Flink学习(七) 多流转换算子 拆分合并流
一、Split 和 Select (使用split切分过的流是不能被二次切分的)
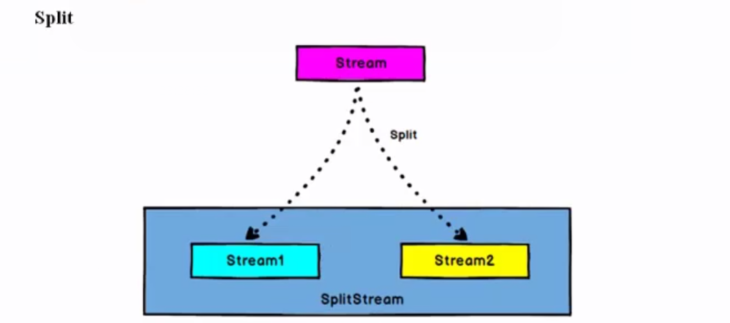
DataStream --> SplitStream : 根据特征把一个DataSteam 拆分成两个或者多个DataStream.
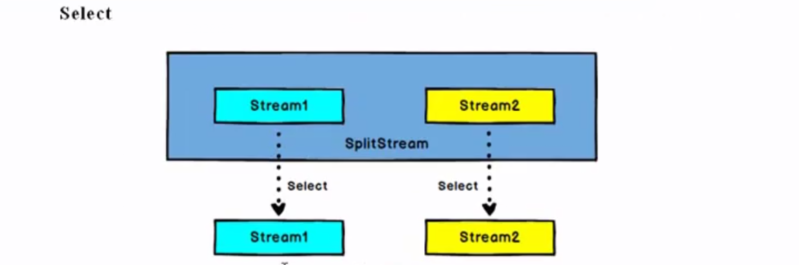
SplitStream --> DataStream:从一个SplitStream中获取一个或者多个DataStream。
二、Connect 和 CoMap / CoFlatMap
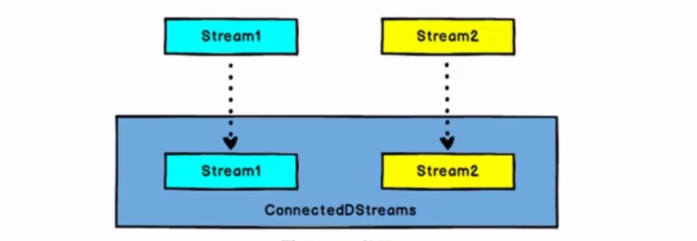
DataStream,DataStream --> ConnectedStream:连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了一个同一个流中,内部依然保持着各自的数据和形式,不发生变化,两个流相互独立。
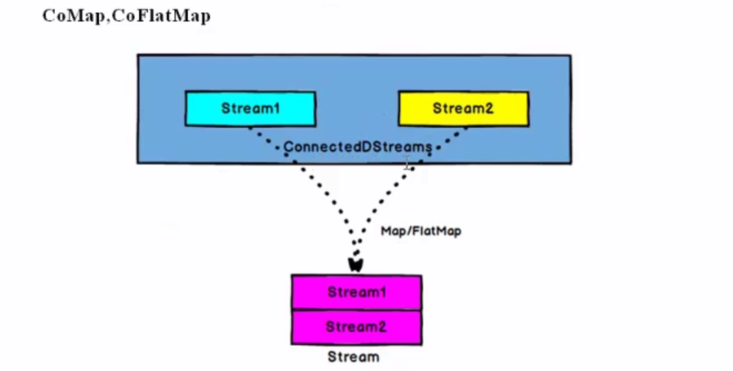
ConnectedStream --> DataStream:作用与 ConnectedStream上,功能与map和Flatmap一样,对 ConnectedStream中的每一个Stream分别进行map和flatmap处理。
三、Union
DataStream --> DataStream:对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream
注意:Connect 与 Union区别:
1、Union之前两个流的类型必须是一样的,Conect可以不一样,并且Connect之后进行coMap中调整为一样的。
2、Connect只能操作两个流,Union可以操作多个。
综合代码:(可直接运行,数据在注释中)
package com.wyh.streamingApi.Transform import org.apache.flink.api.common.functions.ReduceFunction import org.apache.flink.streaming.api.scala._ //温度传感器读数样例类 case class SensorReading(id: String, timestamp: Long, temperature: Double) object TransformTest { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) /** * sensor_1,1547718199,35.80018327300259 * sensor_6,1547718201,15.402984393403084 * sensor_7,1547718202,6.720945201171228 * sensor_10,1547718205,38.1010676048934444 * sensor_1,1547718199,35.1 * sensor_1,1547718199,31.0 * sensor_1,1547718199,39 */ val streamFromFile = env.readTextFile("F:\\flink-study\\wyhFlinkSD\\data\\sensor.txt") //基本转换算子和滚动聚合算子======================================================================================= /** * map keyBy sum */ val dataStream: DataStream[SensorReading] = streamFromFile.map(data => { val dataArray = data.split(",") SensorReading(dataArray(0).trim, dataArray(1).trim.toLong, dataArray(2).trim.toDouble) }) // dataStream.keyBy(0).sum(2).printToErr("keyBy test") //scala强类型语言 只有_.id 可以指定返回类型 val aggStream: KeyedStream[SensorReading, String] = dataStream.keyBy(_.id) val stream1: