第十周总结
数据分析
数据分析的概念
什么是数据分析
就是从现有的数据中挖掘出价值
为什么数据分析需要学python
python简单易学,并且是数据分析必备的语言
数据分析的工作流程
以下工作流程是一般情况下常见流程,也有可能会出现偏差
1.需求分析
搞明白到底要分析什么数据,以什么方式分析,想要什么样的结果
2.数据采集
数据的来源
1.公司内部自带
直接调用即可 MySQL MongoDB
2.网络爬虫获取
需要编写代码 爬虫相关技能
3.第三方服务
花钱直接购买 钞能力
3.数据清理
针对获取到的数据还需要效验是否符合分析条件
缺失数据,异常数据...
4.数据分析
选择相应的计算公式,算法模型分析数据
5.生成数据分析报告
撰写分析报告并给出分析之后的规律及建议
6.数据可视化
将复杂的数据用图表的形式展示出来,便于查看相应规律
数据可视化一般是结合数据分析报告一起
数据分析三剑客简介
numpy
数学计算模块 该模块是很多计算模块的底层模块
pandas
数据分析最为核心的模块之一 主要用于操作excel表格
matplotlib
数据可视化
ipython模块
可以在cmd终端中可以编写python代码
jupyter模块
该模块就可以进行数据分析相关的工作,但是有一个非常大的缺憾,就是数据分析过程中需要使用到的其他模块都需要自己下载
并且跟数据分析相关的模块不下于200个
Anaconda软件
内部集成了很多数据分析相关软件及功能,并且自动下载了接近300个数据分析相关模块
命令行模式与编辑模式
蓝色对应的是命令行模式,绿色对应的是编辑模式
两种模式的切换
编辑模式切换到命令行模式 按esc键
命令行模式切换到编辑模式 鼠标左键点击即可
1.运行当前单元格
ctrl+enter
2.运行当前单元格并选中下方的单元格
shift+enter
3.如何书写md格式的标题
方式1:命令行模式下按m键,之后按照#个数书写几级标签执行即可
方式2:编辑模式下先写文本,之后进入命令行模式按数字来控制几级标题
4.如何在当前单元格的下方新建一个单元格
命令行模式下按b键
5.如何在当前单元格的上方新建一个单元格
命令行模式下按a键
6.如何删除单元格
命令行模式下连续按两下d键
7.如何撤销删除
命令行模式下按z键
numpy科学计算库
1.numpy是高性能科学计算和数据分析的基础包
2.也是pandas等其他数据分析的工具的基础
3.numpy具有多维数组功能,计算更加高效快速
导入模块
import numpy
import numpy as np (更加倾向于起别名 np)
数据类型
布尔型 bool_
整型 int_ int8 int16 int32 int64
(int32只能表示(-1**31,2**31-1),因为它只有32个位,只能表示2**32个数)
无符号整型 uint8 uint16 uint32 uint64
浮点型 float_ float16 float32 float64
复数型 complex_ complex64 complex128
(几乎都是数字类的)
常用属性
T 数组的转置(对高维数组而言)
dtype 数组元素的数据类型
size 数组元素的个数
ndim 数组的维度
shape 数组的维度大小(以元组形式)
常用方法
(如何查看某个方法的使用说明)
方式1:在方法后面跟问号执行即可
方式2:写完方法名后先按shift不松开然后按tab即可(shift+tab)
array() 将列表转换成数组,可选择显示指定dtype
arange() range的numpy版,支持浮点型
linspace() 类似arange(),第三个参数为数组长度
zeros() 根据指定形状和dtype创建全0数组
ones() 根据指定形状和dtype创建全1数组
empty() 根据指定形状和dtype创建空数组(随机值)
eye() 根据指定边长和dtype创建单位矩阵
索引与切片
1.针对一维数组,索引与切片操作跟python中的列表完全一致
2.花式索引(间断索引)
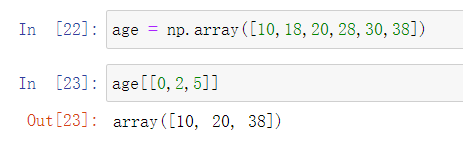
3.布尔值索引(逻辑索引)

4.针对二维数组索引与切片有些许复杂
res[行索引(切片),列索引(切片)]

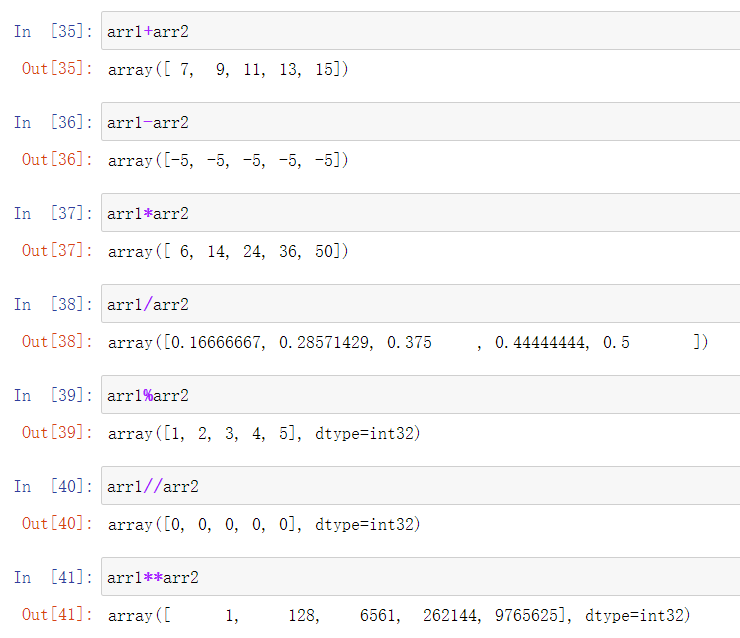
运算符
数学运算符
