
1.操作系统监控命令: top ,在 top 命令中,输入数字 1 展示每个核的CPU使用情况
2.进程监控命令: ps
ps -ef 显示所有进程信息,连同命令行
ps -ef|grep ssh ps 与grep 常用组合用法,查找特定进程
ps aux列出目前所有的正在内存当中的程序
3.系统平均负载监控命令: uptime
uptime 显示系统平均负载
uptime 08:21:34 up 36 min, 2 users, load average: 0.00, 0.00, 0.00 #当前服务器时间: 08:21:34 #当前服务器运行时长 36 min #当前用户数 2 users #当前的负载均衡 load average 0.00, 0.00, 0.00,分别取1min,5min,15min的均值
4.内存监控命令: free
free -m 以MB为单位显示系统内存的使用情况,同理,也可以使用-k、-g等其他的单位显示
free 命令从两个维度统计了内存的使用情况
第一行Mem:从操作系统角度统计内存的total、used、free、buffers、cached
第二行-/+buffers:从应用程序角度统计内存的total、used、free、buffers、cached
buffer和cache:两者都是Linux下的缓存机制,其中buffer为写操作的缓存,cache为读操作的缓存
swap:交换空间,磁盘上的一块空间,当系统内存不足时,会使用交换空间

5.磁盘IO监控命令: iostat
命令: iostat -x -k 1
-x:展示磁盘的扩展信息
-k:以k为单位展示磁盘数据
1:每1秒刷新一次
展示结果
rrqm/s :每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合 并Merge);
