

Requests+BeautifulSoup+正则表达式爬取猫眼电影Top100(名称,演员,评分,封面,上映时间,简介)
1 # encoding:utf-8 2 from requests.exceptions import RequestException 3 import requests 4 import re 5 import json 6 from multiprocessing import Pool 7 8 def get_one_page(url): 9 try: 10 response = requests.get(url) 11 if response.status_code == 200: 12 return response.text 13 return None 14 except RequestException: 15 return None 16 17 def parse_one_page(html): 18 pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' 19 +'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>' 20 +'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S) 21 items = re.findall(pattern, html) 22 # print(items) 23 for item in items: 24 yield { 25 'index': item[0], 26 'image': item[1], 27 'title': item[2], 28 'actor': item[3].strip()[3:], 29 'time': item[4].strip()[5:], 30 'score': item[5]+item[6] 31 } 32 33 def write_to_file(content): 34 with open('MaoyanTop100.txt', 'a', encoding='utf-8') as f: 35 f.write(json.dumps(content, ensure_ascii=False)+'\n') 36 f.close() 37 38 def main(offset): 39 url = "http://maoyan.com/board/4?offset="+str(offset) 40 html = get_one_page(url) 41 # print(html) 42 # parse_one_page(html) 43 for item in parse_one_page(html): 44 print(item) 45 write_to_file(item) 46 47 if __name__ == '__main__': 48 pool = Pool() 49 # for i in range(10): 50 # main(i*10) 51 # 加快效率 52 pool.map(main, [i*10 for i in range(10)])
效果图:
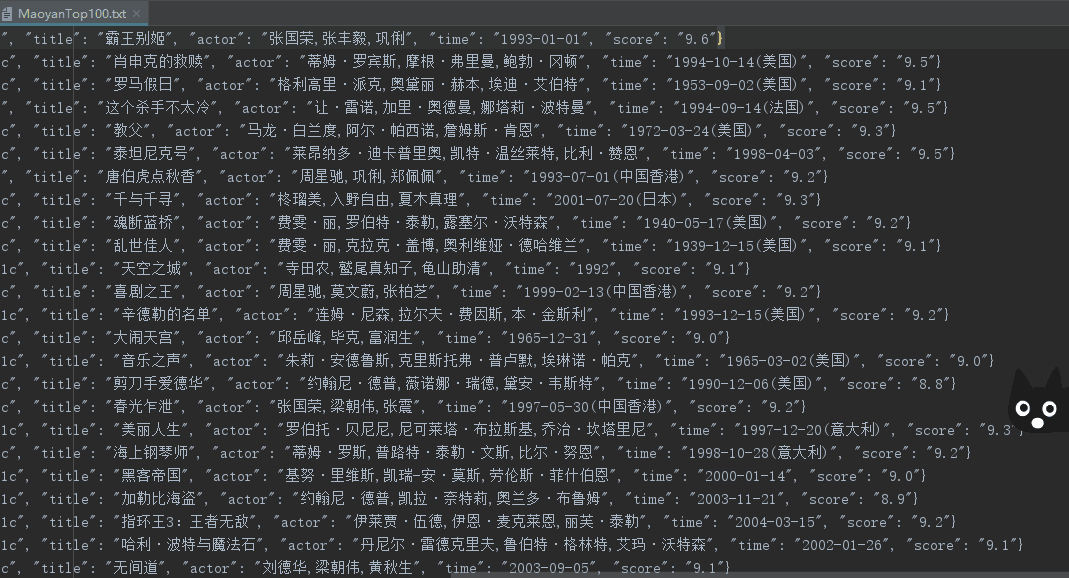
更新(获取封面以及影片简介):
1 # encoding:utf-8 2 from requests.exceptions import RequestException 3 import requests 4 import json 5 import re 6 from urllib import request 7 from bs4 import BeautifulSoup 8 9 def get_one_page(url): 10 try: 11 response = requests.get(url) 12 if response.status_code == 200: 13 return response.text 14 return None 15 except RequestException: 16 return None 17 18 def parse_one_page(html): 19 pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?href="(.*?)".*?data-src="(.*?)".*?name"><a' 20 +'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>' 21 +'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S) 22 items = re.findall(pattern, html) 23 # print(items) 24 for item in items: 25 yield { 26 'index': item[0], 27 'jump': item[1], 28 'image': item[2], 29 'title': item[3], 30 'actor': item[4].strip()[3:], 31 'time': item[5].strip()[5:], 32 'score': item[6]+item[7] 33 } 34 35 def parse_summary_page(url): 36 # url = 'https://maoyan.com/films/1203' 37 head = {} 38 # 使用代理 39 head['User - Agent'] = 'User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6788.400 QQBrowser/10.3.2843.400' 40 req = request.Request(url, headers=head) 41 response = request.urlopen(req) 42 html = response.read() 43 # 创建request对象 44 soup = BeautifulSoup(html, 'lxml') 45 # 找出div中的内容 46 soup_text = soup.find('span', class_='dra') 47 # 输出其中的文本 48 # print(soup_text.text) 49 return soup_text 50 51 def write_to_file(content): 52 with open('newMaoyanTop100.txt', 'a', encoding='utf-8') as f: 53 f.write(json.dumps(content, ensure_ascii=False)+'\n') 54 f.close() 55 56 def main(offset): 57 url = "http://maoyan.com/board/4?offset="+str(offset*10) 58 html = get_one_page(url) 59 60 for item in parse_one_page(html): 61 # print(item['number']) 62 # print(item['jump']) 63 jump_url = "https://maoyan.com"+str(item['jump']) 64 item['summary'] = str(parse_summary_page(jump_url)).replace("<span class=\"dra\">","").replace("</span>","") 65 print(item) 66 write_to_file(item) 67 68 # 写txt 69 # for item in parse_one_page(html): 70 # write_to_file(item['title']) 71 72 # 爬取100张图片 73 # path = 'E:\\myCode\\py_test\\MaoyanTop100\\images\\' 74 # for item in parse_one_page(html): 75 # urllib.request.urlretrieve(item['image'], '{}{}.jpg'.format(path, item['index'])) 76 77 if __name__ == '__main__': 78 for i in range(10): 79 main(i)
