计算机基础(5)
压缩算法
我们想必都有过压缩和 解压缩文件的经历,当文件太大时,我们会使用文件压缩来降低文件的占用空间。比如微信上传文件的限制是100 MB,我这里有个文件夹无法上传,但是我解压完成后的文件一定会小于 100 MB,那么我的文件就可以上传了。
此外,我们把相机拍完的照片保存到计算机上的时候,也会使用压缩算法进行文件压缩,文件压缩的格式一般是JPEG。
那么什么是压缩算法呢?压缩算法又是怎么定义的呢?在认识算法之前我们需要先了解一下文件是如何存储的
文件存储
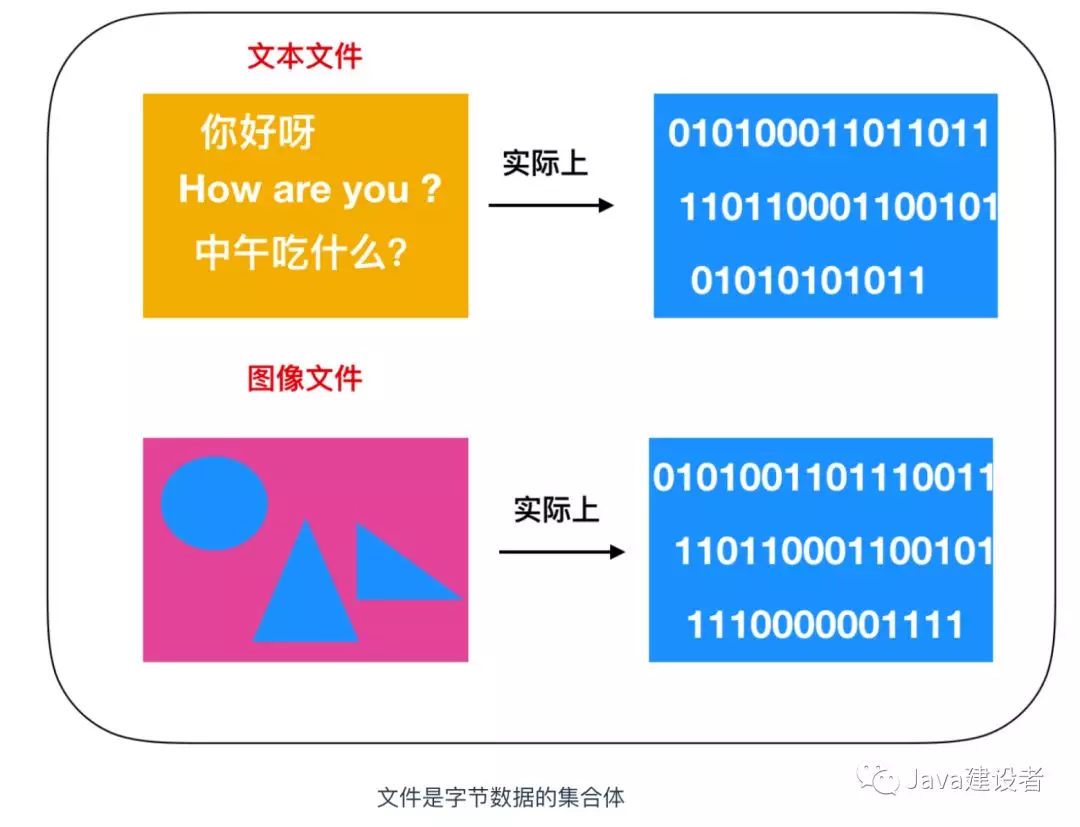
文件是将数据存储在磁盘等存储媒介的一种形式。程序文件中最基本的存储数据单位是字节。文件的大小不管是 xxxKB、xxxMB等来表示,就是因为文件是以字节 B = Byte 为单位来存储的。
文件就是字节数据的集合。用 1 字节(8 位)表示的字节数据有 256 种,用二进制表示的话就是 0000 0000 - 1111 1111 。如果文件中存储的数据是文字,那么该文件就是文本文件。如果是图形,那么该文件就是图像文件。在任何情况下,文件中的字节数都是连续存储的。
压缩算法的定义
上面介绍了文件的集合体其实就是一堆字节数据的集合,那么我们就可以来给压缩算法下一个定义。
压缩算法(compaction algorithm)指的就是数据压缩的算法,主要包括压缩和还原(解压缩)的两个步骤。
其实就是在不改变原有文件属性的前提下,降低文件字节空间和占用空间的一种算法。