wrqm/s :每秒这个设备相关的写入请求有多少被Merge了。
rsec/s :每秒读取的扇区数;
wsec/s :每秒写入的扇区数。
rKB/s :The number of read requests that were issued to the device per second;
wKB/s :The number of write requests that were issued to the device per second;
avgrq-sz :平均请求扇区的大小
avgqu-sz :是平均请求队列的长度。毫无疑问,队列长度越短越好。
await :每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。 这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
svctm :表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等 待太长, 系统上运行的应用程序将变慢。
%util :在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。
一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。

6.磁盘空间监控命令: df
df命令可以查看当前系统磁盘空间的使用情况,命令: df -h
磁盘速度测试命令:dd if=/dev/zero of=/export/ddtest bs=8k count=1000000 oflag=direct
7.sar监控命令: sar
sar -n DEV 1 1 查看网络接口信息
sar 1 1 CPU和IOWAIT统计状态
默认监控: sar 1 1 // CPU和IOWAIT统计状态 (1) sar -b 1 1 // IO传送速率 (2) sar -B 1 1 // 页交换速率 (3) sar -c 1 1 // 进程创建的速率 (4) sar -d 1 1 // 块设备的活跃信息 (5) sar -n DEV 1 1 // 网路设备的状态信息 (6) sar -n SOCK 1 1 // SOCK的使用情况 (7) sar -n ALL 1 1 // 所有的网络状态信息 (8) sar -P ALL 1 1 // 每颗CPU的使用状态信息和IOWAIT统计状态 (9) sar -q 1 1 // 队列的长度(等待运行的进程数)和负载的状态 (10) sar -r 1 1 // 内存和swap空间使用情况 (11) sar -R 1 1 // 内存的统计信息(内存页的分配和释放、系统每秒作为BUFFER使用内存页、每秒被cache到的内存页) (12) sar -u 1 1 // CPU的使用情况和IOWAIT信息(同默认监控) (13) sar -v 1 1 // inode, file and other kernel tablesd的状态信息 (14) sar -w 1 1 // 每秒上下文交换的数目 (15) sar -W 1 1 // SWAP交换的统计信息(监控状态同iostat 的si so) (16) sar -x 2906 1 1 // 显示指定进程(2906)的统计信息,信息包括:进程造成的错误、用户级和系统级用户CPU的占用情况、运行在哪颗CPU上 (17) sar -y 1 1 // TTY设备的活动状态 (18) 将输出到文件(-o)和读取记录信息(-f)
8.综合监控工具: vmstat
vmstat命令综合了CPU、进程、内存、磁盘IO等信息
