第七周总结
网络爬虫简介
常见收集数据网站
详见网络爬虫简介 - 雾雨黑白 - 博客园 (cnblogs.com)
我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程
跳过代码模拟网络请求获取数据并解析数据最后保存
浏览器请求数据展示的界面其实内部对应就是一堆HTML代码
爬虫程序说白了就是对这一对HTML代码做数据筛选
所以写好爬虫程序的第一步就是熟悉HTML代码基本组成
HTML:超文本标记语言
浏览器可以展示出来的界面都是由HTML构成的
eg:淘宝 天猫 京东 链家
网页文件一般都是以.html结尾
<html>
<head>书写的一般都是给浏览器看的</head>
<body>书写的就是浏览器要展示给用户看的</body>
</html>
head内常见标签(了解)
title 定义网页标题
style 内部直接书写css代码
link 引入外部css文件
script 内部可以直接书写js代码也可以引入外部js文件
meta 定义网页源信息
<meta name="description" content="京东JD.COM-专业的综合网上购物商城,为您提供正品低价的购物选择、优质便捷的服务体验。商品来自全球数十万品牌商家,囊括家电、手机、电脑、服装、居家、母婴、美妆、个护、食品、生鲜等丰富品类,满足各种购物需求。">
<meta name="Keywords" content="网上购物,网上商城,家电,手机,电脑,服装,居家,母婴,美妆,个护,食品,生鲜,京东">
双标签(有头有尾)
链接 <a></a>
单标签(自闭和)
图片 <img/>
标题 h1~h6
下划线 u
删除线 s
斜体 i
加粗 b
段落标签 p
水平线 hr
换行 br
正则表达式
特殊符号
空格
> >
< <
& &
¥ ¥
版权 ©
注册 ®
<a href="https://www.sogo.com">链接标签</a>
href参数后面写网址 用户点击即可跳转到该网页
<img src="111.png" alt="">图片标签
src参数后面写图片的地址 可以是网络上的也可以是本地的
<div>页面布局标签</div>
是所有网页中出现频率最高的标签 内部可以无限制的嵌套任意标签
<span>页面文本标签</span>
是所有网页中涉及到文字可能会出现的标签 频率并不是太高
<ul>
<li>001</li>
<li>002</li>
<li>003</li>
<li>004</li>
<li>005</li>
</ul>
"""在网页上看似有规则排列的横向或者竖向的内容基本都是用列表标签完成的"""
'''涉及到多条相同格式数据展示的时候可以考虑使用表格标签(类似于excel)'''
<table>
<thead>
<tr>
<th>序号</th> <!--书写一个个字段名-->
<th>姓名</th>
<th>年龄</th>
</tr> <!--一个tr就是一行-->
</thead> <!--书写表头数据(字段名)-->
<tbody>
<tr>
<td>1</td> <!--书写一个个真实数据-->
<td>jason</td>
<td>123</td>
</tr>
</tbody> <!--书写表单数据(真实数据)-->
</table>
"""涉及到用户数据的获取一般都需要使用表单标签"""
input标签
type参数
text 普通文本
password 密文展示
email 邮箱格式
date 日期格式
radio 单选
checkbox 多选
file 文件
submit 提交按钮
reset 重置按钮
button 普通按钮
select标签
option子标签
textarea标签
获取大段文本
<a id='' class=''></a>
上述id、class等都称之为a标签的属性
"""标签两大核心属性"""
id # 单独查找某个人
类似于标签的身份证号码 用于唯一标识标签
在同一个html文档中id不能重复
class # 批量查找一群人
类似于标签的种群(类别) 用于区分不同的类
在用一个html文档中class值可以重复 表示属于同一个类别
eg:
<p class='c1'></p>
<a class='c1'></a>
<div class='c1'></div>
一个标签可以含有多个class值
<span class='c1 c2 c3'></span>
"""标签还可以自定义任意的属性"""
<a username='jason' pwd=123></a>
"""标签之间的关系描述"""
<div>只要是div内部的标签都可以称之为是div的后代
<a>上一级div的儿子</a>
<p>上一级div的儿
<span>上一级p的儿上上一级div的孙子</span>
</p>
<div>上一级div的儿
<a>上一级div的儿子上上一级div的孙子</a>
</div>
<span>上一级div的儿</span>
</div>
正则表达式
如何限制手机号条件?
