shell脚本原理与应用
一、shell脚本原理与应用
编程语言的类型
一般可以把编程语言分为两类,分别是编译型语言和解释型语言,两种语言的区别如下所示:
(1) 编译型语言着重于高效性,编译型语言使用平台相关的编译器将源码翻译为平台相关的程序,因此缺点是难以跨平台。编译型语言代码通常较为复杂,开发者需要编写绝大部分的逻辑,编译型语言对硬件更具掌控力,也更容易导致安全漏洞。
(2) 解释型语言着重于易用性,解释型语言使用解释器直接执行平台无关的语句,因此优点是可以跨平台,由于解释型语言高度汇聚了程序逻辑模块,因此同时保证了安全性和易用性。由于解释器充当了运行时优化、跨平台运行中间件等角色,因此解释型语言程序要比编译型消耗更多的系统资源,程序性能上也慢很多。
脚本解释器种类
脚本语言例如Python、JS、Shell等,它们都是不需要编译的解释性编程语言,一般脚本语言都需要解释器,解释器的种类有很多,常见的脚本解释器有:bash、dash、csh、sh 等。
一般Linux系统下支持很多解释器,用户可以通过查看 /etc/shells 文件了解当前系统支持的解释器类型,如下:

思考:既然系统支持这么多种解释器,那系统会全部使用吗?如果不是,请问系统使用哪个?
回答:上面只是系统可以支持的解释器类型,当前Linux系统只是会使用其中一款,用户可以调用 echo $SHELL来查看当前系统使用的解释器,如下:

可以看到,当前Linux系统使用的解释器是bash,bash通常运行于文本窗口中,并能执行用户直接输入的命令。bash还能从文件中读取命令,这样的文件称为脚本。
当linux系统启动之后,用户需要打开一个命令输入窗口(Ctrl+Alt+T),其实就是打开一个解释器,解释器在linux系统默认是bash解释器,bash解释器就是一个应用程序,当程序运行之后,会变为进程。
bash解释器程序内部实现机制:一个死循环,程序可以从标准输入(stdin)或者从指定文件中读取数据,如果数据是可以被bash进行解释,则一般情况下bash解释器会把解释的结果输出到标准输出(stdout),也可以选择把结果输出到指定文本中。
bash解释器是可以解释linux系统内核提供的shell命令的,所以在xxxx.sh脚本中应该写需要执行的相关的shell命令。
脚本的固定格式
一般而言,Linux系统下脚本文件的拓展名是xxx*.sh*,用户可以通过命令(touch、vi)创建一个空白的脚本文件。
创建好一个空白的脚本文件后,需要在脚本文件的第一行使用#!来指定shell解释器,如下:

#!是告诉操作系统需要指定一个shell解释器来解释该脚本,在#!后面指定shell解释器的路径,比如 #!/bin/bash或者 #!/bin/sh等,*当然,这句话也可以不写,如果不写则使用Linux系统的默认解释器,也就是bash解释器。*
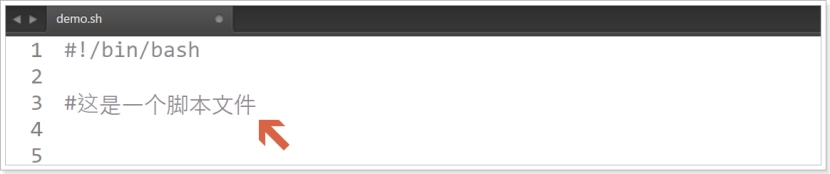
脚本的注释格式
一般用户在编写shell脚本时会添加必要的脚本注释,但是和C语言不同,shell脚本语言的注释使用#号实现,如下:
脚本的输入输出
对于脚本而言也是支持输入与输出的,输入指的是可以获取键盘输入的字符,输出指的是可以把脚本内容输出到终端。
(1) 输入实现
shell脚本支持通过read命令从标准输入中获取一行数据,按下回车表示输入结束,如下图:

注意:如果想要把输入的内容保存到变量中,则可以直接指定变量名称,不需要提前定义变量,一行结束也不需要添加分号,如下:

