Flink学习(十九) 容错机制
主要内容:
一致性检查点(checkpoint)
从检查点恢复到状态
Flink检查点算法
保存点(savepoint)
一致性检查点(checkpoint)
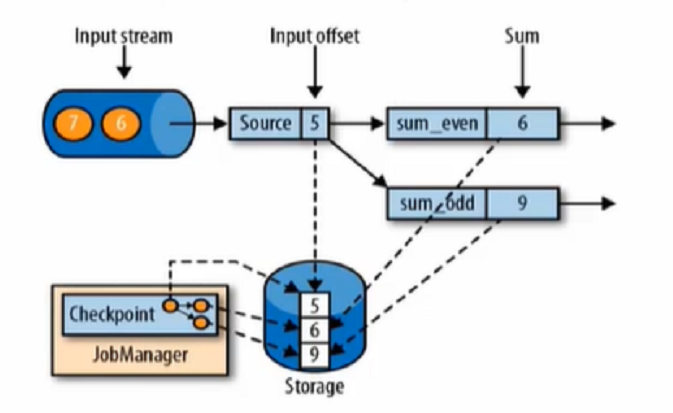
Flink故障恢复机制的核心,就是应用状态的一致性检查点。有状态流应用的一致性检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(可以理解为一份快照),这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候。
从检查点恢复状态
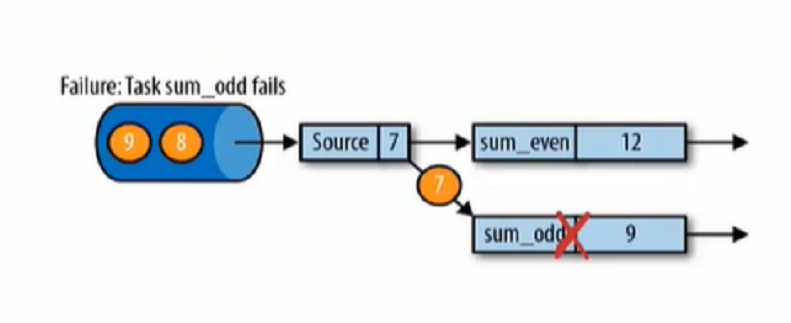
1、 在执行流应用程序期间,Flink会定期保存状态的一致性检查点。如果发生故障,Flink将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程。
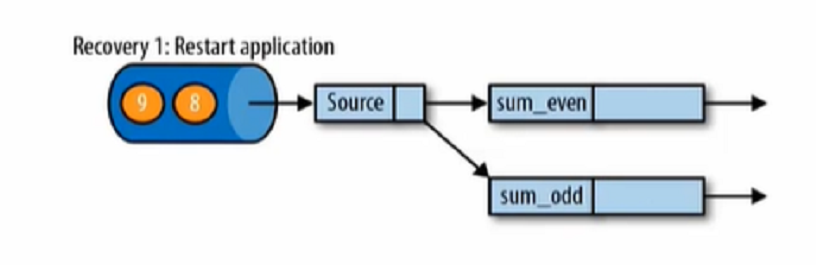
2、遇到故障之后,第一步就是重启应用,这里在代码中可以设置重启策略。