import re
phone_number = input('please input your phone number : ')
if re.match('^(13|14|15|18)[0-9]{9}$',phone_number):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
# 字符组在匹配内容的时候是单个单个字符挨个匹配
[0123456789] 匹配0到9之间的任意一个数字包括首尾
[0-9] 简写:匹配0到9之间的任意一个数字包括首尾
[a-z] 匹配小写字母a到z之间的任意一个字母包括首尾
[A-Z] 匹配大写字母A到Z之间的任意一个字母包括首尾
[0-9a-zA-Z] 匹配数字或者小写字母或者大写字母
# 符号在匹配内容的时候是单个单个字符挨个匹配
. 匹配除换行符以外的任意字符
\d 匹配数字
^ 匹配字符串的开始
$ 匹配字符串的结尾
a|b 匹配字符a或字符b
() 给正则表达式分组 本身没有任何意义
[...] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符(取反)
# 跟在正则表达式的后面可以一次性匹配多个字符
'''量词必须跟在正则表达式后面 不能单独出现使用'''
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
\n 匹配的是换行符
\\n 匹配的是\n
\\\\n 匹配的是\\n
# 如果想在python代码中使用正则表达式需要借助于内置模块re
import re
text = '<script>123</script>'
res = re.findall('<.*?>',text)
print(res)
requests

import re s=""" eva jason tony yuan jason jason jaosn a """
findall(正则,文本数据)
在匹配的时候是全局匹配,不会因为匹配到一个就停止
返回结果是一个列表,内部包含正则匹配到的所有的内容
ret = re.findall('j.*?n',s) # 返回所有满足匹配条件的结果,放在列表里
print(ret)
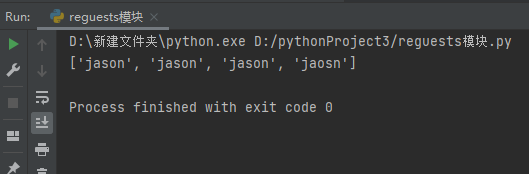
finditer(正则,文本数据)
返回的结果是一个迭代器(更加节省内存)只有主动索要才会产生数据,否则永远之战一块空间
# 暂时了解
res = re.finditer('j.*?n',s)
for i in res:
print(i.group())
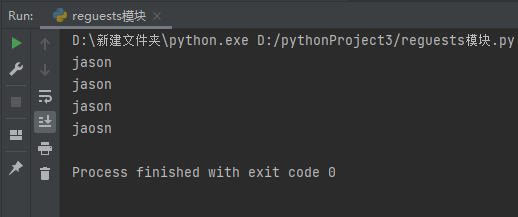
search
匹配到一个符号条件的数据就结束
res = re.search('j.*?n',s)
print(res)
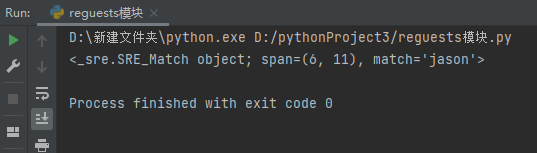
match
只能从头开始匹配,头部不符合直接停止
res1 = re.match('j.*?n',s)
print(res1)
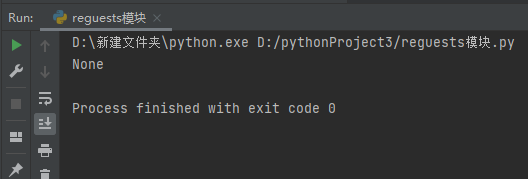
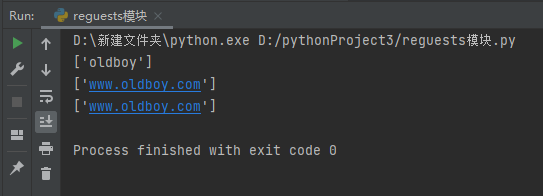
findall分组优先展示
会优先展示括号内正则表达式匹配到的内容
import re
ret = re.findall('www.(oldboy).com','www.oldboy.com')
print(ret)
