cookie
cookie与session
cookie与session的发明是专门用来解决http协议无状态的特点
http协议无状态>>>:不保存用户端状态(记不住)
(早期的网址不需要保存用户状态,所有人来访都是相同的数据)
随着时代的发展越来越多的网址需要保存用户状态(记住你)
cookie:保存在客户端浏览器上面的键值对数据
(用户第一次登陆成功之后,浏览器会保存用户名和密码
之后访问网站都会自动带着该用户名和密码)
session:保存在服务端上面的用户相关的数据
(用户第一次登陆成功之后,服务端会返回给客户端一个随机字符串(有时候也可能是多个)
客户端浏览器保存该随机字符串之后访问网站都带着该随机字符串)
cookie和session是什么关系:session需要依赖cookie
只要是涉及到用户登录都需要使用到cookie
ps:浏览器也可以拒绝保存数据
cookie实战
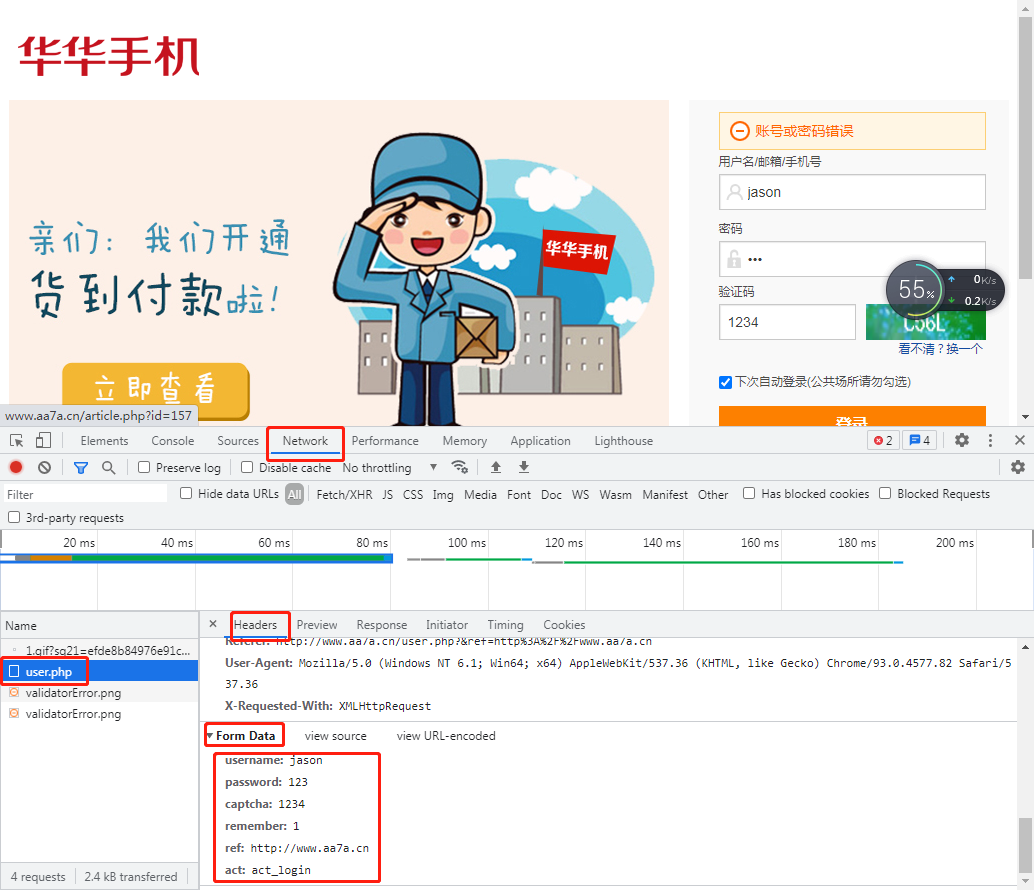
(浏览器network选项中,请求体对应的关键字是Form Date)
登陆地址:http://www.aa7a.cn/user.php
请求体数据格式
username:
password:
captcha:
remember:
ref:
act:
写爬虫一定是先使用浏览器研究再写代码
1.研究登陆数据提交给后端的url地址
2.研究登陆post请求携带的请求体数据格式
3.模拟发送post请求
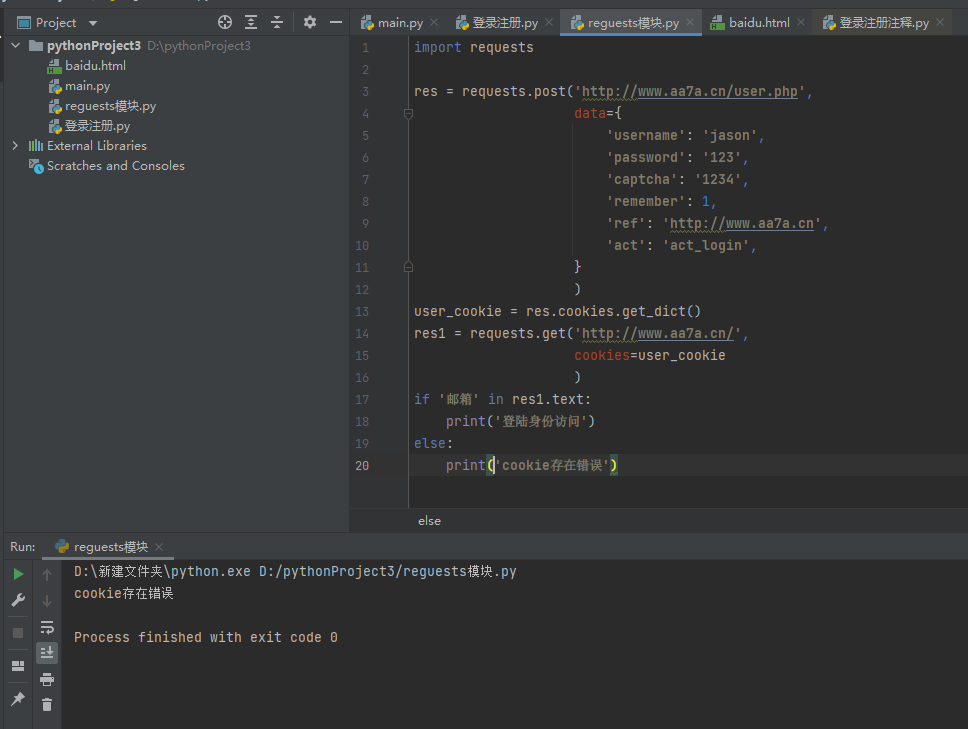
import requests res = requests.post('http://www.aa7a.cn/user.php', data={ 'username': 'jason', 'password': '123', 'captcha': '1234', 'remember': 1, 'ref': 'http://www.aa7a.cn', 'act': 'act_login', } )
获取cookie数据
print(res.cookies.get_dict()) user_cookie = res.cookies.get_dict()
用户名或密码错误的情况下返回的cookie数据
{'ECS[visit_times]': '1', 'ECS_ID': '69763617dc5ff442c6ab713eb37a470886669dc2'}
用户名和密码都正确的情况下返回的cookie数据
{ 'ECS[password]': '4a5e6ce9d1aba9de9b31abdf303bbdc2', 'ECS[user_id]': '61399', 'ECS[username]': '616564099%40qq.com', 'ECS[visit_times]': '1', 'ECS_ID': 'e18e2394d710197019304ce69b184d8969be0fbd' }