根据压缩算法的定义,我们可将其分成不同的类型:
有损和无损
无损压缩:能够无失真地从压缩后的数据重构,准确地还原原始数据。可用于对数据的准确性要求严格的场合,如可执行文件和普通文件的压缩、磁盘的压缩,也可用于多媒体数据的压缩。该方法的压缩比较小。如差分编码、RLE、Huffman编码、LZW编码、算术编码。
有损压缩:有失真,不能完全准确地恢复原始数据,重构的数据只是原始数据的一个近似。可用于对数据的准确性要求不高的场合,如多媒体数据的压缩。该方法的压缩比较大。例如预测编码、音感编码、分形压缩、小波压缩、JPEG/MPEG。
对称性
如果编解码算法的复杂性和所需时间差不多,则为对称的编码方法,多数压缩算法都是对称的。但也有不对称的,一般是编码难而解码容易,如 Huffman 编码和分形编码。但用于密码学的编码方法则相反,是编码容易,而解码则非常难。
帧间与帧内
在视频编码中会同时用到帧内与帧间的编码方法,帧内编码是指在一帧图像内独立完成的编码方法,同静态图像的编码,如 JPEG;而帧间编码则需要参照前后帧才能进行编解码,并在编码过程中考虑对帧之间的时间冗余的压缩,如 MPEG。
实时性
在有些多媒体的应用场合,需要实时处理或传输数据(如现场的数字录音和录影、播放MP3/RM/VCD/DVD、视频/音频点播、网络现场直播、可视电话、视频会议),编解码一般要求延时 ≤50 ms。这就需要简单/快速/高效的算法和高速/复杂的CPU/DSP芯片。
分级处理