# 取消分组优先展示
ret1 = re.findall('www.(?:oldboy).com','www.oldboy.com')
print(ret1)
ret = re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret)
爬虫模块之requests
作用
可以模拟浏览器发送网络请求获取数据
先下载
pip3 install requests
1.切换源
2.针对报错
再导入
import requests
网络请求方法
网络方法一般有八个之多,但是目前需要我们掌握的只有两个
get请求
朝别人索要数据
eg:浏览器地址输入百度网址,回车,其实就是在发送get请求,朝百度服务器索要百度首页
get请求也可以携带额外的数据,但是数据量有限制最多2~4KB,并且是直接卸载网址的后面
url?xxx=yyy&zzz=mmm
post请求
朝别人提交数据
eg:用户注册登陆输入需要输入用户名和密码之后点击按钮发送post请求将数据提交给远程服务器
post请求也可以携带额外的数据,并且数据大小没有限制,敏感性的数据都是由post请求携带
数据放在请求体中
HTTP协议
规定了浏览器与服务端之间数据交互的方式
1.四大特性(重要)
1.基于请求响应
2.基于TCP、IP作用于应用层之上的协议
3.无状态
不保存客户端的状态
eg:
纵使见她千百遍,我都待她如初见
4.无连接
2.数据请求格式(重要)
请求数据格式
请求首行(请求方法,地址...)
请求头(一大堆K:V键值对)
'''注意:此处必须空一行'''
请求体(get请求没有请求体,post请求有,里面是敏感数据)
响应数据格式
响应首行(响应状态码,协议版本...)
响应头(一大堆K:V键值对)
'''注意:此处必须空一行'''
响应体(一般都是给浏览器展示给用户看的数据)
3.响应状态码(重要)
用简单的数字来表示一串中文意思(制定暗号)
1xx:服务端已经成功接收到了你的数据正在处理,你可以继续提交或者等待
2xx:200 OK请求成功服务端发送了响应
3xx:重定向(原本想访问A页面但是内部自动跳到了B页面)
4xx:403 请求不符合条件 404 请求资源不存在
5xx:服务端内部错误
(公司还会自己自定义响应状态码(HTTP的状态码太少不够用)
10001
10002
参考网址:聚合数据)
requests模块基本使用
发送网络请求
import requests requests.get(url) # 发送get请求 requests.post(url) # 发送post请求
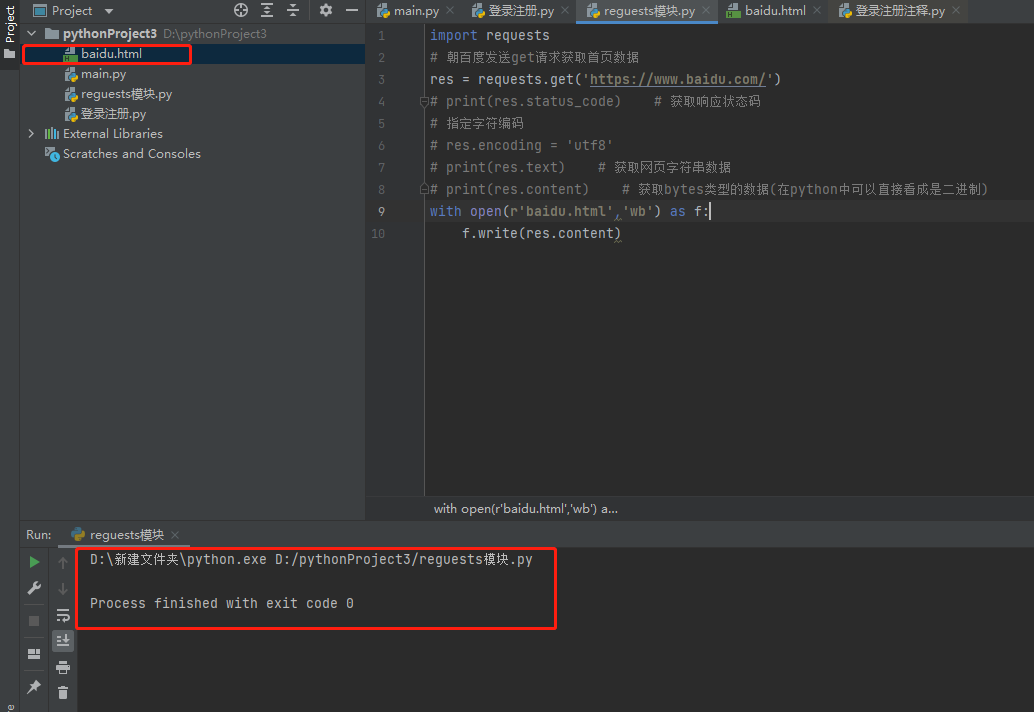
1.简单的get请求获取页面并报错
import requests
# 朝百度发送get请求获取首页数据
res = requests.get('https://www.baidu.com/')
# print(res.status_code) # 获取响应状态码
# 指定字符编码
# res.encoding = 'utf8'
# print(res.text) # 获取网页字符串数据
# print(res.content) # 获取bytes类型的数据(在python中可以直接看成是二进制)
with open(r'baidu.html','wb') as f:
f.write(res.content)


2.携带参数的get请求
requests.get(url,params{})
3.如何携带请求头数据
requests.get(url,headers={})