(2) 输出实现
shell脚本支持通过echo命令向标准输出中输出数据内容,echo命令后面跟着输出内容即可。

提示:如果想通过echo命令输出某个变量的内容,则需要通过$符号来获取变量对应的值!
shell脚本的变量
shell 脚本是一种弱类型程序语言,相比于 C/C++ 那样的强类型语言,脚本定义变量时无需指定数据类型,默认是字符串,定义时直接写出变量名即可,*注意:赋值=两边不要空格!!!*
变量定义
data=”hello” 或者 data=hello // 赋值=的左值是变量名,赋值=的右值是变量值,别空格!
data=”hello i am a student” //如果变量值是由多个字符串组成,则双引号不要省略!!!
注意:如果要引用的变量的值是较长的字符串,则echo命令应该使用{ }来修饰该变量,如:
data=”hello i am a student” //如果变量值是由多个字符串组成,则双引号不要省略!!!
echo ${data} //可以把变量data的内容输出到标准输出上
shell脚本通配符

通配符就是一种特殊的字符,这种特殊字符可以在某些特定场合匹配其他的字符,注意:不是所有的shell命令都支持通配符。
shell脚本的管道
管道是 Shell 脚本中非常重要的机制,用来在两个命令中架起一座桥梁,使得一个命令的执行结果可以传导给下一个命令,这样一来就可以将多个小巧的命令组装成复杂的功能模块。
管道实际上有两种不同的执行模式,分别是cmd1 | cmd2以及cmd1 |xargs cmd2,如下所示:
(1) cmd1 | cmd2
指的是将 cmd1 的输出作为 cmd2 的输入 比如:find ~/ -name hello.c | grep “world”
(2) cmd1 |xargs cmd2
指的是将 cmd1 的输出作为 cmd2 的参数如find ~/ -name hello.c |xargs grep “world”

shell脚本重定向

重定向指的是一种在shell脚本中常用的技术,重定向允许将命令的输入或输出从默认的标准位置重定向到其他位置。
<指的是把标准输入进行重定向,>指的是把标准输出进行重定向(会覆盖文件内容),>>指的是把标准输出进行重定向(会追加到文件末尾)。
shell脚本反引号

在shell脚本中有一个特殊符号经常使用,就是反引号 ,放在反引号的命令会被解释器执行,反引号可以在双引号””中进行嵌套使用。


注意:反引号也是可以在双引号中进行嵌套的,双引号表示字符串,可以在字符串中引用shell命令。
shell脚本数值运算
由于脚本的变量类型默认都是字符串,需要对变量进行数值运算时则可以采用以下方案,如:
可以使用双括号实现,这种方法既适用于 bash 解释器,也适用于嵌入式板卡的 sh 解释器。
使用格式: data=200 data=$( ($data+20) ) echo $data
二、shell脚本控制语句
shell脚本也支持多种控制语句,shell的控制语句有固定的书写格式,和C语言的格式不同!
分支语句
有时需要在脚本中对某些条件进行判断,根据条件是否成立来选择执行不同的指令,所以shell提供了两种分支语句,分别是:针对两种情况 and 针对多种情况。
(1) 针对两种情况
使用格式:
if [ 表达式 ] //注意:表达式写在[ ]中,并且[ ]中的表达式两边必须有空格!
then
....
....
fi //注意:判断语句结束是以if的逆序书写fi作为结束标志
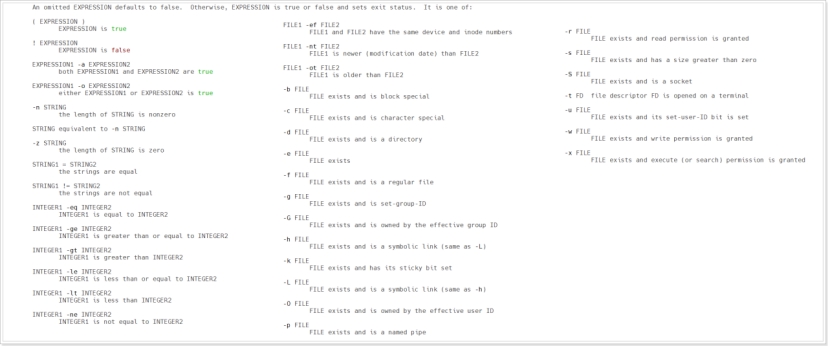
对于[ ] 而言,其实是shell脚本中的test命令的另一种形式,在man手册中有相关描述,如:

可以看到[ ]中是表达式,test命令为表达式的判断提供了很多参数选项,用户可以选择,如:
当然,[ ]中的表达式也可以使用逻辑运算符进行逻辑运算,shell支持逻辑与&&、逻辑或||、逻辑非!,规则和C语言一致。注意:逻辑运算符和表达式中间要有空格。
另外,如果需要对多个表达式进行判定,则可以使用多个if [ ]分支语句级联的方式实现,如:
使用格式
if [ 表达式1 ]
then
...
elif [ 表达式2 ] //注意:第二个表达式需要使用elif[ ]进行指定,其实就是else if缩写
then
...
elif [ 表达式3 ]
then
...
fi //注意:整个分支语句是以if的逆序书写fi作为结束标志,别写错!!!

(2) 针对多种情况
为了提高脚本的可读性,shell也提供多分支选择语句,shell提供的选择语句叫做case语句。
使用格式:
case 测试值 in //测试值指的是要进行比较的变量或者常量,in指的是进入
比较值1)
......
;; //比较值都是字符串,每个比较值的执行语句后面需要跟着两个;;
比较值2)
......
;;
比较值3)
......
;;
*) //注意:*就是表示除了上面比较值之外的所有情况,相当于default
......
esac //注意:case语句的结束使用case的逆序书写esac作为标志

循环语句
shell脚本也提供三种循环语句,分别是for语句、while语句、until语句,使用规则如下:
(1) while语句
使用格式:
while 表达式 // 注意:表达式如果一致成立,则while循环会一直成立
do
......
done
死循环格式:
while true 也可以写成 while[ 1 ]
do
......
done
(2) for语句
使用格式:
for 变量 in 枚举列表
do
......
done
枚举列表实际就是一个变量值,由于脚本中变量的类型默认就是字符串,因此变量值默认是由单词组成的列表。
变量是每次循环时,所枚举字符串中的各个单词,而循环次数取决于枚举列表中的单词个数!
(3) until语句
until 表达式
do
......
done
注意:until 循环的规则是如果条件成立,则立即退出循环。否则一直进行循环,千万注意!
另外,在循环语句中也可以使用break跳出循环,或者使用continue结束一次循环,这两种语句末尾不需要添加分号,如下:
使用格式:
while 表达式
do
if [ 表达式 ]
then
break //遇到break则直接跳出循环,如果是continue则直接开始下次循环
fi
done
三、shell脚本外部传参
脚本启动时可以携带参数,就跟执行普通的命令或程序一样,这些被称为外部参数的数据可以传到脚本内部参与运行。
使用格式:
echo $1 //指的是外部传入的第一个参数 注意:$0指的是脚本文件的名称
注意:对于参数下标大于个位数的外部参数,可用大括号来进行引用,如 ${10}、${11} 等!!

四、shell正则表达式
shell的某些命令是支持正则表达式的,正则表达式(Regular Expression,通常简称RE)指的是使用一些具有特定含义的字符,去组合成具有某种特定规律的字串。然后利用这些特定的字串,去对文本、选项、参数等进行比对、抽取等动作,可以提高开发效率。
正则表达式与通配符类似,但比通配符复杂,正则表达式具有更多且更细致的特殊字符,能表达更复杂的场景。这些具有特殊含义的字符通常被称为元字符,常用元字符如下表所示:

注意:并不是所有的shell命令都支持编写正则表达式,只有少部分较为复杂的命令支持正则表达式,其余命令只支持通配符,通配符中和有部分符号和正则表达式的符号相同,但是含义并不一样。
一般正则表达式都是和shell中的过滤器结合使用,过滤器指的是从文件读取数据,并对这些数据加以筛选、修订,然后输出,过程就像一根水管中间的过滤器,将水处理后再输送到下一环节进行处理,常用的过滤器有grep、awk、sed。

