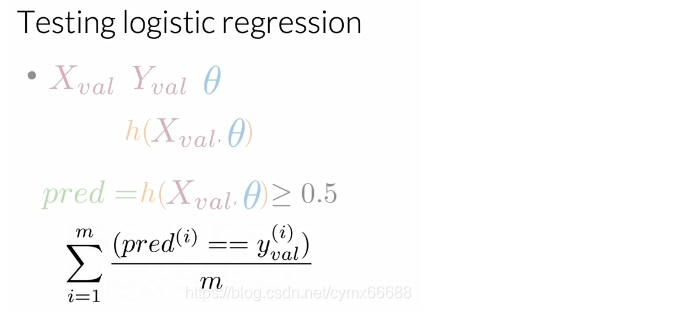吴恩达自然语言处理第一课:分类与向量空间
supervised-ml-sentiment-analysis
Supervised ML(training)
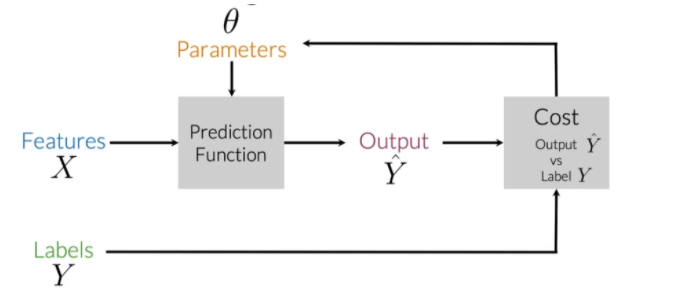
在监督机器学习中你要输入特征X和一组标签Y。现在为了确保基于你的数据能够得到最准确的预测,你的目标是尽可能减少错误率或成本。为了做到这一点,你要运行你的预测函数,它接受参数数据来映射你的特征到输出标签Y ^ \hat{Y}Y^,现在,当期望值Y和预测值Y ^ \hat{Y}Y^差值最小时从特征到标签实现最佳的映射。然后你更新你的参数,反复整个过程直到你的成本最小。
vocabulary-feature-extraction

如何将一个文本表示为一个向量。为了让你这么做,首先你必须建立一个词汇表,它允许你来编码任何一个文本或任何一条推特作为一个数字数组。然后你的词汇表,V,将会是来自你的推特列表中的唯一单词列表。为了得到这个列表,你必须浏览所有推文中的所有单词,并保存搜索中出现的每一个新单词。所以在这个例子中,你会有单词 I,然后单词是am和happy, because 等等。但是请注意,单词I和am不会在词汇表中重复出现。

让我们使用你的词汇表来提取这些推特的特征。要做到这一点,你必须核对你的词汇表中是否每个单词都出现在在推特上。像"I"这个单词而言,你会给这个特征赋值1,像这样。如果它没有出现(在推特上),你会赋值0,像那样。在这个例子中,你的推特表征由6个1和很多0构成。这对应于你的词汇表中没有出现在推特上的每一个唯一的单词。现在这种带有相对数量较小的非零值的表示称为稀疏表示。
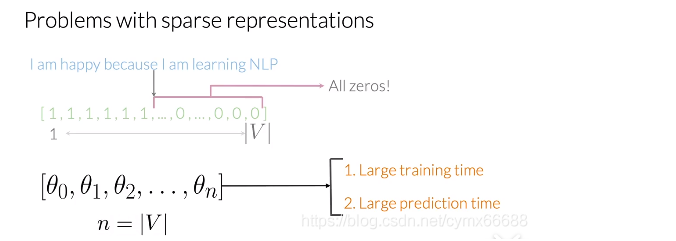
使用稀疏表示,一个逻辑回归模型必须学习n+1个参数,n个参数跟你的词汇表大小相等,你可以想象,对于大的词汇表,这将是有问题的。这将花费过多的时间来训练你的模型,而做预测所需要的时间则远远多于所需时间。
negative-and-positive-frequencies
生成"计数",,给定一个单词,你需要记录次数,也就是它出现正类的次数。给定另一个单词你需要记录它出现负类的次数。使用这两种计数,然后你抽取特征,使用这些特征进入到你的逻辑回归分类器中。
在这个情感分析的例子中,你有两类。一类与积极情绪相关联,另一类带有消极情绪。所以在你的语料库中,你有一组属于正类的2条推特和一组属于负类的2条推特。