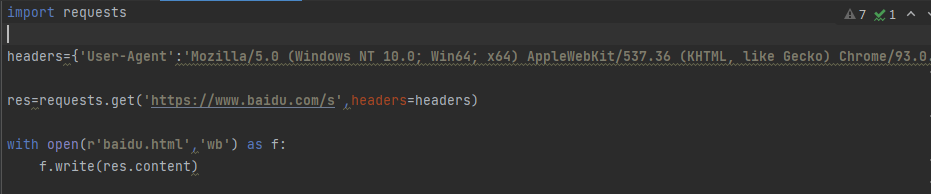
防爬措施
1.效验当前请求是否是浏览器发出的
用于效验的核心就在于请求头里面的User-Agent键值对
只要请求里面含有该键值对就表示你是个浏览器没有则不是浏览器
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36
解决措施在请求头中加上即可
requests.get(url,headers={...})
cookie
cookie与session
cookie与session的发明是专门用来解决http协议无状态的特点
http协议无状态>>>:不保存用户端状态(记不住)
(早期的网址不需要保存用户状态,所有人来访都是相同的数据)
随着时代的发展越来越多的网址需要保存用户状态(记住你)
cookie:保存在客户端浏览器上面的键值对数据
(用户第一次登陆成功之后,浏览器会保存用户名和密码
之后访问网站都会自动带着该用户名和密码)
session:保存在服务端上面的用户相关的数据
(用户第一次登陆成功之后,服务端会返回给客户端一个随机字符串(有时候也可能是多个)
客户端浏览器保存该随机字符串之后访问网站都带着该随机字符串)
cookie和session是什么关系:session需要依赖cookie
只要是涉及到用户登录都需要使用到cookie
ps:浏览器也可以拒绝保存数据
cookie实战
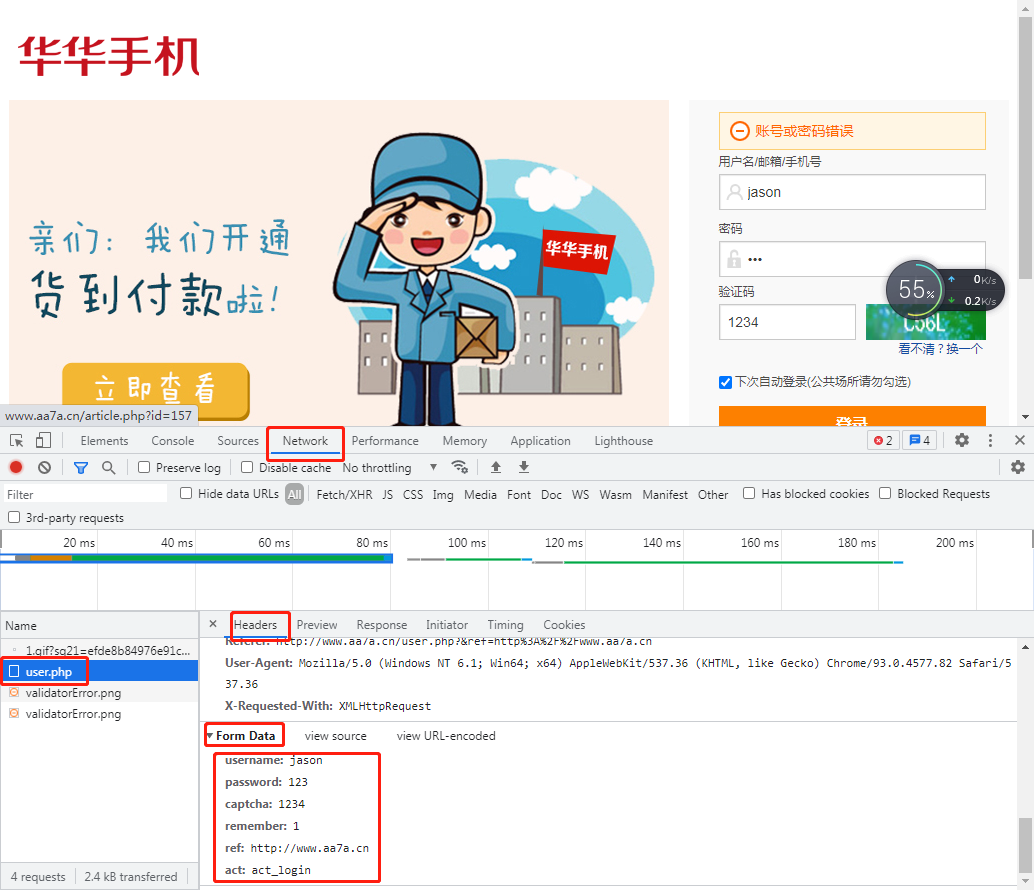
(浏览器network选项中,请求体对应的关键字是Form Date)
登陆地址:http://www.aa7a.cn/user.php
请求体数据格式
username: password: captcha: remember: ref: act:
写爬虫一定是先使用浏览器研究再写代码
1.研究登陆数据提交给后端的url地址
2.研究登陆post请求携带的请求体数据格式
3.模拟发送post请求
import requests
res = requests.post('http://www.aa7a.cn/user.php',
data={
'username': 'jason',
'password': '123',
'captcha': '1234',
'remember': 1,
'ref': 'http://www.aa7a.cn',
'act': 'act_login',
}
)
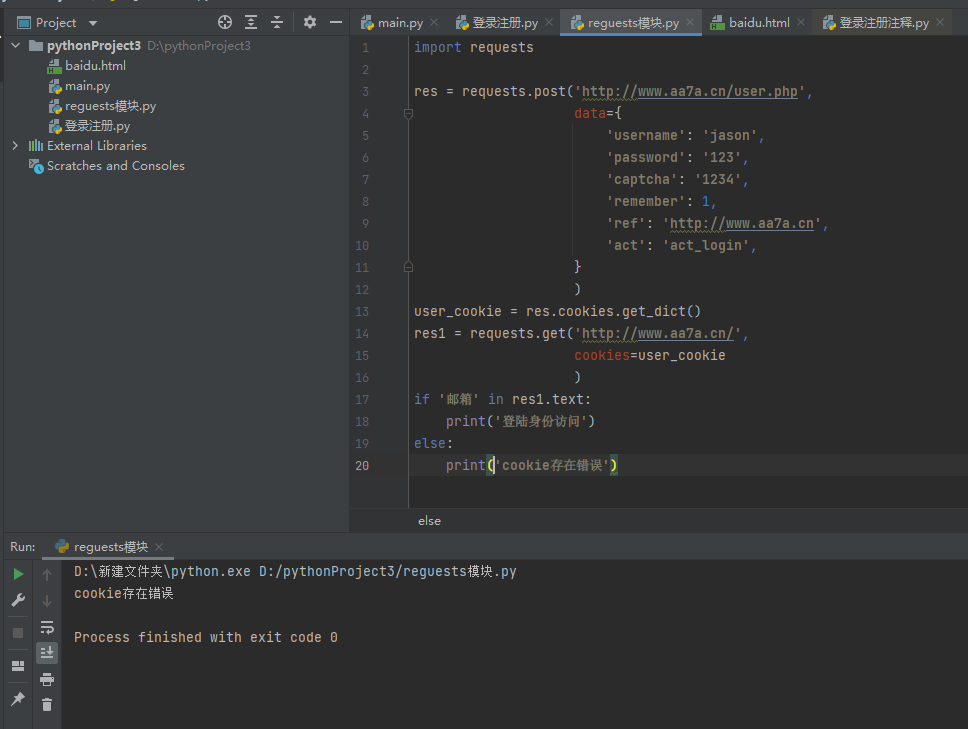
获取cookie数据
print(res.cookies.get_dict()) user_cookie = res.cookies.get_dict()
用户名或密码错误的情况下返回的cookie数据
{'ECS[visit_times]': '1', 'ECS_ID': '69763617dc5ff442c6ab713eb37a470886669dc2'}
用户名和密码都正确的情况下返回的cookie数据
{
'ECS[password]': '4a5e6ce9d1aba9de9b31abdf303bbdc2',
'ECS[user_id]': '61399',
'ECS[username]': '616564099%40qq.com',
'ECS[visit_times]': '1',
'ECS_ID': 'e18e2394d710197019304ce69b184d8969be0fbd'
}
使用cookie访问网站