比较运算符
>
等价np.greater(arr1,arr2)
判断arr1的元素是否大于arr2的元素
>=
等价np.greater_equal(arr1,arr2)
判断arr1的元素是否大于等于arr2的元素
<
等价np.less(arr1,arr2)
判断arr1的元素是否小于arr2的元素
<=
等价np.less_equal(arr1,arr2)
判断arr1的元素是否小于等于arr2的元素
==
等价np.equal(arr1,arr2)
判断arr1的元素是否等于arr2的元素
!=
等价np.not_equal(arr1,arr2)
判断arr1的元素是否不等于arr2的元素

函数
常用的数学函数
np.round(arr)
对各元素四舍五入
np.sqrt(arr)
计算各元素的算术平方根
np.square(arr)
计算各元素的平方值
np.exp(arr)
计算以e为底的指数
np.power(arr,α)
计算各元素的指数
np.log2(arr)
计算以2为底各元素的对数
np.log10(arr)
计算以10为底各元素的对数
np.log(arr)
计算以e为底各元素的对数
常用的统计函数(重要)
np.min(arr,axis=1)
按照轴的方向计算最小值
np.max(arr,axis=1)
按照轴的方向计算最大值
np.mean(arr,axis=1)
按照轴的方向计算平均值
np.median(arr,axis=1)
按照轴的方向计算中位数
np.sum(arr,axis=1)
按照轴的方向计算和
np.std(arr,axis=1)
按照轴的方向计算标准差
np.var(arr,axis=1)
按照轴的方向计算方差

重要:
axis=0时,计算数组各列的统计值
axis=1时,计算数组各行的统计值
(不使用axis参数)
计算每一行的和

Sum = []
for row in range(4):
Sum.append(np.sum(arr2[row,:]))
# 计算每一列的平均
Avg = []
for col in range(5):
Avg.append(np.mean(arr2[:,col]))
使用axis参数
arr2.sum(axis = 1) # 等价np.sum(arr2, axis = 1) np.mean(arr2, axis = 0) # 等价arr2.mean(axis = 0)
随机数
numpy中的random子模块
np.random
rand 给定形状产生随机数组(0到1之间的数)
randint 给定形状产生随机整数
choice 给定形状产生随机选择
shuffle 与random.shuffle相同
uniform 给定形状产生随机数组(随机均匀分布)
normal 随机正态分布
pandas模块
基于numpy构建
pandas的出现,让Python语言成为使用最广泛而且最强大的数据分析语言
pandas针对表格文件的操作有非常大的优势
尤其是数据量超过10万的
pandas的主要功能
1.具备诸多功能的两大数据结构
series,dataframe
都是基于numpy构建出来的
公司中使用频繁的是dataframe,而series是构成dataframe的基础,即一个dataframe可能由n个series构成
2.集成时间序列功能
3.提供丰富的数学运算和操作(基于numpy)
4.灵活处理缺失数据
导入
import pandas import pandas as pd #更加习惯给它起一个别名
数据类型之series
是一种类似于一堆数组对象,由数据很相关的标签(索引)组成
第一种:
pd.series([4,5,6,7,8])
第二种:
pd.series([4,5,6,7,8],index=['a','b','c','d','e'])
第三种:
pd.Series({"a":1,"b":2})
第四种:
pd.Series(0,index=['a','b','c'])
缺失数据概念
在数据处理中如果遇到NaN关键字那么意思就是缺失数据
并且NaN属于浮点型
dropna() # 过滤掉值为NaN的行 fillna() # 填充缺失数据 isnull() # 返回布尔数组 notnull() # 返回布尔数组
数据修改规则
如何判断当前数据是否改变
1.如果执行操作之后有结果说明原数据没有变
