

Python爬虫学习01(使用requests爬取网页数据)
Python爬虫学习01(使用requests爬取网页数据)
1.1,使用的库:
import requests
from bs4 import BeautifulSoup
1.2,流程
#1,获取网页的对象
res = requests.get(baseurl,params=params,headers=headers)
#params即为参数,数据类型为字典
#2,编码
res.encoding='utf-8'
#3,将res.text交给BeautifulSoup解析
soup = BeautifulSoup(rs.text,'lxml')
#后一个参数即为使用的解析器
#4,使用soup寻找元素进行操作
1.3,用到的函数
1,bs4.element.Tag.get('标签类型',attr={'属性的种类':'属性的值'})
返回类型:bs4.element.Tag
示例:city.find('div')
2,1,bs4.element.Tag.get_all('标签类型',attr={'属性的种类':'属性的值'})
返回类型:list
示例:cities = table.find_all('tr')
1.4,示例:爬取百度百科中的湖北省行政区划
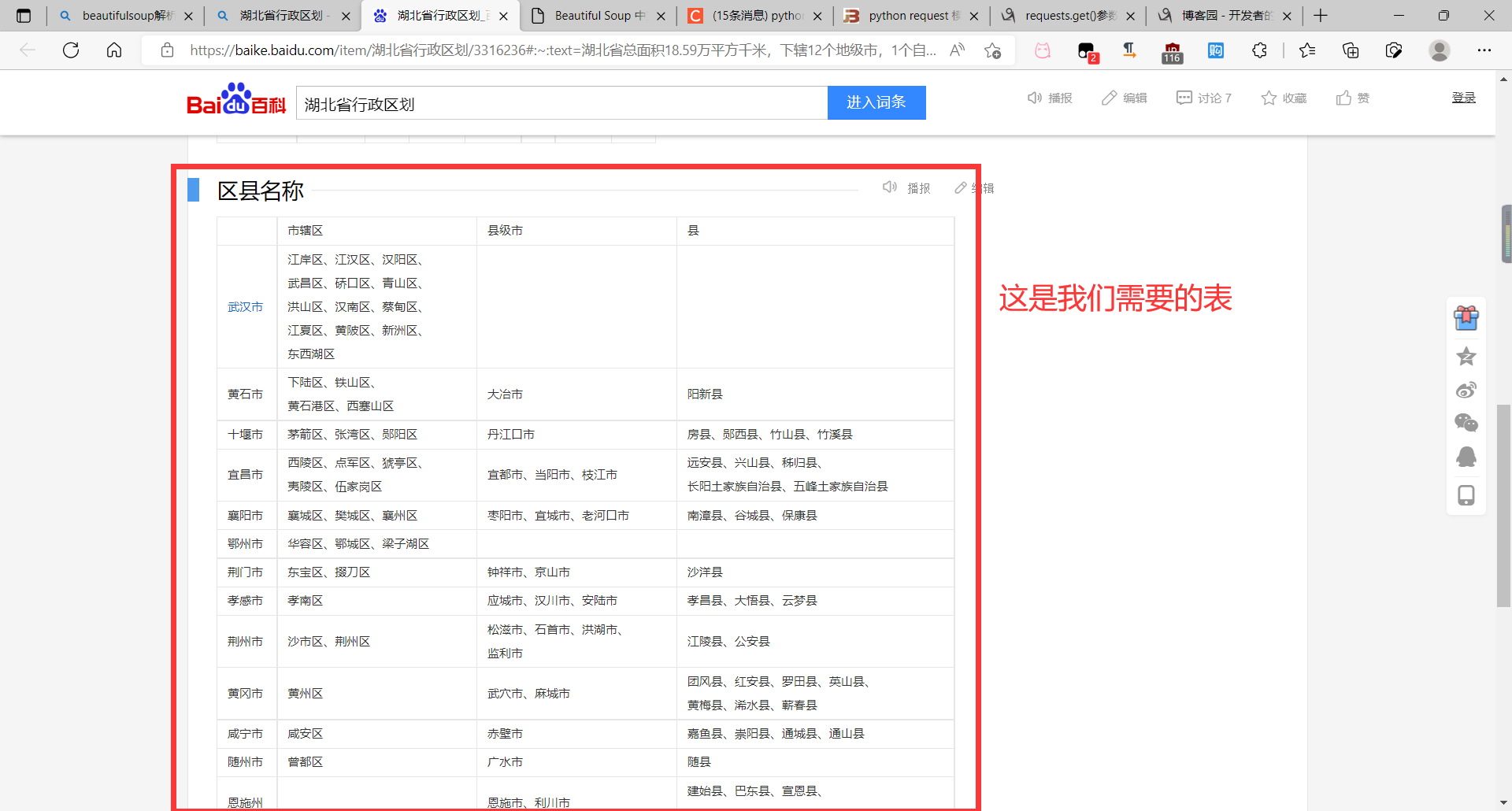


#导入两个库
import requests
from bs4 import BeautifulSoup
#请求头,防止网站识别爬虫
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53'
}
#地址
url = 'https://baike.baidu.com/item/湖北省行政区划'
rs = requests.get(url=url,headers=headers)
rs.encoding='utf-8'
#使用BeautifulSoup解析数据
soup = BeautifulSoup(rs.text,'lxml')
#找到百度中行政区划的表
table = soup.find_all('table')[1]
#找到表中的各项
cities = table.find_all('tr')
#循环处理
for city in cities[1:]:
#找到市级单位
city_level = city.find('div').text
#找到区级单位
counties_level = city.find_all('div')[1:]
counties = []
#将爬取的字符串进行处理
for item in counties_level:
counties.append(item.text.split('、'))
counties.append(['市区'])
for county in counties:
for item in county:
if item != '':
print('湖北省', city_level, item)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通