//设置重启策略 fixedDelayRestart(尝试的次数,两次尝试之间的延迟ms ) env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,500)) //失败率重启 env.setRestartStrategy(RestartStrategies.failureRateRestart(3,org.apache.flink.api.common.time.Time.seconds(300),org.apache.flink.api.common.time.Time.seconds(10)))
3、第二部就是从checkpoint中读取状态,将状态重置,从检查点重新启动应用程序之后,其内部状态与检查点完成时的状态完全相同。

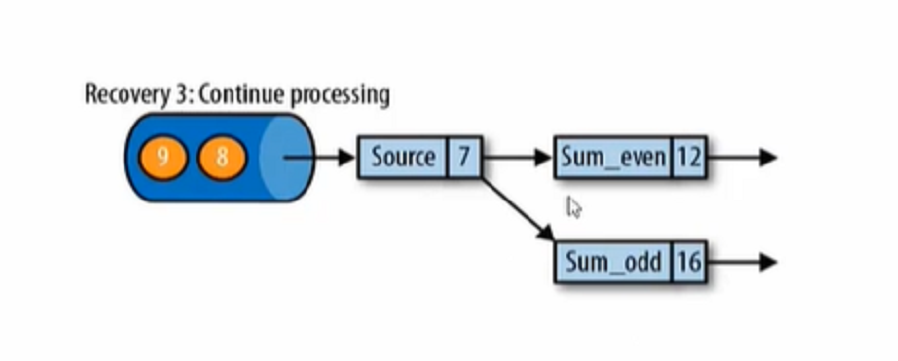
4、第三步,开始消费并处理检查点到发生故障之间的所有数据。这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”(Exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态。这样一来,所有的输入流就都会被重置到检查点完成时的位置。
检查点的实现算法
1、一种简单的想法:暂停应用,保存状态到检查点,在重新恢复应用
2、Flink的改进实现:基于Chandy-Lamport算法的分布式快照,将检查点的保存和数据处理分离开,不暂停整个应用。