res1 = requests.get('http://www.aa7a.cn/',
cookies=user_cookie
)
if '邮箱' in res1.text:
print('登陆身份访问')
else:
print('cookie存在错误')
获取大数据
stream参数:一点一点的取,比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的
import requests
response=requests.get('http://www.shiping.com/xxx.mp4',
stream=True)
with open('b.mp4','wb') as f:
for line in response.iter_content(): # 一行一行读取内容
f.write(line)

json格式
json格式的数据有一个非常显著的特征>>>:引号肯定是双引号
在网络爬虫领域,其实内部有很多数据都是采用的json格式
(前后端数据交互一般使用的都是json)
import requests
res = requests.get('https://api.bilibili.com/x/player/pagelist?bvid=BV1QE41147hU&jsonp=jsonp')
print(res.json()) # 可以直接将json格式字符串转换成python对应的数据类型
SSL相关报错(苹果电脑常见)
直接百度搜索即可
IP代理池
有很多网站针对客户端的IP地址也存在防爬措施
eg:比如一分钟之内同一个IP地址访问该网站的次数不能超过30次,超过了就封禁该IP地址
针对该防爬措施如何解决?
IP代理池
里面有很多IP地址每次访问从中随机挑选一个
# 代理设置:先发送请求给代理,然后由代理帮忙发送(封ip是常见的事情)
import requests
proxies={
'http':'114.99.223.131:8888',
'http':'119.7.145.201:8080',
'http':'175.155.142.28:8080',
}
respone=requests.get('https://www.12306.cn',
proxies=proxies)
cookie代理池
有很多网站针对客户端的cookie也存在防爬措施
eg:比如一分钟之内同一个cookie访问该网站的次数不能超过30次,超过了就封禁该cookie
针对该防爬措施如何解决?
cookie代理池
里面有很多cookie每次访问从中随机挑选一个
respone=requests.get('https://www.12306.cn',
cookies={})
网络爬虫练习
详见:网络爬虫练习 - 雾雨黑白 - 博客园 (cnblogs.com)
bs4模块
设置延迟
涉及到多页数据爬取的时候,最好不要太频繁,可以自己主动设置延迟
for i in range(1, 5):
time.sleep(1)
get_price_data(i)
爬虫解析库之bs4模块
全名:Beautiful Soup4
是一个可以从HTML或XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,Beautiful Soup会帮你节省数小时甚至数天的工作时间
模块下载
pip3 install beautifulsoup4
配套解析器下载
pip3 install lxml
bs4模块基本使用
from bs4 import BeautifulSoup