(1) grep过滤器
命令 grep 用于在指定文件或目录中查找某些字符串,这些字符串的匹配模式支持正则表达式。


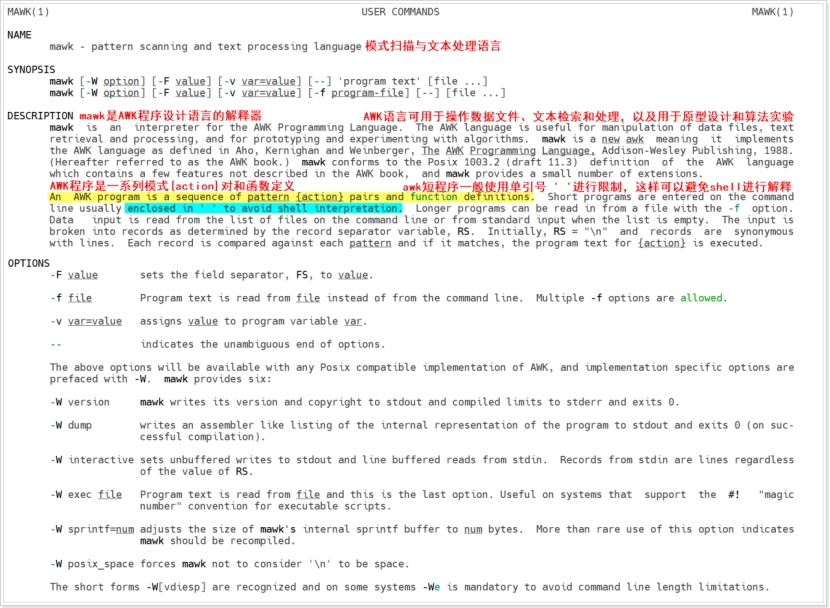
(2) awk过滤器
awk 是一种用于处理文本的编程语言工具,它以行为单位,每次读取文件中的一行,查找与命令行中所给定内容相匹配的模式,如果发现匹配内容,则进行下一个过滤步骤。如果找不到匹配内容,则继续处理下一行。
-
使用格式 awk ' 条件1 {动作1} 条件2 {动作2} …… ' file 1. 从指定的文件file中读取一行内容 2. 针对这一行内容来判断条件1是否成立,如果成立则执行动作1,否则不执行 3. 然后判断条件2是否成立,如果成立则执行动作2,否则不执行 4. 如果这一行内容被处理完,则重复以上1-3步,直到将文件读完为止

注意:可以知道模式和动作是可以省略其中一个,如果 awk 的一个动作前面没有模式,则这个动作默认是匹配,所以就可以无条件执行。提示:模式可以理解为判断条件。
比如,当前一个名称叫做grade.txt的文本中处理使用awk进行查找和分析,使用规则如下:

- 显示指定列
gec@ubuntu:~$ awk '{ print $1, $5 }' grade.txt
注意:$1表示第1列,2表示第2列,n表示第n列,而$0表示整一行(也就是所有列)。
- 格式化输出
gec@ubuntu:~$ awk '{printf "%-10s:%-d\n", $1, $5}' grade.txt
- 过滤
gec@ubuntu:~$ awk '$5==11 && $6>=90 { print $0 }' grade.txt
流程:读取grade.txt的一行信息,判断第五列(即$5)是否等于11而且第6列(即$6)是否大于等于90,如果是,则显示整一行(即print $0)。然后读取下一行。
- 显示表头
gec@ubuntu:~$ awk 'NR==1 || $6>=90 { print }' grade.txt
NR表示已经读出的记录数(即行号),另外print后面什么都没跟,所以等价于print $0

