SparkRDD算子(transformations算子和actions算子)
RDD提供了两种类型的操作:transformation和action
1、所有的transformation都是采用的懒策略,如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。
2、action操作:action是得到一个值,或者一个结果(直接将RDD cache到内存中)
transformations算子
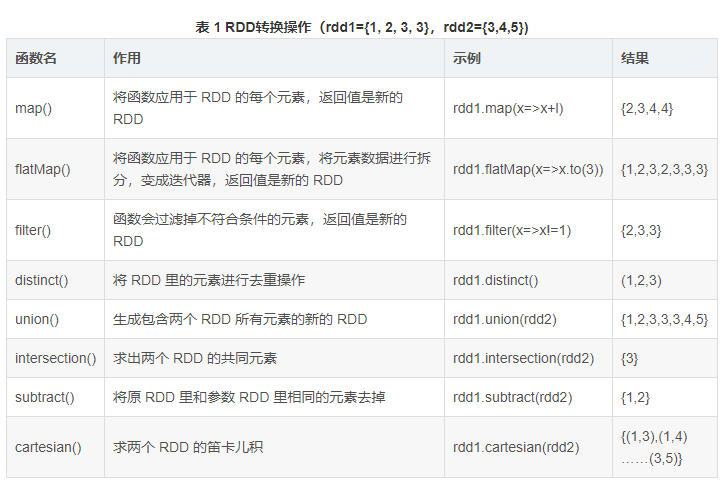
actions算子

transformations算子
1、map算子
var listRDD = sc.makeRDD(1 to 10) listRDD.map((_*2)).foreach(println)
// 输出结果: 2,4,6,8,10,12,14,16,18,20 (这里为了节省篇幅去掉了换行,后文亦同)
2、flatMap算子
flatMap(func)与map类似,但每一个输入的 item 会被映射成 0 个或多个输出的 items( *func* 返回类型需要为Seq`)
val list = List(List(1, 2), List(3), List(), List(4, 5)) sc.parallelize(list).flatMap(_.toList).map(_ * 10).foreach(println)
// 输出结果: 10,20,30,40,50(这里为了节省篇幅去掉了换行,后文亦同)
flatmap 流的扁平化,最终输出的数据类型为一维数组Array[String]。
被分割出来的每个数据都作为同一个数组中的相同类型的元素,最终全部被分割出来的数据都存储于同一个一维数组中。
结论:多行数据被分割后都存储到同一个一维数组Array[String]中。
flatMap 这个算子在日志分析中使用概率非常高,这里进行一下演示:拆分输入的每行数据为单个单词,并赋值为 1,代表出现一次,之后按照单词分组并统计其出现总次数,代码如下:
var list = List("hello scala","hello python")
sc.parallelize(list).flatMap(line=>line.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
// 输出结果:(scala,1)(python,1)(hello,2)(这里为了节省篇幅去掉了换行,后文亦同)
3、filter算子
var listRDD = sc.makeRDD(1 to 10) listRDD .filter(_%2==0).foreach(println)
// 输出结果: 2,4,6,8,10
4、sample(withReplacement, fraction, seed)算子
以指定的随机种子随机抽样出数量为fraction的数据,fraction表示抽取的数据占总数据的比例,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,seed用于指定随机数生成器种子(步长)。
val rdd: RDD[String] = sc.makeRDD(Array("hello1","hello1","hello2","hello3","hello4","hello5","hello6","hello1","hello1","hello2","hello3"))
val sampleRDD: RDD[String] = rdd.sample(false,0.7)
sampleRDD.foreach(println)
//输出结果hello1 hello6 hello1 hello2 hello3 hello5 hello1 hello3
5、union(otherDataset)算子
对源RDD和参数RDD求并集后返回一个新的RDD
val rdd1 = sc.parallelize(1 to 5) val rdd2 = sc.parallelize(5 to 10) val rdd3 = rdd1.union(rdd2) rdd3.collect().foreach(println)
//输出结果1 2 3 4 5 5 6 7 8 9 10
6、intersection(otherDataset)算子
对源RDD和参数RDD求交集后返回一个新的RDD
val rdd6 = sc.parallelize(1 to 7) val rdd7 = sc.parallelize(5 to 10) val rdd8 = rdd6.intersection(rdd7) rdd8.collect().foreach(println)
//输出结果5 6 7
7、distinct([numPartitions]))算子
对源RDD进行去重后返回一个新的RDD。默认情况下,只有8个并行任务来操作,但是可以传入一个可选的numTasks参数改变它
val makeRDD: RDD[Int] = sc.makeRDD(Array(1,3,2,5,6,3,2,1)) val makedist: RDD[Int] = makeRDD.distinct() //不指定并行度 /**对RDD(指定并行度为2) makeRDD.distinct(2)*/ makedist.collect().foreach(println)
//输出结果1 2 3 5 6
8、groupByKey([numPartitions])算子
groupByKey也是对每个key进行操作,但只生成一个sequence。
val words = Array("one","two","three","one","two","three")
val listRdd: RDD[(String, Int)] = sc.makeRDD(words).map(word => (word,1))
listRdd.collect().foreach(println)
//groupByKey算子
val group: RDD[(String, Iterable[Int])] = listRdd.groupByKey()
group.collect().foreach(println)
//输出结果(two,CompactBuffer(1, 1)) (one,CompactBuffer(1, 1)) (three,CompactBuffer(1, 1))
9、reduceByKey(func, [numPartitions])算子