obj1.fillna(666)
2.如果执行操作之后没有结果说明原数据改变
obj1.fillna(666,inplace=True)
inplace = True该参数很多方法都有,意思就是直接改变原数据
布尔值索引
布尔值索引的本质就是按照对应关系筛选出True对应的数据
mask = pd.Series([True,False,False,True,False]) price = pd.Series([321312,123,324,5654,645]) price[mask] price|mask (price>200) & (price<900) price[(price>200) & (price<900)] # 布尔求值
针对&符号衔接的条件都必须要加括号
行索引/行标签
设置数字行标签的时候,有时候会与自带的行索引冲突报错
这时就需要加一条代码说明自己使用的是行索引还是行标签
sr1.iloc[0] # 以行索引取值 sr1.loc['a'] # 以行标签取值
series数据操作
import pandas as pd res = pd.Series([111,222,333,444])
增
res['a'] = 123
查
res.loc[1]
改
res[0] = 1
删
del res[0]
算术运算符
add 加(add)
sub 减(substract)
div 除(divide)
mul 乘(multiple)
sr1 = pd.Series([12,23,34], index=['c','a','d']) sr3 = pd.Series([11,20,10,14], index=['d','c','a','b']) sr1.add(sr3,fill_value=0)
DataFrame创建方式
表格型数据结构,相当于一个二维数组,含有一组有序的列,也可以看作是由series组成的共用一个索引的字典
第一种
res = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
第二种
pd.DataFrame({'one':pd.Series([1,2,3],
index=['a','b','c']),
'two':pd.Series([1,2,3],
index=['b','a','c'])})
(以上创建方式都仅仅做一个了解即可
因为工作中dataframe的数据一般都是来自于读取外部文件数据,而不是自己动手去创建)
常见属性
1.index 行索引
2.colums 列索引
3.T 转置
4.values 值索引
5.describe 快速统计
DataFrame数据类型补充
在dataframe中所有的字符类型数据在查看数据类型的时候都表示成object
读取外部数据
pd.read_csv() 可以读取文本文件和.csv结尾的文件数据
pd.read_excel() 可以读取excel表格文件数据
pd.read_sql() 可以读取MySQL表格数据
pd.read_html() 可以读取网页上table标签内所有的数据
文本文件读取
filepath_or_buffer:指定txt文件或csv文件所在的具体路径
sep:指定原数据集中各字段之间的分隔符,默认为逗号
id name income
1 jason 10
header:是否需要将原数据集中的第一行作为表头,默认将第一行用作字段名称
(如果不想把第一行数据作为表头需要将该参数设置为none)
names:如果原数据集中没有表头字段,可以通过该参数在数据读取时给数据框添加具体的表头
usecols:指定需要读取读数据集中的哪些变量名
skiprows:数据读取时,指定需要跳过原数据集开头的行数
(有一些表格开头是有几行文字说明的,读取的时候应该跳过)
skipfooter:数据读取时,指定需要跳过原数据集末尾的行数
converters:用于数据类型的转换(以字典的形式指定)
encoding:如果文件中含有中文,有时需要指定字符编码
基本使用
import pandas as pd
data01 = pd.read_csv(r'data_test01.txt',
skiprows = 2, # python能自动过滤掉完全无内容的空行(写2、3都行)
sep = ',', # 默认就是逗号 写不写都行
skipfooter = 3,
)