有些压缩算法可以同时处理不同分辨率、不同传输速率、不同质量水平的多媒体数据,如JPEG2000、MPEG-2/4。
这些概念有些抽象,主要是为了让大家了解一下压缩算法的分类,下面我们就对具体的几种常用的压缩算法来分析一下它的特点和优劣
几种常用压缩算法的理解
RLE 算法的机制
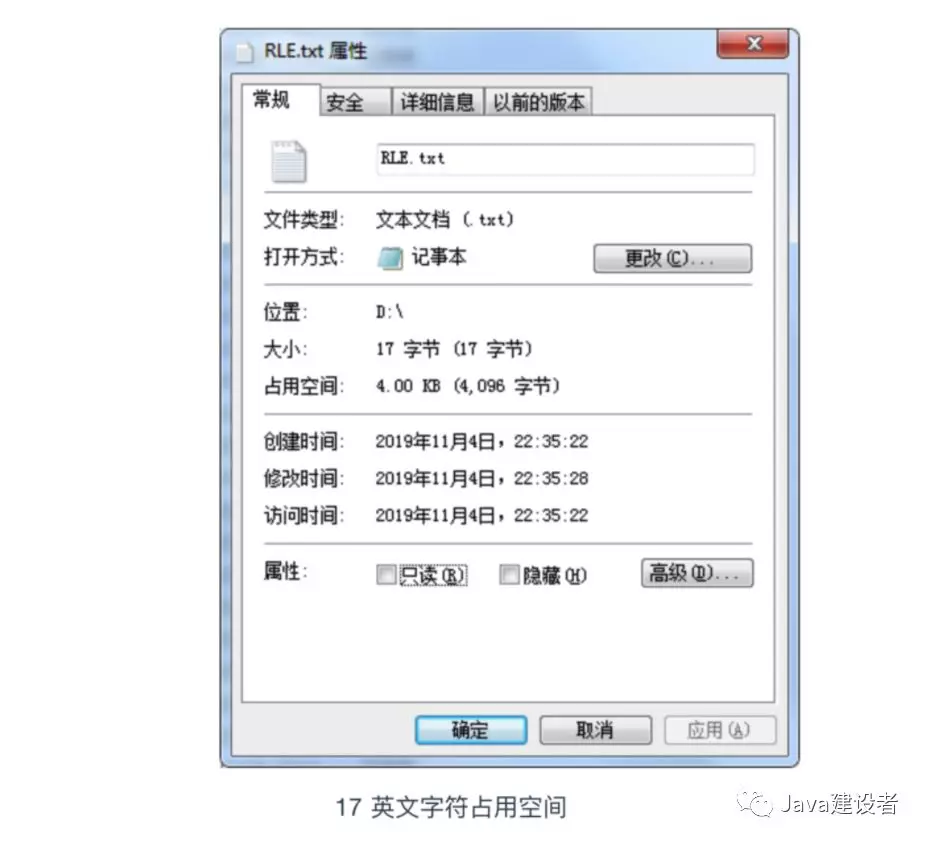
接下来就让我们正式看一下文件的压缩机制。首先让我们来尝试对 AAAAAABBCDDEEEEEF 这 17 个半角字符的文件(文本文件)进行压缩。虽然这些文字没有什么实际意义,但是很适合用来描述 RLE 的压缩机制。
由于半角字符(其实就是英文字符)是作为 1 个字节保存在文件中的,所以上述的文件的大小就是 17 字节。如图
那么,如何才能压缩该文件呢?大家不妨也考虑一下,只要是能够使文件小于 17 字节,我们可以使用任何压缩算法。
最显而易见的一种压缩方式我觉得你已经想到了,就是把相同的字符去重化,也就是 字符 * 重复次数 的方式进行压缩。所以上面文件压缩后就会变成下面这样
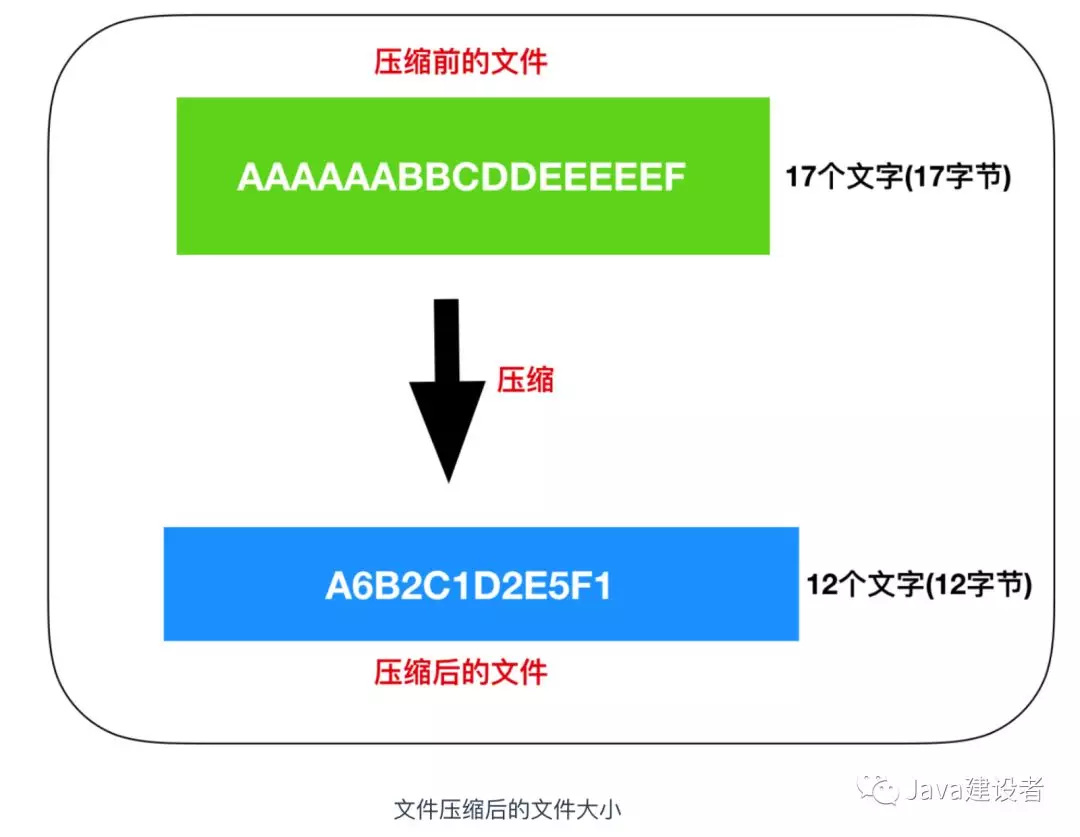
从图中我们可以看出,AAAAAABBCDDEEEEEF 的17个字符成功被压缩成了 A6B2C1D2E5F1 的12个字符,也就是 12 / 17 = 70%,压缩比为 70%,压缩成功了。