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。分组和聚合一起干了
val words = Array("one","two","three","one","two","three")
val listRdd: RDD[(String, Int)] = sc.makeRDD(words).map(word => (word,1))
val reduceByKeyRDD: Array[(String, Int)] = listRdd.reduceByKey(_+_).collect()
//输出结果(two,2) (one,2) (three,2)
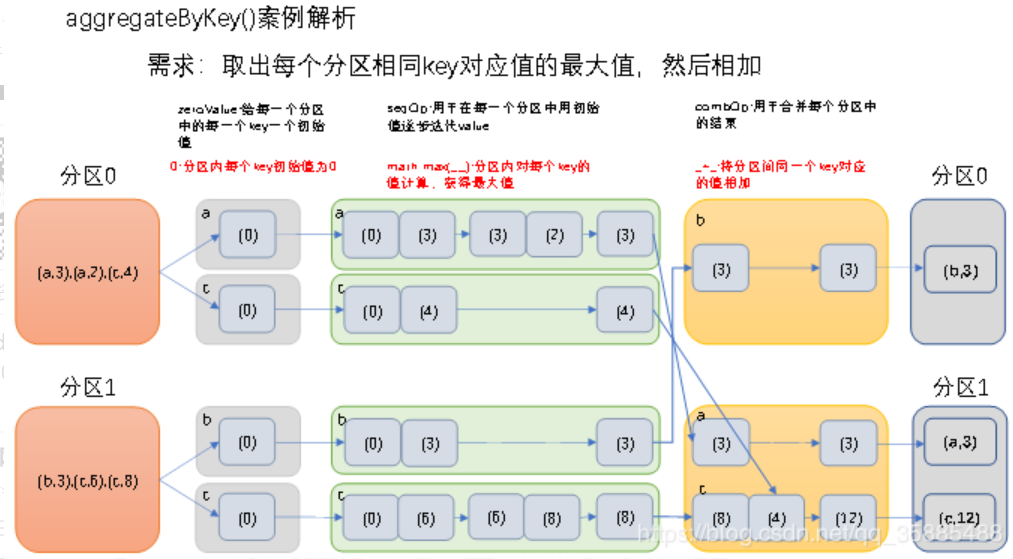
10、aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions])算子
参数描述:
(1)zeroValue:给每一个分区中的每一个key一个初始值;
(2)seqOp:函数用于在每一个分区中用初始值逐步迭代value;
(3)combOp:函数用于合并每个分区中的结果
在kv对的RDD中,,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。
val rdd = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8)),2)
val aggregateByKeyRDD: RDD[(String, Int)] = rdd.aggregateByKey(0)(math.max(_,_),_+_)
aggregateByKeyRDD.collect().foreach(println)
//输出结果(b,3), (a,3), (c,12)
11、sortByKey([ascending], [numPartitions])
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd"))) //根据key正序排 rdd.sortByKey(true).collect().foreach(println) //倒序排序 rdd.sortByKey(false).collect().foreach(println)
//输出结果(1,dd)(2,bb)(3,aa)(6,cc) 和 (6,cc) (3,aa) (2,bb) (1,dd)
12、join(otherDataset, [numPartitions])
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD,等价于内连接操作。如果想要执行外连接,可以使用 leftOuterJoin, rightOuterJoin 和 fullOuterJoin 等算子。
val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd"))) val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6))) rdd.join(rdd1).collect().foreach(println)
//输出结果(1,(dd,4)) (2,(bb,5)) (3,(aa,6))
Actions算子
1、reduce(func)算子
val list = List(1, 2, 3, 4, 5) sc.parallelize(list).reduce((x, y) => x + y) sc.parallelize(list).reduce(_ + _)
// 输出结果 15
2、collect()算子
在驱动程序中,以数组的形式返回数据集的所有元素。
val rdd = sc.parallelize(1 to 10)
println(rdd.collect.mkString(","))
//输出结果 1,2,3,4,5,6,7,8,9,10
3、count()算子
计算RDD中元素的个数
val rdd = sc.parallelize(1 to 10) println(rdd.count)
//输出结果 10
4、first()算子
返回RDD中第一个元素
val rdd = sc.parallelize(1 to 10) println(rdd.first)
//输出结果 1
5、take()算子
返回一个由RDD的前n个元素组成的数组
val rdd = sc.parallelize(Array(2,5,4,6,8,3))
println(rdd.take(3).mkString(","))
//输出结果 2 5 4
6、takeOrdered(n)算子
返回该RDD排序后的前n个元素组成的数组(会按照升序进行自动排序)
val makeRDD: RDD[Int] = sc.makeRDD(Array(2,5,4,6,3,8)) val ordered: Array[Int] = makeRDD.takeOrdered(3) ordered.foreach(println)
//输出结果 2 3 4
7、saveAsTextFile算子
将 dataset 中的元素以文本文件的形式写入本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中。Spark 将对每个元素调用 toString 方法,将元素转换为文本文件中的一行记录。
val list = List(("hadoop", 10), ("hadoop", 10), ("storm", 3), ("storm", 3), ("azkaban", 1))
sc.parallelize(list).saveAsTextFile("/usr/file/temp")
8、countByKey()算子
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。
val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3) println(rdd.countByKey)
//输出结果 Map(3 -> 2, 1 -> 3, 2 -> 1)
9、foreach(func)算子
var rdd = sc.makeRDD(1 to 5,2) rdd.foreach(println(_))
rdd.foreach(println)
//输出结果 1 2 3 4 5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号