# 1.针对id原本是01、02自动变成了1、2...
converters = {'id':str}
# 2.点击文件另存修改文件编码之后再次读取出现乱码
encoding='utf-8'
# 3.移除收入千分位非逗号的其他符号
thousands = '&'
# 4.手动将文件表头行删除再次读取
header = None # 默认用索引
names = ['id','year','month','day','gender','occupation','income']
# 5.指定读取的字段
usecols = ['id','income']
excel表格读取
pd.read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None, names=None, na_values=None, thousands=None, convert_float=True)
io:指定电子表格的具体路径
sheet_name:指定需要读取电子表格中的第几个sheet,既可以传递整数也可以传递具体的sheet名称
header:是否需要将数据集的第一行用作表头,默认是需要的
skiprows:读取数据时,指定跳过的开始行数
skip_footer:读取数据时,指定跳过的末尾行数
index_col:指定哪些列用作数据框的行索引(标签)
na_values:指定原始数据中哪些特殊值代表了缺失值
thousands:指定原始数据集中的千分位符
convert_float:默认将所有的数值型字段转换为浮点型字段
converters:通过字典的形式,指定某些列需要转换的形式
pd.read_excel(r'data_test02.xlsx',
header = None,
names = ['ID','Product','Color','Size'],
converters = {'ID':str}
)
数据库数据读取
在anaconda环境下直接安装pymysql模块
host:指定需要访问的MySQL服务器
port:指定访问MySQL数据库的端口号
charset:指定读取MySQL数据库的字符集,如果数据库表中含有中文,一般可以尝试将该参数设置为'utf8'或'gbk'
user:指定访问MySQL数据库的用户名
password:指定访问MySQL数据库的密码
database:指定访问MySQL数据库的具体库名
利用pymysql创建好链接MySQL的链接之后即可通过该链接操作MySQL
pd.read_sql('select * from user', con = conn)
conn.close() # 关闭链接
网页表格数据读取
pd.read_html(r'https://baike.baidu.com/item/NBA%E6%80%BB%E5%86%A0%E5%86%9B/2173192?fr=aladdin')
数据概览
df.columns 查看列
df.index 查看行
df.shape 行列
df.dtypes 数据类型
df.head() 取头部多条数据
df.tail() 取尾部多条数据
行列操作
获取指定列对应的数据
df['列字段名词']
修改列名
df.rename(column={'旧列名称':'新列名称'})
创建新的列
df['新列名称']=df.列名称/(df.列名称1+df.列名称2)
自定义位置
df.insert(3,'新列名称',新数据)
添加行
df3 = df1.append(df2)
数据筛选
获取指定列数据
df['列名'] # 单列数据 df[['列名1','列名2',...]] # 多列数据
获取指定行数据
sec_buildings.loc[sec_buildings["region"] == '浦东'] sec_buildings.loc[(sec_buildings["region"] == '浦东') & (sec_buildings['size'] > 150),] sec_buildings.loc[(sec_buildings["region"] == '浦东') & (sec_buildings['size'] > 150),['name','tot_amt','price_unit']]
数据处理
sec_car = pd.read_csv(r'sec_cars.csv') sec_car.head() sec_car.dtypes sec_car.Boarding_time = pd.to_datetime(sec_car.Boarding_time, format = '%Y年%m月') sec_car.New_price = sec_car.New_price.str[:-1].astype(float)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号