检查点分界线(Checkpoint Barrier):Flink的检查点算法用到了一种称为分界线(barrier)的特殊数据形式,用来把一条流上的数据按照不同的检查点分开。分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有更改,就会包含在之后的检查点中。
算法流程:
1、
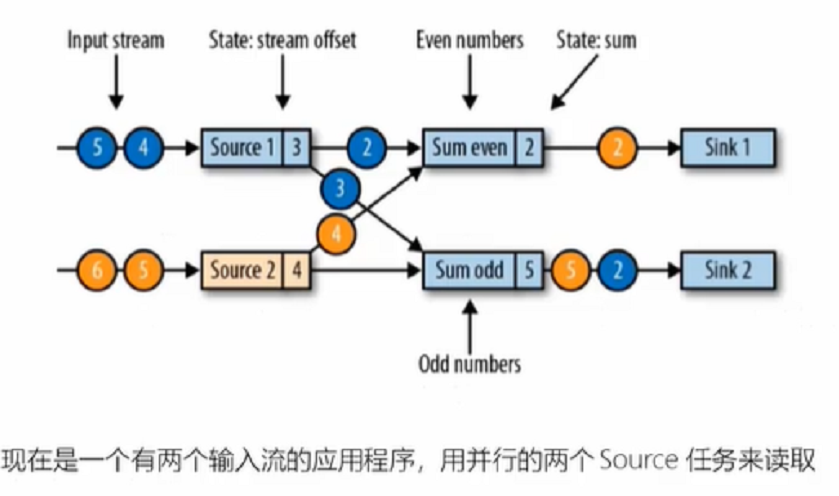
2、
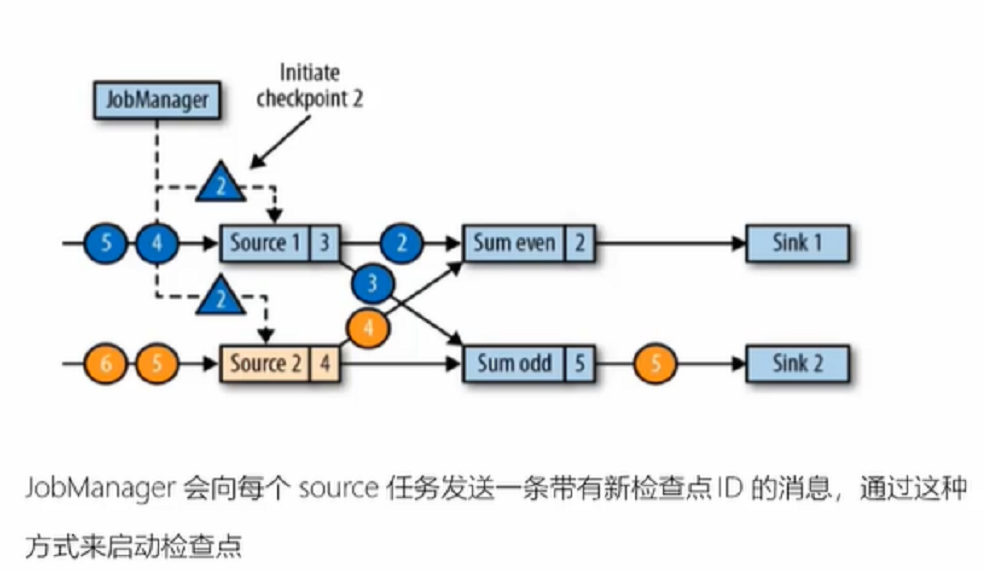
3、
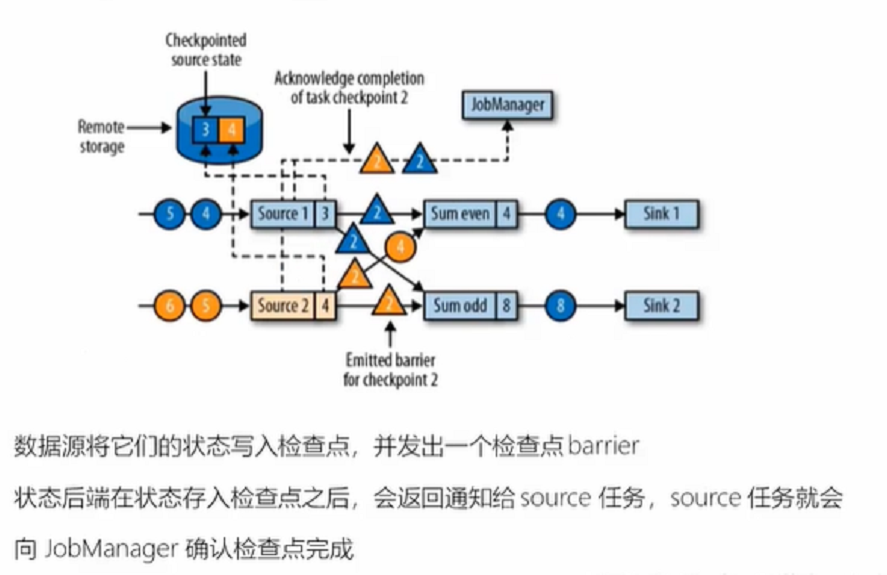
4、
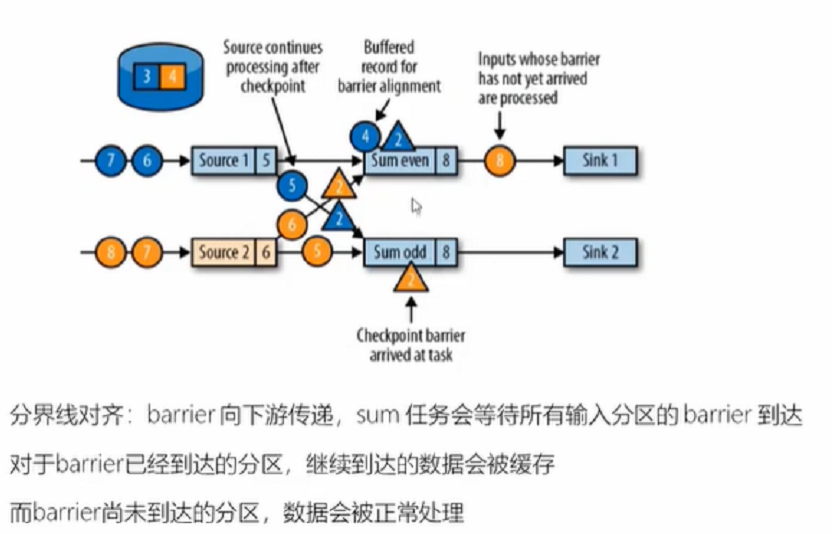
5、
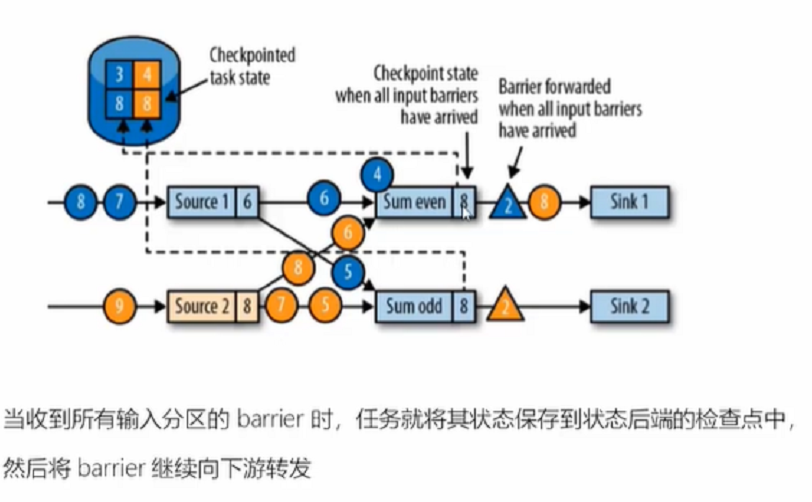
6、
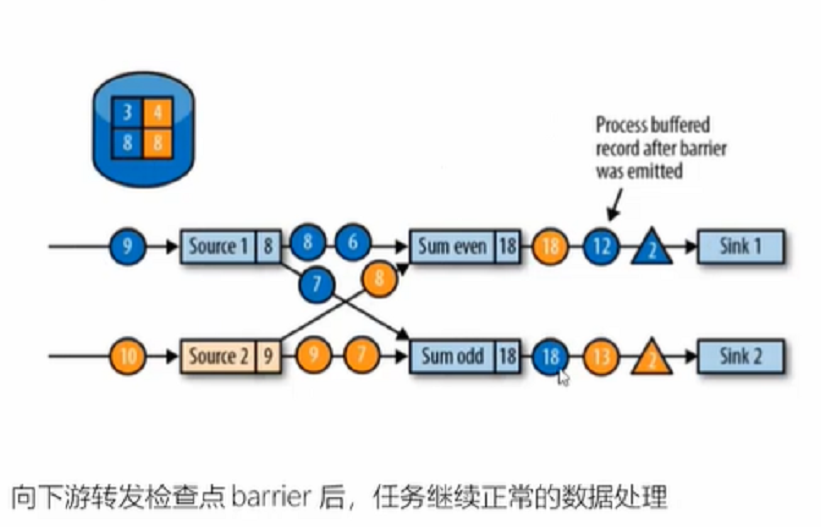
7、
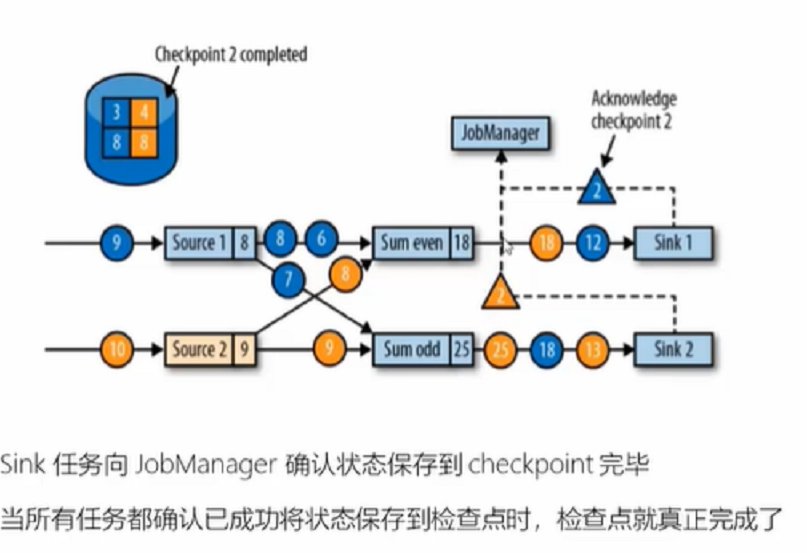
代码中设置体现:
val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //开启checkpoint 传入参数代表每隔多久进行checkpoint env.enableCheckpointing(60000) env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE) env.getCheckpointConfig.setCheckpointTimeout(100000) //checkpoint失败的时候,是否将整个job给消灭掉 默认是true 是消灭了 env.getCheckpointConfig.setFailOnCheckpointingErrors(false) //当前最大同时进行checkpoint的数量 (可能间隔太小 处理时间又长)默认是1 env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) //两个checkpoint的最小时间间隔 env.getCheckpointConfig.setMinPauseBetweenCheckpoints(100) //开启checkpoint外部持久化 本身checkpoint如果job失败了,外部的checkpoint是会被清理的 //开启后,即使是job任务失败了,必须手动的清理才会清掉 //DELETE_ON_CANCELLATION 手动取消就没了 //RETAIN_ON_CANCELLATION 即使手动了 也要留着 env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号