让我们以正类为例。现在,看你的语料库。要想在你的词汇表中得到任何一个单词的正频数,你必须计算它出现在正推特中的次数。例如,单词"happy"在第一条正推特中出现一次,另一次在第二条正推特中,所以它的正频数是2。完整的表像这样。请随时暂停并检查其中的任何条目。

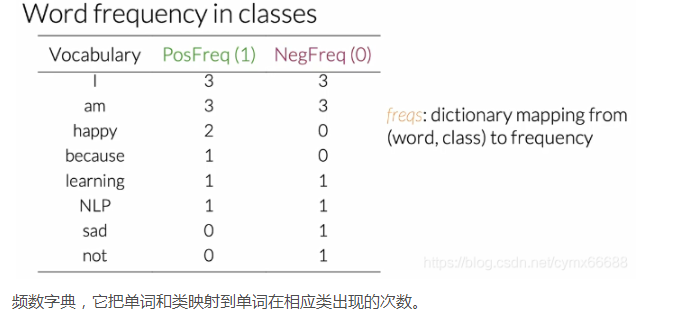
这整张表包括了语料库的正频数和负频数。在实际编码时,这个表是一个从一个单词到它频率的字典映射。所以它把单词和她对应的类映射到它在类中出现的频率或次数。
feature-extraction-with-frequencies
现在将学习把一条推特或特定的表征编码成一个3维的向量。这样的话,你的逻辑回归分类器的速度会快得多,因为你不需要学习V个特征,而只需要学习3个特征。
你只看到一个单词在这个类中的频率仅仅是这个词出现在一组推特属于那个类时的次数,这个表基本上是一个从单词类对到频率的字典,或者它只是告诉我们每个单词在对应的类中出现了多少次。
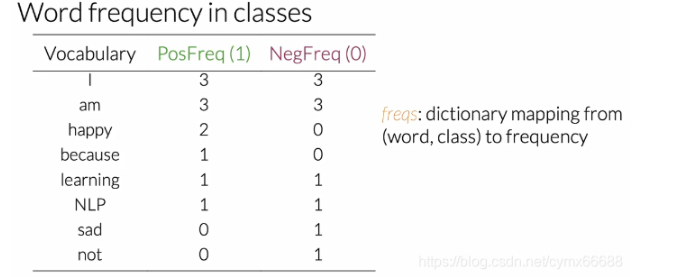
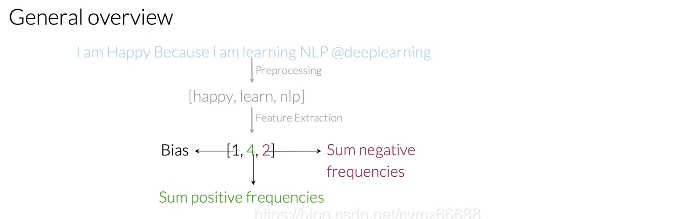
现在已经构建了频率词字典,可以使用它抽取用于情感分析的有用特征。我们来看任意的推特m。第一个特征是bias(偏差),单位等于1。第二个是在推文m上每一个唯一单词的正频率之和。第三个是在推文m上每一个唯一单词的负频率之和。所以为了抽取这个表示的特征,你只需要对单词的频率求和。
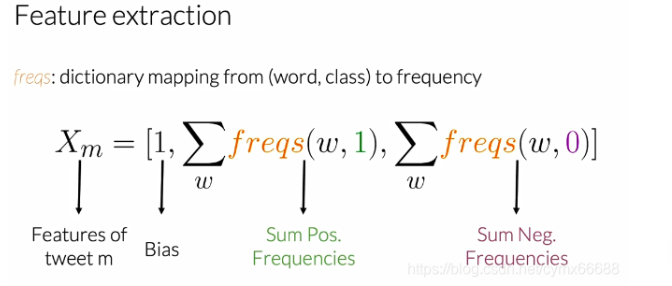
简单的,例如,以下面的推特为例。让我们来看下上节课正频率的情况。词汇表中没有在这些推特中出现的单词是"happy"和"because"。现在让我们看看你们在上一张幻灯片上看到的第二个特征。为了获得这个值,你需要对出现在推特上的词汇表中单词的频率求和。最后,你得到值等于8。