构建一个网页数据
html_doc = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title">
<b>The Dormouse's story</b>
</p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
</html>
"""
1.构筑一个bs4解析器对象
soup = BeautifulSoup(html_doc, 'lxml')
2.利用对象的内置方法完成一系列操作
必须要掌握
print(soup.a) # 从上往下的第一个a标签 soup.标签名称
print(soup.p.text) # 获取标签内部的文本 包含内部所有的后代标签文本
print(soup.a.attrs) # 获取标签内部所有的属性 字典数据类型
print(soup.a.attrs.get('href'))
print(soup.a.get('href')) # 可以简写 省略attrs参数
了解
print(soup.p.children) # 获取标签内部所有的子标签 需要循环取值才可以拿到 print(soup.p.contents) # 获取标签内部所有的元素 了解即可 print(soup.p.parent) # 获取标签的父标签 print(soup.p.parents) # 获取标签的所有祖先标签
bs4核心操作
1.find方法
缺陷:只能找符合条件的第一个数据,该方法的返回结果是一个标签对象
print(soup.find(name='a')) # 查找指定标签名的标签 默认只找符合条件的第一个
print(soup.find(name='a',id='link2')) # 查找具有某个特定属性的标签 默认只找符合条件的第一个
print(soup.find(name='p', class_='title')) # 为了解决关键字冲突 会加下划线区分
print(soup.find(name='p', attrs={'class': 'title'})) # 还可以使用attrs参数 直接避免冲突
print(soup.find(name='a', attrs={'id': 'link3'})) # 还可以使用attrs参数 直接避免冲突
print(soup.find(name='a', attrs={'class': 'c1'})) # class属性查找属于成员运算 有就行
print(soup.find(attrs={'class': 'c1'})) # name参数不写则表示查找所有符合后续条件的标签
2.find_all方法
优势:查找所有符合条件的标签,该方法的返回结果是一个列表
print(soup.find_all('a')) # name字段可以省略 查找的结果是一个列表
(find_all()使用方式与find一致 知识结果数量不一样而已)
3.select方法
需要使用css选择器,该方法的返回结果是一个列表
<p></p>
<div>
<a></a>
<p>
<a></a>
</p>
<div><p></p></div>
</div>
<p></p>
<p></p>
1.标签选择器
直接书写标签名即可
2.id选择器
#d1 相当于写了id='d1'
3.class选择器
.c1 相当于写了class='c1'
4.儿子选择器
div>p 查找标签内部所有的儿子p
5.后代选择器
div p 查找div标签内部所有的后代p
(选择器可以混合使用)
