2,3), loc = (0,2), rowspan = 2) # 绘制各运输方式的成本箱线图 sns.boxplot(x = 'Transport', y = 'Trans_Cost', data = Prod_Trade, ax = ax3) # 添加标题 ax3.set_title('各运输方式成本分布') # 删除x轴标签 ax3.set_xlabel('') # 修改y轴标签 ax3.set_ylabel('运输成本') # 设置第四个子图的布局 ax4 = plt.subplot2grid(shape = (2,3), loc = (1,0), colspan = 2) # 2012年客单价分布直方图 sns.distplot(Prod_Trade.Sales[Prod_Trade.year == 2012], bins = 40, norm_hist = True, ax = ax4, hist_kws = {'color':'steelblue'}, kde_kws=({'linestyle':'--', 'color':'red'})) # 添加标题 ax4.set_title('2012年客单价分布图') # 修改x轴标签 ax4.set_xlabel('销售额') # 调整子图之间的水平间距和高度间距 plt.subplots_adjust(hspace=0.6, wspace=0.3) # 图形显示 plt.show()
可视化相关模块
1.matplotlib
2.seaborn
3.highcharts
4.echarts
pyecharts 可以通过python代码直接调用
5.ds.js
(只要python学得好,很多领域都有用武之地)