现在让我们得到第三个特征的值。它是出现在推特词汇表上的单词负频率的和。在这个例子中,把带下划线的频率加起来应该是11。

到目前为止,这个推特,这个表示将等于向量[1, 8, 11]

现在知道如何把一条推特表示为一个3维向量。
preprocessing
现在你将学习预处理的两个概念。你要学习的第一件事叫做stemming(词干分析),第二件事叫做stop words(停用词),具体来说,你要学习如何使用词干分析和停用词来预处理你的文本。
让我们处理下这条推特。首先我移除所有对推特没有重要意义的单词,又称停用词和标点符号。在实践中,你必须将推特与两个列表进行比较。一个带有英文的停用词,另一个带有标点符号。这些列表通常是比较大的,但对于本例的目的来说,它们就足够了。推特中的每个单词也出现在停用词的列表中应该被消除。所以必须要消除单词"and"、“are”、“a”、“at”。没有停用词的推特像这个。请注意,这个句子的整体意思可以毫不费力地推断出来。

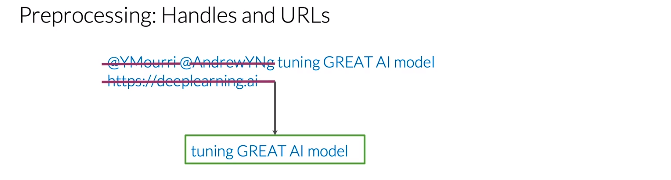
推特和其他类型的文本经常有handle和url,但这对情感分析任务没有任何价值。让我们消除这两个@和这条url。在这个过程的最后,产生的推特包含所有与其情感相关的重要信息。
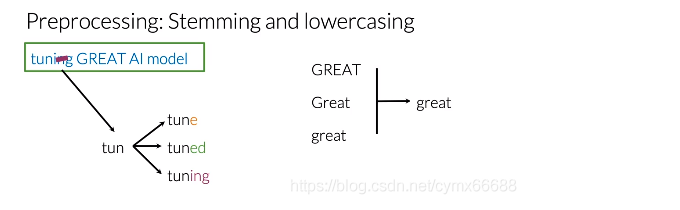
既然示例上的推特仅仅只有必要的信息,我将对每个单词进行词干提取。NLP中的词干提取只是将任何单词转换为它的基本词干,你可以将基本词干定位为用于构造词及其派生的一组字符。看下示例中的第一个词。它的词干已经完成了,因为添加一个字母"e",就组成了单词"tune"。添加后缀"ed",就组成单词"tuned",添加后缀"ing",就组成单词"tuning"。在你对语料库执行词干分析之后,单词"tune"、“tuned"和"tuning"会转化为"tun”。因此,当你对语料库中的每个单词执行这个过程时,你的词汇量将会显著减少。为了进一步减少你的词汇量而又不丢失有价值的信息,你必须把每个单词都小写。所以单词"GREAT","Great"和"great"将被视为完全相同的单词。这是最后的预处理推特作为单词列表。
putting-it-all-together
你现在使用你所学的一切来创建一个与你的训练示例的所有特征相对应的矩阵。具体来讲,我会带你进入一个算法允许你生成这个x矩阵。让我们看看你怎么创建吧。你先前看到如何预训练一个像这样的推特得到一个单词列表,包含NLP中情感分析任务所有的相关信息。有了这个单词列表,你能够使用频率字典映射得到一个很好的表示。最后,得到一个带有偏差单位的向量和两个额外的特征,用来存储你的进程推特中出现在正推文中的次数之和和它们出现在负推文中的次数之和。
在实践中,你必须对一组m个推文执行此过程。因此给定一组多个原始推文,你必须一个接一个的对它们进行预处理,已获得每个推文的对应的一组单词列表。最后,你能够使用一个频率字典映射来提取特征。