print(soup.select('.title')) # 查找class含有title的标签
print(soup.select('.sister span')) # 查看class含有sister标签内部所有的后代span
print(soup.select('#link1')) # 查找id等于link1的标签
print(soup.select('#link1 span')) # 查找id等于link1标签内部所有的后代span
print(soup.select('#list-2 .element')) # 查找id等于list-2标签内部所有class为element的标签
print(soup.select('#list-2')[0].select('.element')) #可以一直select,但其实没必要,一条select就可以了
爬取红牛分公司数据
需求:获取红牛所有分公司详细数据(名称,地址,邮箱,电话)
http://www.redbull.com.cn/about/branch
1.查找数据加载方式,得知是直接加载的
2.朝该网页发送请求获取网页数据之后筛选即可
import requests
from bs4 import BeautifulSoup
# 1.发送get请求获取页面内容
res = requests.get('http://www.redbull.com.cn/about/branch')
# 2.解析页面数据
soup = BeautifulSoup(res.text, 'lxml')
# 3.研究标签特性 精确查找
# 分公司名称数据
h2_tag_list = soup.find_all('h2') # 查找到所有的h2标签对象
# for tag in h2_tag_list:
# print(tag.text)
# 使用列表生成式
title_list = [tag.text for tag in h2_tag_list]
# 分公司地址数据
p1_tag_list = soup.find_all(name='p', attrs={'class': 'mapIco'})
# for tag in p_tag_list:
# print(tag.text)
# 使用列表生成式
addr_list = [tag.text for tag in p1_tag_list]
# 分公司邮箱数据
p2_tag_list = soup.find_all(name='p', attrs={'class': 'mailIco'})
# for tag in p2_tag_list:
# print(tag.text)
email_list = [tag.text for tag in p2_tag_list]
# 分公司电话数据
p3_tag_list = soup.find_all(name='p', attrs={'class': 'telIco'})
# for tag in p3_tag_list:
# print(tag.text)
phone_list = [tag.text for tag in p3_tag_list]
for i in range(len(title_list)):
print("""
公司名称:%s
公司地址:%s
公司邮箱:%s
公司电话:%s
""" % (title_list[i], addr_list[i], email_list[i], phone_list[i]))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号