DataStream[SensorReading] = aggStream.sum("temperature") // stream1.printToErr("scala强类型语言") /** * reduce * * 输出当前传感器最新的温度要加10,时间戳是上一次数据的时间加1 */ aggStream.reduce(new ReduceFunction[SensorReading] { override def reduce(t: SensorReading, t1: SensorReading): SensorReading = { SensorReading(t.id, t.timestamp + 1, t1.temperature + 10) } }) //.printToErr("reduce test") //多流转换算子==================================================================================================== /** * 分流 * split select * DataStream --> SplitStream --> DataStream * * 需求:传感器数据按照温度高低(以30度为界),拆分成两个流 */ val splitStream = dataStream.split(data => { //盖上戳 后面进行分拣 if (data.temperature > 30) { Seq("high") } else if (data.temperature < 10) { Seq("low") } else { Seq("health") } }) //根据戳进行分拣 val highStream = splitStream.select("high") val lowStream = splitStream.select("low") val healthStream = splitStream.select("health") //可以传多个参数,一起分拣出来 val allStream = splitStream.select("high", "low") // highStream.printToErr("high") // lowStream.printToErr("low") // allStream.printToErr("all") // healthStream.printToErr("healthStream") /** * 合并 注意: Connect 只能进行两条流进行合并,但是比较灵活,不同流的数据结构可以不一样 * Connect CoMap/CoFlatMap * * DataStream --> ConnectedStream --> DataStream */ val warningStream = highStream.map(data => (data.id, data.temperature)) val connectedStream = warningStream.connect(lowStream) val coMapDataStream = connectedStream.map( warningData => (warningData._1, warningData._2, "温度过高报警!!"), lowData => (lowData.id, lowData.temperature, "温度过低报警===") ) // coMapDataStream.printToErr("合并流") /** * 合并多条流 注意: 要求数据结构必须要一致,一样 * * Union DataStream --> DataSteam 就没有一个中间转换操作了 * */ val highS = highStream.map(h => (h.id, h.timestamp, h.temperature, "温度过高报警!!")) val lowS = lowStream.map(l => (l.id, l.timestamp, l.temperature, "温度过低报警===")) val healthS = healthStream.map(l => (l.id, l.timestamp, l.temperature, "健康")) val unionStream = highS.union(lowS).union(healthS) unionStream.printToErr("union合并") env.execute("transform test") } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号