
pandas模块
numpy小练习
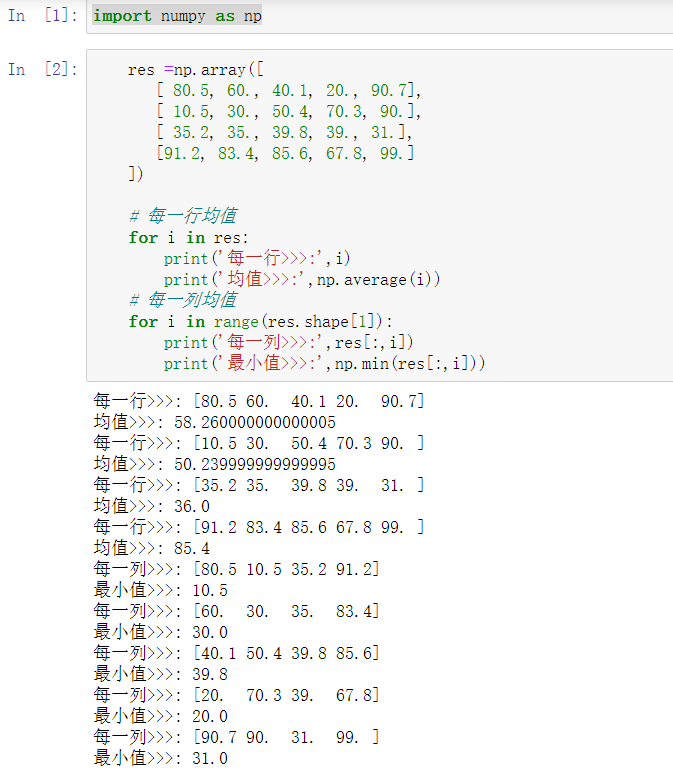
1.计算数组每一行和每一列的中位数(不能使用axis参数)
import numpy as np res =np.array([ [ 80.5, 60., 40.1, 20., 90.7], [ 10.5, 30., 50.4, 70.3, 90.], [ 35.2, 35., 39.8, 39., 31.], [91.2, 83.4, 85.6, 67.8, 99.] ]) # 每一行均值 for i in res: print('每一行>>>:',i) print('均值>>>:',np.average(i)) # 每一列均值 for i in range(res.shape[1]): print('每一列>>>:',res[:,i]) print('最小值>>>:',np.min(res[:,i]))
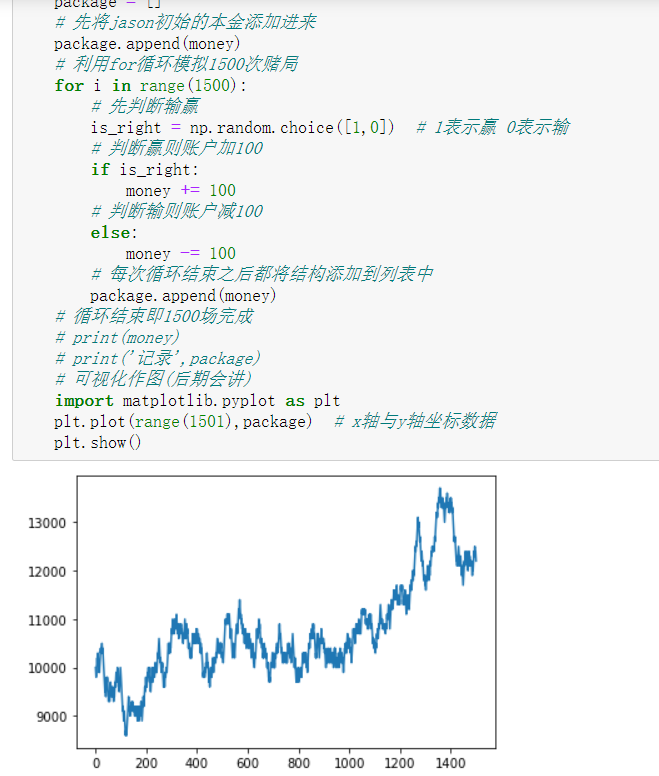
2.jason有10000块钱,去某赌场嗨皮
假设输赢概率都是50%,并且赢一场赚100,输一场亏100
jason总共玩了1500场,写程序计算1500场之后jason还剩多少钱
"""统计jason每一次赌完后账户总额""" # 先定义一个变量存储jason的本金 money = 10000 # 再定义一个存储每次赌局之后账户金额的变量 package = [] # 先将jason初始的本金添加进来 package.append(money) # 利用for循环模拟1500次赌局 for i in range(1500): # 先判断输赢 is_right = np.random.choice([1,0]) # 1表示赢 0表示输 # 判断赢则账户加100 if is_right: money += 100 # 判断输则账户减100 else: money -= 100 # 每次循环结束之后都将结构添加到列表中 package.append(money) # 循环结束即1500场完成 # print(money) # print('记录',package) # 可视化作图(后期会讲) import matplotlib.pyplot as plt plt.plot(range(1501),package) # x轴与y轴坐标数据 plt.show()
pandas模块简介
基于numpy构建
pandas的出现,让Python语言成为使用最广泛而且最强大的数据分析语言
pandas针对表格文件的操作有非常大的优势
尤其是数据量超过10万的
pandas的主要功能
1.具备诸多功能的两大数据结构
series,dataframe
都是基于numpy构建出来的
公司中使用频繁的是dataframe,而series是构成dataframe的基础,即一个dataframe可能由n个series构成
2.集成时间序列功能
3.提供丰富的数学运算和操作(基于numpy)
4.灵活处理缺失数据
python纯开发条件下
pip3 install pandas
anaconda环境下
canda install pandas
(anaconda已经自动帮助我们下载好了数据分析相关的模块,其实无需我们再下载)
导入
import pandas import pandas as pd #更加习惯给它起一个别名
补充
数据分析三剑客模块由于使用频率很高,所以在很多ipynb文件的开头都会提前导入
import numpy as np import pandas as pd
数据类型之series
是一种类似于一堆数组对象,由数据很相关的标签(索引)组成
第一种:
pd.series([4,5,6,7,8])
第二种:
pd.series([4,5,6,7,8],index=['a','b','c','d','e'])
第三种:
pd.Series({"a":1,"b":2})
第四种:
pd.Series(0,index=['a','b','c'])
缺失数据概念
在数据处理中如果遇到NaN关键字那么意思就是缺失数据
并且NaN属于浮点型
dropna() # 过滤掉值为NaN的行 fillna() # 填充缺失数据 isnull() # 返回布尔数组 notnull() # 返回布尔数组
数据修改规则
如何判断当前数据是否改变
1.如果执行操作之后有结果说明原数据没有变
obj1.fillna(666)
2.如果执行操作之后没有结果说明原数据改变
obj1.fillna(666,inplace=True)
inplace = True该参数很多方法都有,意思就是直接改变原数据
布尔值索引
布尔值索引的本质就是按照对应关系筛选出True对应的数据
mask = pd.Series([True,False,False,True,False]) price = pd.Series([321312,123,324,5654,645]) price[mask] price|mask (price>200) & (price<900) price[(price>200) & (price<900)] # 布尔求值
针对&符号衔接的条件都必须要加括号
行索引/行标签
设置数字行标签的时候,有时候会与自带的行索引冲突报错
这时就需要加一条代码说明自己使用的是行索引还是行标签
sr1.iloc[0] # 以行索引取值 sr1.loc['a'] # 以行标签取值