像这样,把文件内容用 数据 * 重复次数 的形式来表示的压缩方法成为 RLE(Run Length Encoding, 行程长度编码) 算法。RLE 算法是一种很好的压缩方法,经常用于压缩传真的图像等。因为图像文件的本质也是字节数据的集合体,所以可以用 RLE 算法进行压缩
哈夫曼算法和莫尔斯编码
下面我们来介绍另外一种压缩算法,即哈夫曼算法。在了解哈夫曼算法之前,你必须舍弃半角英文数字的1个字符是1个字节(8位)的数据。下面我们就来认识一下哈夫曼算法的基本思想。
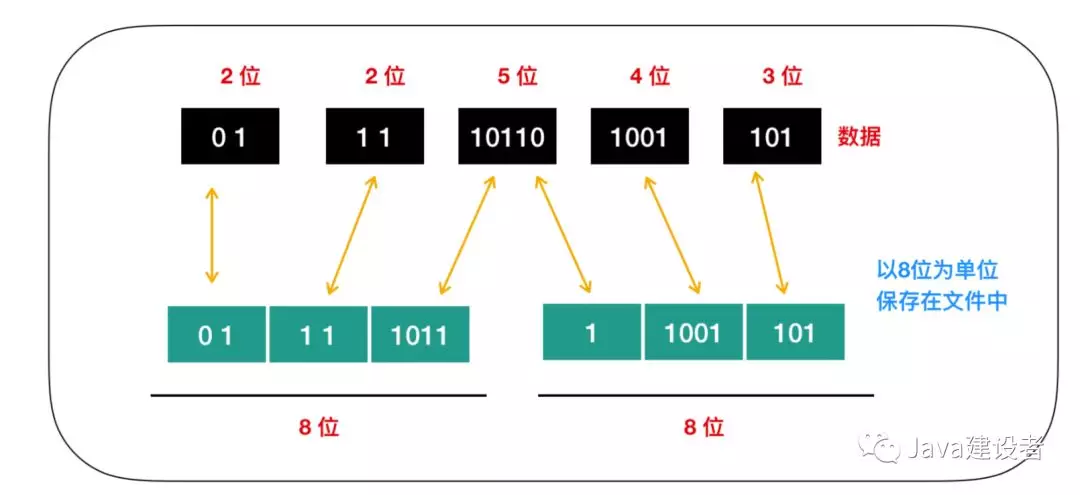
文本文件是由不同类型的字符组合而成的,而且不同字符出现的次数也是不一样的。例如,在某个文本文件中,A 出现了 100次左右,Q仅仅用到了 3 次,类似这样的情况很常见。哈夫曼算法的关键就在于 多次出现的数据用小于 8 位的字节数表示,不常用的数据则可以使用超过 8 位的字节数表示。A 和 Q 都用 8 位来表示时,原文件的大小就是 100次 * 8 位 + 3次 * 8 位 = 824位,假设 A 用 2 位,Q 用 10 位来表示就是 2 * 100 + 3 * 10 = 230 位。
不过要注意一点,最终磁盘的存储都是以8位为一个字节来保存文件的。
哈夫曼算法比较复杂,在深入了解之前我们先吃点甜品,了解一下 莫尔斯编码,你一定看过美剧或者战争片的电影,在战争中的通信经常采用莫尔斯编码来传递信息,例如下面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号