使用cookie访问网站
res1 = requests.get('http://www.aa7a.cn/', cookies=user_cookie ) if '邮箱' in res1.text: print('登陆身份访问') else: print('cookie存在错误')
获取大数据
stream参数:一点一点的取,比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的
import requests response=requests.get('http://www.shiping.com/xxx.mp4', stream=True) with open('b.mp4','wb') as f: for line in response.iter_content(): # 一行一行读取内容 f.write(line)

json格式
json格式的数据有一个非常显著的特征>>>:引号肯定是双引号
在网络爬虫领域,其实内部有很多数据都是采用的json格式
(前后端数据交互一般使用的都是json)
import requests res = requests.get('https://api.bilibili.com/x/player/pagelist?bvid=BV1QE41147hU&jsonp=jsonp') print(res.json()) # 可以直接将json格式字符串转换成python对应的数据类型
SSL相关报错(苹果电脑常见)
直接百度搜索即可
IP代理池
有很多网站针对客户端的IP地址也存在防爬措施
eg:比如一分钟之内同一个IP地址访问该网站的次数不能超过30次,超过了就封禁该IP地址
针对该防爬措施如何解决?
IP代理池
里面有很多IP地址每次访问从中随机挑选一个
# 代理设置:先发送请求给代理,然后由代理帮忙发送(封ip是常见的事情)
import requests proxies={ 'http':'114.99.223.131:8888', 'http':'119.7.145.201:8080', 'http':'175.155.142.28:8080', } respone=requests.get('https://www.12306.cn', proxies=proxies)
cookie代理池
有很多网站针对客户端的cookie也存在防爬措施
eg:比如一分钟之内同一个cookie访问该网站的次数不能超过30次,超过了就封禁该cookie
针对该防爬措施如何解决?
cookie代理池
里面有很多cookie每次访问从中随机挑选一个
respone=requests.get('https://www.12306.cn', cookies={})