命令: vmstat 2 10 ,每2秒刷新一次,一共打印10次

r :表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,
一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b :表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd :虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free :空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff :Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M。
cache :cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高程序执行的
性能,当程序使用内存时,buffer/cached会很快地被使用。)
si :每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so :每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi :块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上
看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo :块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in :每秒CPU的中断次数,包括时间中断。
cs :每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx
这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是
比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分
浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us :用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy :系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id :空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt :等待IO CPU时间。
9.超级监控工具: dstat
dstat是一个全能监控工具,整合了CPU、内存、磁盘、网络等几乎所有的监控项,支持实时刷新
需安装:yum install -y dstat
监控命令: dstat -tcmnd --disk-util --output sys-10.csv
10.支持数据存储的监控工具: nmon
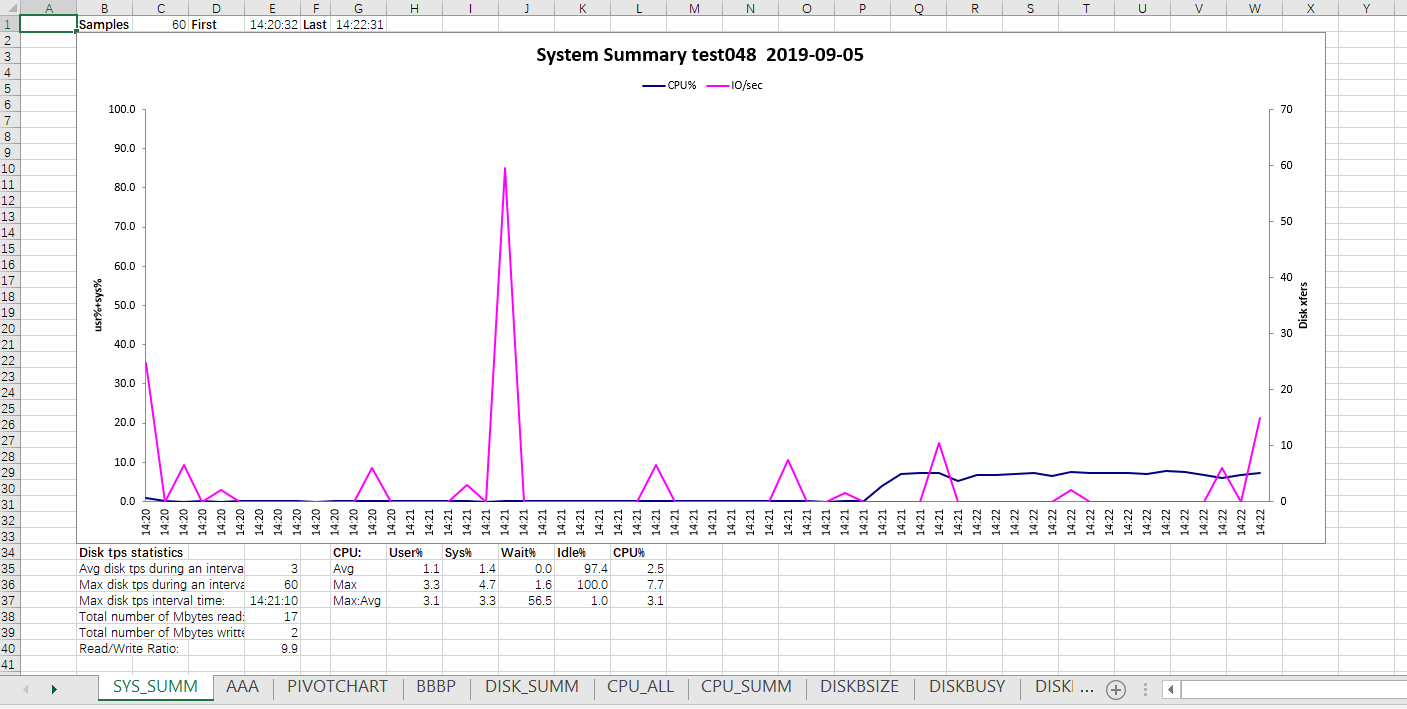
nmon是IBM公司开发的Linux性能监控工具,可以实时展示系统性能情况,也可以将监控数据写入文件中,并使用nmon分析器做数据展示
命令: cd /export/minitor/nmon ./nmon -ft -s 5 -c 1000 sz ****.nmon 使用本地nmon表格分析nmon文件
Nmon文件需要关注的标签页
1、cpu_all
2、diskbusy
3、net
4、mem