AWK语言提供了一些内建变量,这些内建变量在程序执行前就已经提前建好并被初始化好。
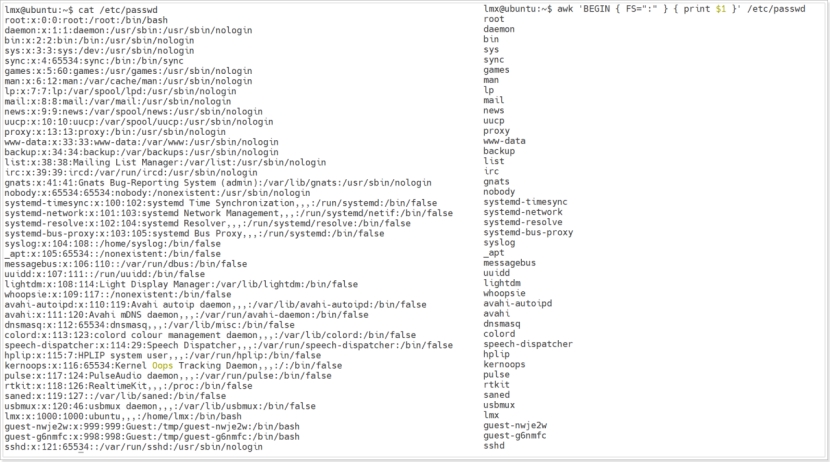
- 指定分隔符
gec@ubuntu:~$ awk 'BEGIN { FS=":" } { print $1 }' /etc/passwd
上面这句话的意思是:把/etc/passwd文件中冒号:之前的那一列进行输出,BEGIN意味着紧跟在它后面的动作 {FS=":"} 会在 awk 读取第一行之前处理。
- 匹配字符串
gec@ubuntu:~$ awk ' $0~/Brown/ {print} ' grade.txt
上面这句话的意思是:将文档中所有匹配Brown的行显示出来。其中$0~/Brown/ 是一个条件,表示所指定的域(这里是$0)要匹配的规则(这里是Brown),也就是grade.txt中的一行只要包含有单词Brown,就会被选出来然后显示出来。
- 信息重定向
gec@ubuntu:~$ awk ' {print > $5} ' grade.txt
上面这句话的意思是:每一行都将被重定向到以第5个域(年龄)命名的文件中去。也可以将指定的域重定位到相应的文件。
(3) sed过滤器
sed指的是stream editor流编辑器,sed 的工作就是把文件或字符串里面的文字经过一系列编辑命令转换为另一种格式输出。跟 awk 过滤器类似,sed也是一次读取文件的一行信息加以处理,然后再读取下一行,以此类推。

- 进行替换
gec@ubuntu:~$ sed "s/-year/ years/" people.txt
意思是从people.txt中读取一行,然后使用正则表达式-year来试图匹配某单词,如果匹配成功,则将之替换成” years”。
- 指定替换
gec@ubuntu:~$ sed "2s/-year/years/" people.txt
意思是将第2行的"-year"改成" years"。 如果想修改其中几行,则可以写成”2,5s/year/years”
- 修改原文
gec@ubuntu:~$ sed -i "2s/-year/years/" people.txt
需要注意:默认情况下sed不会修改原文,默认状态下sed只是对原文的复制品进行了加工。
- 插入信息
gec@ubuntu:~$ sed '3i x' people.txt 在第3行的前面插入x
gec@ubuntu:~$ sed '2a x' people.txt 在第2行的后面插入x
gec@ubuntu:~$ sed '1,4a x' people.txt 分别在第1至4行后插入x
gec@ubuntu:~$ sed '/US/a x' people.txt 在匹配US的行后插入x
- 指定删除
gec@ubuntu:~$ sed '2d' people.txt 将第2行给删掉
gec@ubuntu:~$ sed '/US/d' people.txt 将匹配/US/的所有行删掉
- 匹配显示
gec@ubuntu:~$ sed '/Chen/p' people.txt -n 显示匹配Chen的行
gec@ubuntu:~$ sed '/Chen/, /Lau/p' people.txt -n 显示匹配Chen或者Lau的行
gec@ubuntu:~$ sed '3,/UK/p' people.txt -n 从第3行开始显示直到匹配UK为止
gec@ubuntu:~$ sed '/UK/,6p' people.txt -n 从匹配UK的行开始显示直到第6行为止

 浙公网安备 33010602011771号
浙公网安备 33010602011771号