


python-图像检索
2020-05-24 23:58 工班 阅读(1572) 评论(0) 编辑 收藏 举报图像检索
一、Bag of features算法
1.1Bag of features算法原理
1.2算法流程
二、基于Bag of features算法的图像检索
2.1代码
2.2结果截图
2.3小结
三、图像源
四、实验总结
五、遇到的问题以及解决方法
一、Bag of features算法
1.1Bag of features算法原理
此算法的思想是在我们先做一个数据集,然后找到图像中的关键词,这些关键词必须具备较高的区分度,最主要的操作就是提取sift特征,然后对这些特征点进行聚类算法,然后得到聚类中心,聚类中心就具有很高的代表性,这些聚类中心形成字典,然后自取一张图片,进行sift特征提取,就可以在字典里找到最相似的聚类中心,统计这些聚类中心出现的次数,然后就直方图表示出来,对于不同类别的图片,就可以训练处一些分类模型,然后就可以进行图片分类。
1.2算法流程
1.2.1收集数据集
1.2.2提取sift特征
1.2.3根据sift特征提取结果,进行聚类,得到一个字典
1.2.4根据字典将图片表示成向量(直方图);
1.2.5训练分类器或者用 KNN 进行检索
提取特征:
我们为了是图片具有较高的分辨度,我们使用sift特征提取,保证旋转不变性和尺度不变性,每个特征点都是128维的向量,将会提取很多的特征点
得到字典:
我们再次之前提取了很多的特征向量,然后就对这些特征向量进行k-means聚类,k值根据实际情况而定。聚类完成后,我们就得到了这 k 个向量组成的字典,这 k 个向量有一个通用的表达,叫 visual word。
直方图表示:
聚类之后,我们匹配图片的「SIFT」向量与字典中的 visual word,统计出最相似的向量出现的次数,最后得到这幅图片的直方图向量。
训练分类器:
当我们得到每幅图片的直方图向量后,剩下的这一步跟以往的步骤是一样的。无非是根据数据库图片的向量以及图片的标签,训练分类器模型。然后对需要预测的图片,我们仍然按照上述方法,提取「SIFT」特征,再根据字典量化直方图向量,用分类器模型对直方图向量进行分类。当然,也可以直接根据 KNN 算法对直方图向量做相似性判断。
二、图像源
三、基于Bag of features算法的图像检索
3.1读取图片,提取特征,建立字典
代码
1 # -*- coding: utf-8 -*- 2 import pickle 3 from PCV.imagesearch import vocabulary 4 from PCV.tools.imtools import get_imlist 5 from PCV.localdescriptors import sift 6 7 #获取图像列表 8 imlist = get_imlist('D:/new/feng/') 9 nbr_images = len(imlist) 10 #获取特征列表 11 featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)] 12 13 #提取文件夹下图像的sift特征 14 for i in range(nbr_images): 15 sift.process_image(imlist[i], featlist[i]) 16 17 #生成词汇 18 voc = vocabulary.Vocabulary('ukbenchtest') 19 voc.train(featlist, 100, 10) 20 #保存词汇 21 # saving vocabulary 22 with open('D:/new/feng//vocabulary.pkl', 'wb') as f: 23 pickle.dump(voc, f) 24 print ('vocabulary is:', voc.name, voc.nbr_words)
3.1.2结果截图
sift文件:

PKL文件:

3.2遍历图像,然后将向量特征投影到字典里并提交给数据库
代码
1 import pickle 2 from PCV.imagesearch import imagesearch 3 from PCV.localdescriptors import sift 4 from sqlite3 import dbapi2 as sqlite 5 from PCV.tools.imtools import get_imlist 6 7 #获取图像列表 8 imlist = get_imlist('D:/new/feng/') 9 nbr_images = len(imlist) 10 #获取特征列表 11 featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)] 12 13 #载入词汇 14 with open('D:/new/feng//vocabulary.pkl', 'rb') as f: 15 voc = pickle.load(f) 16 #创建索引 17 indx = imagesearch.Indexer('testImaAdd.db',voc) 18 indx.create_tables() 19 20 #遍历所有的图像,并将它们的特征投影到词汇上 21 for i in range(nbr_images)[:1000]: 22 locs,descr = sift.read_features_from_file(featlist[i]) 23 indx.add_to_index(imlist[i],descr) 24 25 #提交到数据库 26 indx.db_commit() 27 con = sqlite.connect('testImaAdd.db') 28 print(con.execute('select count (filename) from imlist').fetchone()) 29 print(con.execute('select * from imlist').fetchone())
实验结果截图:

数据库

4、进行查询测试
代码
1 # -*- coding: utf-8 -*- 2 import pickle 3 from PCV.localdescriptors import sift 4 from PCV.imagesearch import imagesearch 5 from PCV.geometry import homography 6 from PCV.tools.imtools import get_imlist 7 8 # 载入图像列表 9 imlist = get_imlist('D:/new/feng/') 10 nbr_images = len(imlist) 11 # 载入特征列表 12 featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)] 13 14 # 载入词汇 15 with open('D:/new/feng/vocabulary.pkl', 'rb') as f: 16 voc = pickle.load(f) 17 18 src = imagesearch.Searcher('testImaAdd.db', voc) 19 20 # 查询图像索引和查询返回的图像数 21 q_ind = 5 22 nbr_results = 20 23 24 # 常规查询(按欧式距离对结果排序) 25 res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]] 26 print('top matches (regular):', res_reg) 27 28 # 载入查询图像特征 29 q_locs, q_descr = sift.read_features_from_file(featlist[q_ind]) 30 fp = homography.make_homog(q_locs[:, :2].T) 31 32 # 用单应性进行拟合建立RANSAC模型 33 model = homography.RansacModel() 34 rank = {} 35 36 # 载入候选图像的特征 37 for ndx in res_reg[1:]: 38 locs, descr = sift.read_features_from_file(featlist[ndx])
结果截图:
四、实验总结
sift特征提取具有旋转不变性和尺寸不变性,还有数据源的像素不能过大,否则运行速度会很慢,
五、遇到的问题以及解决方法

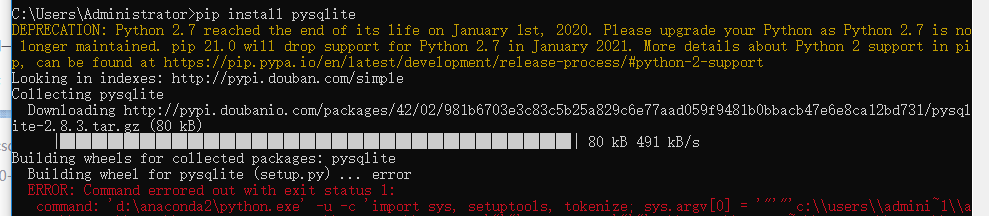
我用了这个代码 ,还是会报错
pip install pysqlite

然后我复制了报错的最后一样在cmd中运行
再次输入上面的代码,依然出错,后面我发现我少加了一个3
加了3之后,还要再imagesearch.py中加入
from numpy import *
import pickle
import sqlite3
from functools import cmp_to_key
import operator
class Indexer(object):
def __init__(self,db,voc):
""" Initialize with the name of the database
and a vocabulary object. """
self.con = sqlite3.connect(db)
self.voc = voc
def __del__(self):
self.con.close()
def db_commit(self):
self.con.commit()
def get_id(self,imname):
""" Get an entry id and add if not present. """
cur = self.con.execute(
"select rowid from imlist where filename='%s'" % imname)
res=cur.fetchone()
if res==None:
cur = self.con.execute(
"insert into imlist(filename) values ('%s')" % imname)
return cur.lastrowid
else:
return res[0]
def is_indexed(self,imname):
""" Returns True if imname has been indexed. """
im = self.con.execute("select rowid from imlist where filename='%s'" % imname).fetchone()
return im != None
def add_to_index(self,imname,descr):
""" Take an image with feature descriptors,
project on vocabulary and add to database. """
if self.is_indexed(imname): return
print ('indexing', imname)
# get the imid
imid = self.get_id(imname)
# get the words
imwords = self.voc.project(descr)
nbr_words = imwords.shape[0]
# link each word to image
for i in range(nbr_words):
word = imwords[i]
# wordid is the word number itself
self.con.execute("insert into imwords(imid,wordid,vocname) values (?,?,?)", (imid,word,self.voc.name))
# store word histogram for image
# use pickle to encode NumPy arrays as strings
self.con.execute("insert into imhistograms(imid,histogram,vocname) values (?,?,?)", (imid,pickle.dumps(imwords),self.voc.name))
def create_tables(self):
""" Create the database tables. """
self.con.execute('create table imlist(filename)')
self.con.execute('create table imwords(imid,wordid,vocname)')
self.con.execute('create table imhistograms(imid,histogram,vocname)')
self.con.execute('create index im_idx on imlist(filename)')
self.con.execute('create index wordid_idx on imwords(wordid)')
self.con.execute('create index imid_idx on imwords(imid)')
self.con.execute('create index imidhist_idx on imhistograms(imid)')
self.db_commit()
第二个报错是

我看了一个学姐的是加入一些代码,但是仍然报同样的错误,这个问题还没有解决,所以没有截图,实验总结是分析不出来