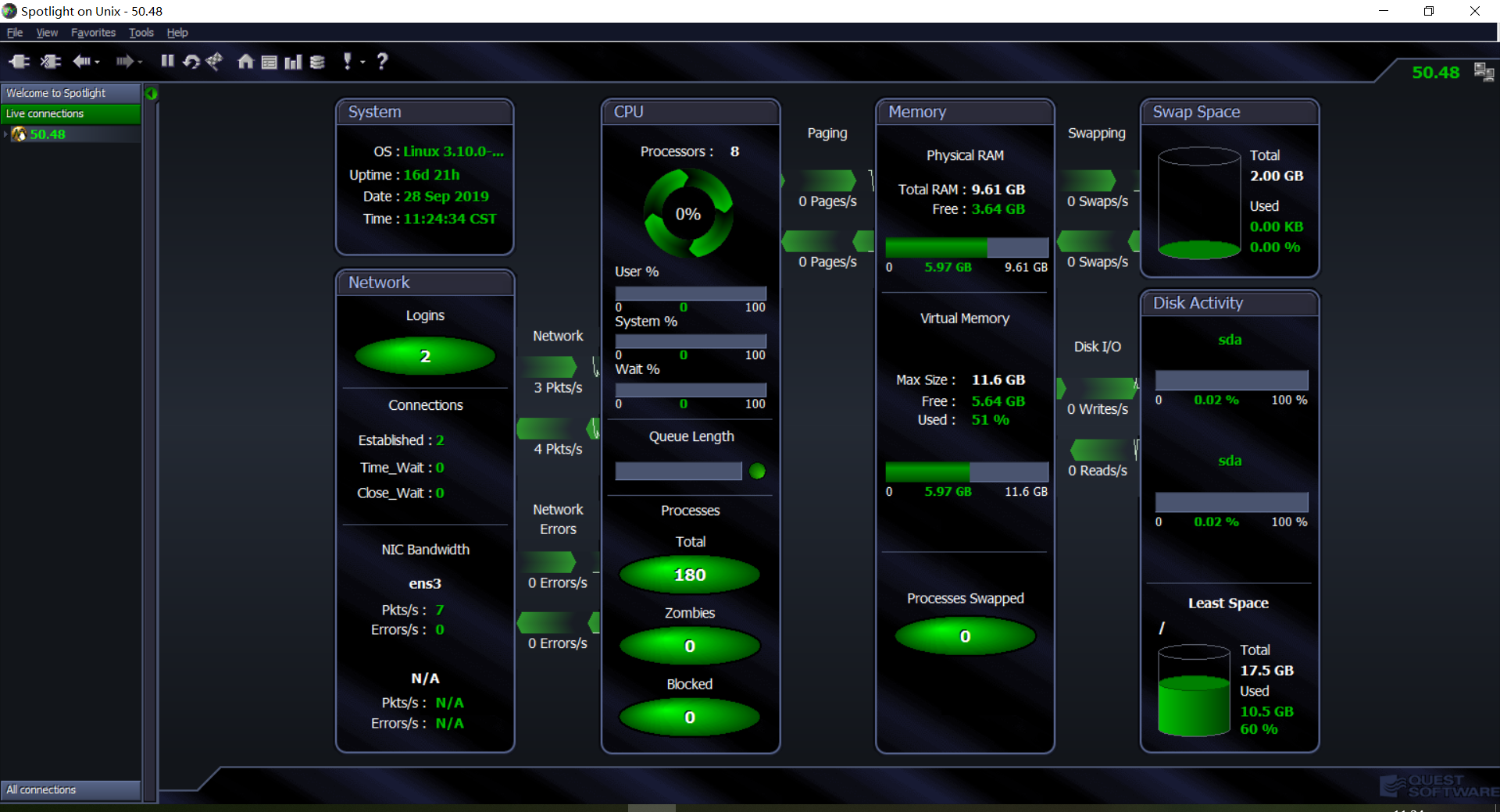
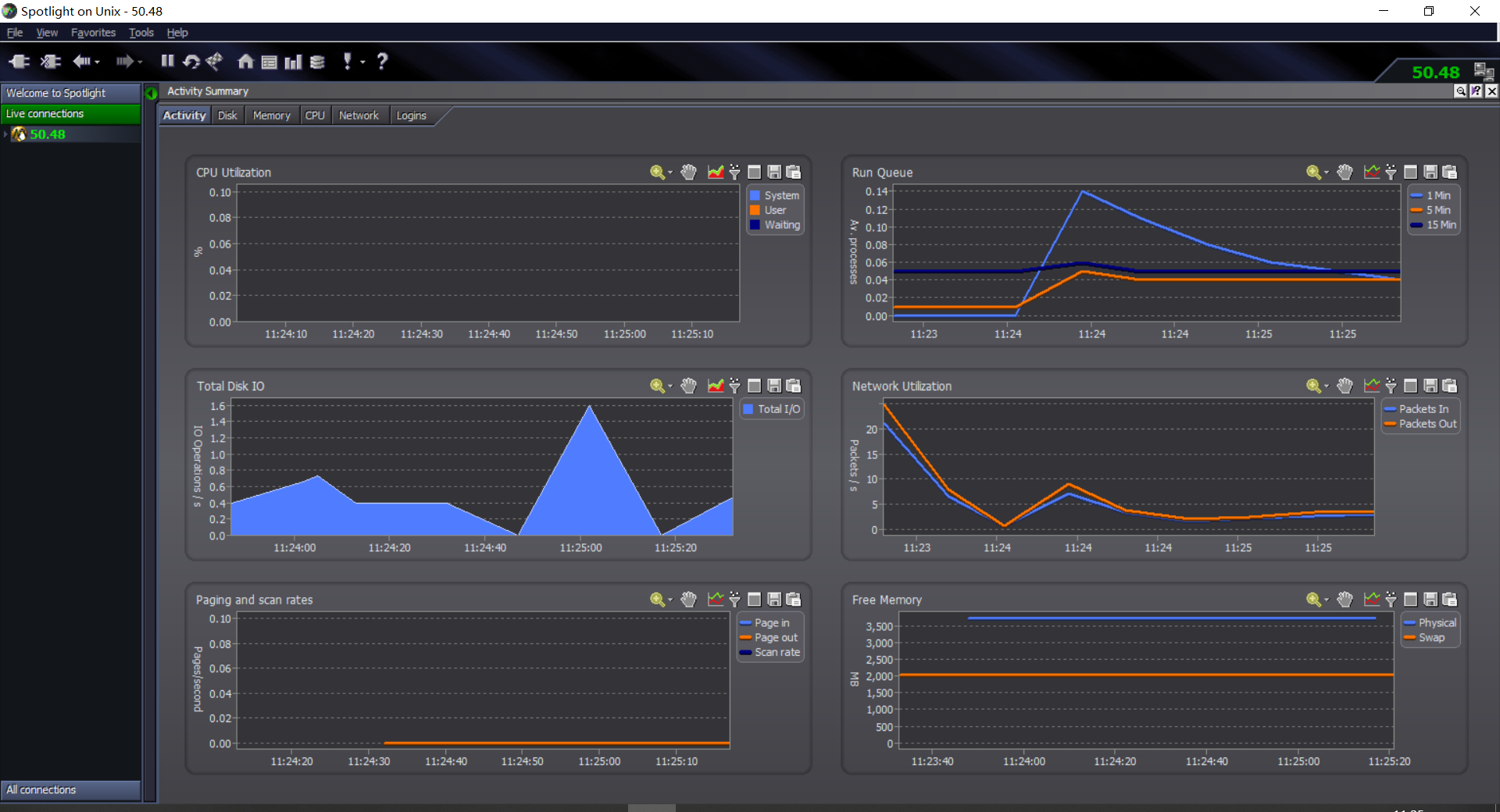
11.实时性能监控工具: spotlight
Spotlight是一个实时展示Linux资源使用的可视化工具
1、安装spotlight(常规安装,略)
2、在被监控的Linux内,新建一个spotlight监控用户useradd xxx,修改密码:passwd xxx
3、在windows下打开spotlight工具,新建监控链接即可开始监控
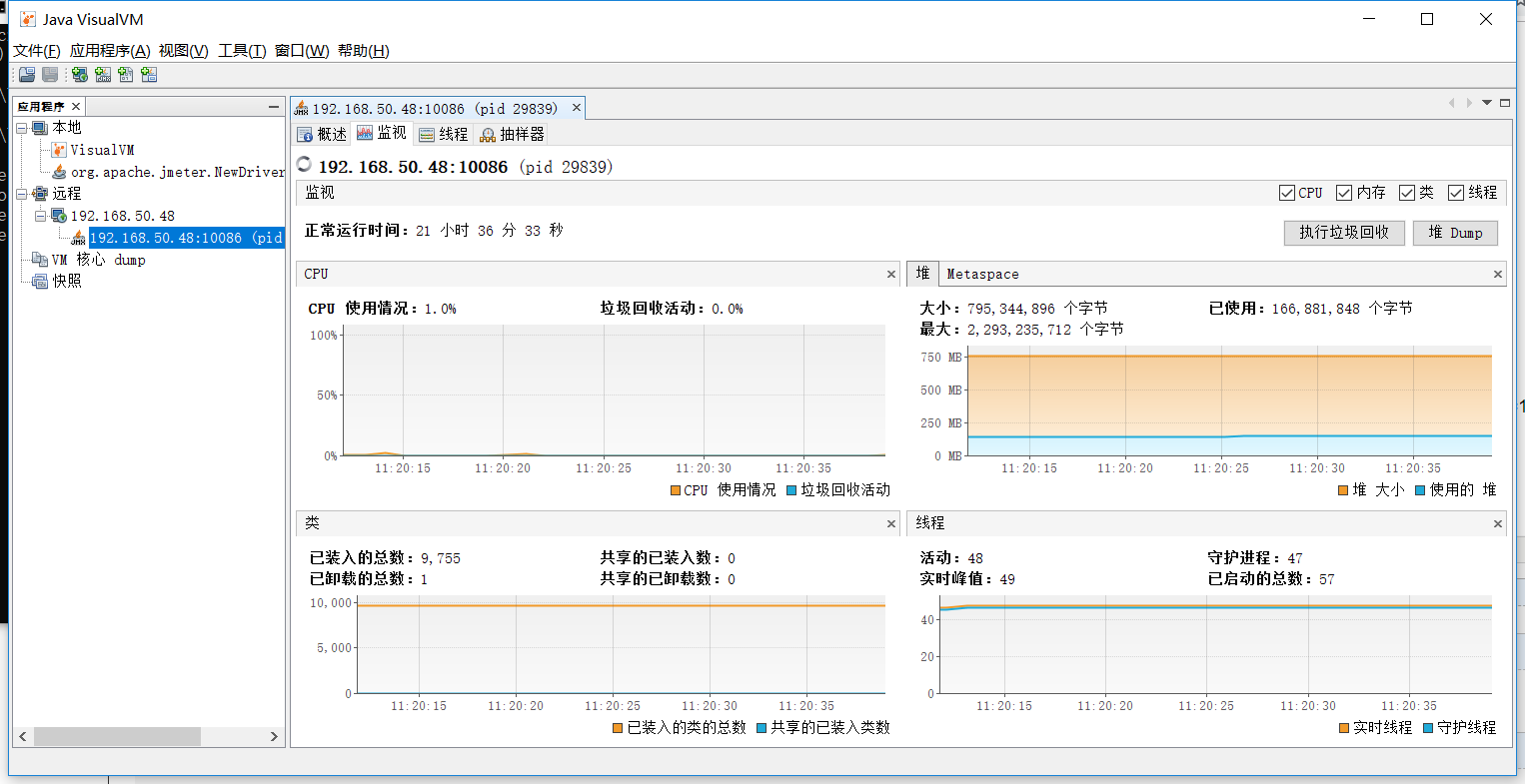
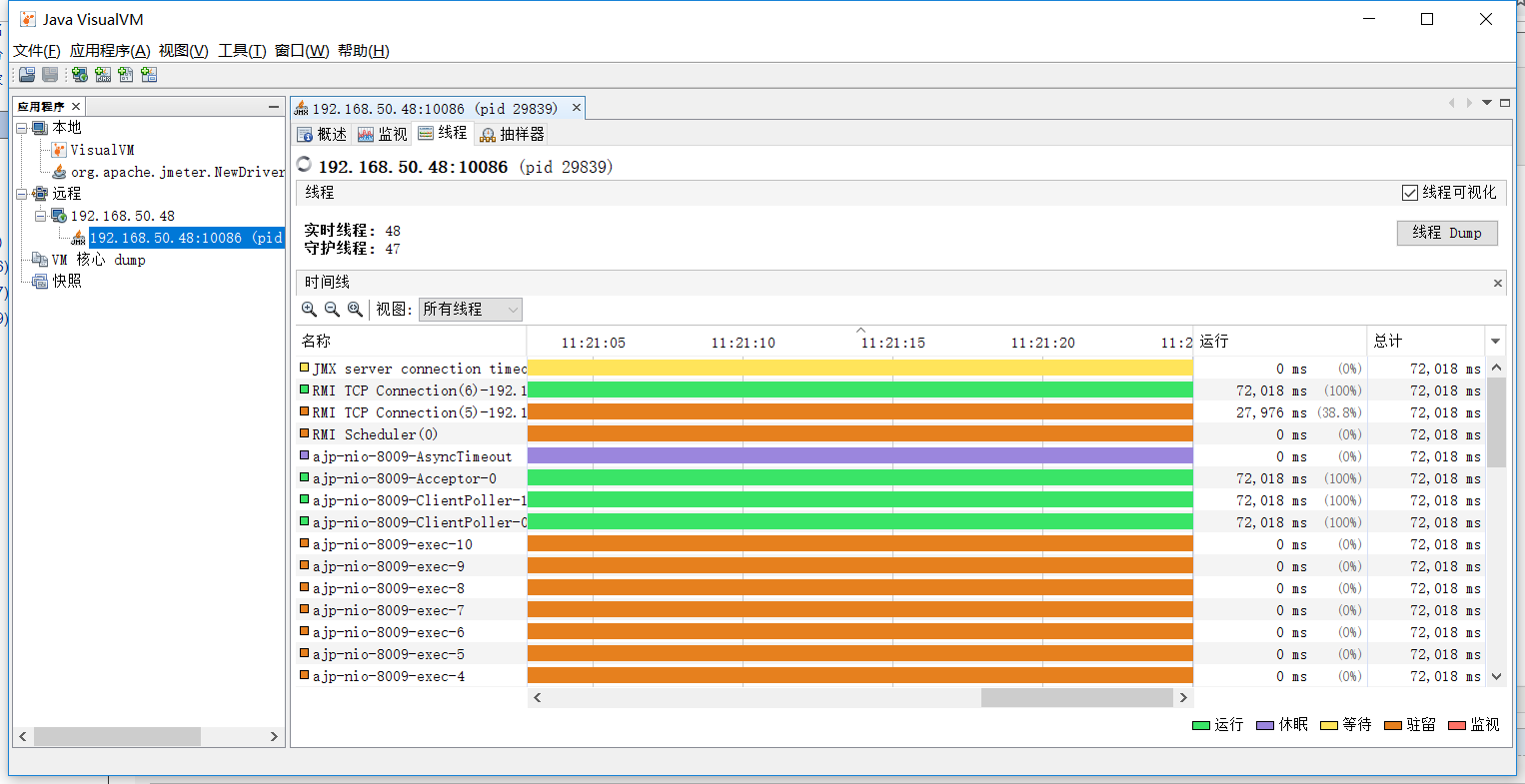
12.JDK自带工具: jvisualvm
1.需要在 tomcat/bin/cataout.sh 中第二行增加参数设置(不能换行),可以改变内存大小设置或去掉:
JAVA_OPTS="-server -Xms512m -Xmx1024m -Dcom.sun.management.jmxremote= -Djava.rmi.server.hostname=192.168.50.48 -Dcom.sun.management.jmxremote.port=10089 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
2.重启tomcat后,返回本机,cmd进入DOS命令窗口后,输入jvisualvm回车,即可打开jvisualvm图形化界面;
3.新建远程连接-->新建JMX连接,输入设置的端口10086,确认--->打开监控;
jar包形式启动的项目加参数:

自定义启动shell脚本里加参数:找到java -jar pinter.jar &,在java后面加参数