最后,你会得到一个矩阵X,m行3列,每行会包含你的每一条推特的特征。

这个过程的综合实现是比较容易的。首先,你创建频率字典,然后初始化矩阵X来匹配你的推文个数。之后,你需要仔细检查你的一组推文,删除停用词、词干,删除URL、@,和小写转换。最后,通过对推文的正向频率和负向频率求和来提取特征。这周的设计,已经提供了一些帮助函数,build_frequs和process_tweet。然而,你必须实现提取单个推文特征的函数。

logistic-regression-overview
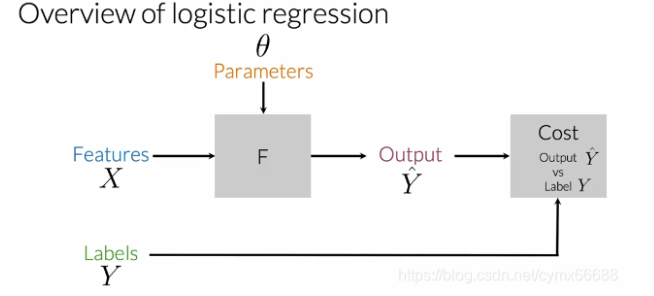
先前你学习了提取特征,现在你将使用这些已提取的特征来预测是否一个推文有一个正向情绪或是一个负向情绪。逻辑回归使用了一个sigmoid函数,输出一个在0到1之间的概率。让我们回顾下逻辑回归。简单回归下。在监督机器学习中,你输入特征和一组标签。为了基于你的数据做预测,你使用一个带有一些参数来映射你的特征的函数来输出标签。为了得到一个从你的特征到标签的最佳映射,你将成本函数最小化,这个函数用来比较你的输出值Y ^ \hat{Y}Y^和数据中真实标签Y YY有多接近。在参数被更新后,你重复这个过程直到你的成本最小化。对于逻辑回归,这个函数F等同于sigmoid函数。
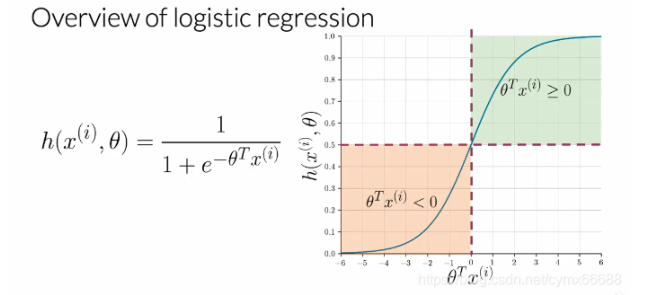
逻辑回归中用于分类的函数H是个sigmoid函数,它取决于参数θ \thetaθ,然后特征向量x i x^ixi,i ii用来表示第i ii个观察值或数据点。在推文中,是第i ii个推文。从视觉上看,sigmoid函数有这样的形式,它趋近于0,是θ \thetaθ转置与X的点乘,在这里,X趋近于负无穷,趋近于正无穷是1。对于分类,需要给定一个阈值。通常被设置为0.5,这个值相当于θ \thetaθ转置与X的点乘等于0。因此无论何时点乘是越来越大或大于等于0,预测是正的,无论何时点乘小于0,预测是负的。
让我们来看一个现在熟悉的推文和情感分析示例。看下面的推文。在预处理之后,你应该得到一个像这样的列表。请注意要把@的删除,所有都是小写,单词tuning减少到它的词干tun。然后你能够提取特征得到一个频率字典,得到一个与下面相似的向量。这里有一个偏置单位,还有两个特征是你已处理的推文中所有单词的正向频率和负向频率。现在假设你已经有一组最优参数θ \thetaθ,你能够得到sigmoid函数值,在这种情况下,等于4.92,最后,预测为一个正向情绪。
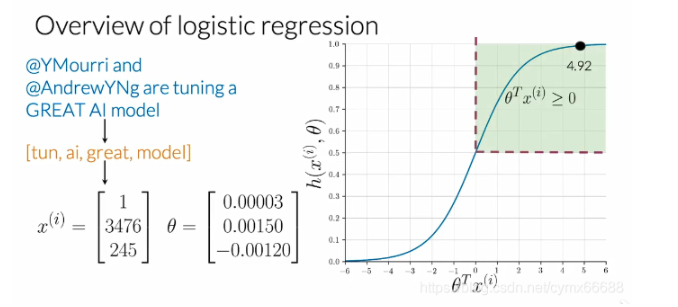
现在你知道了逻辑回归的符号,你能使用它来训练一个权重因子θ \thetaθ
logistic-regression-training
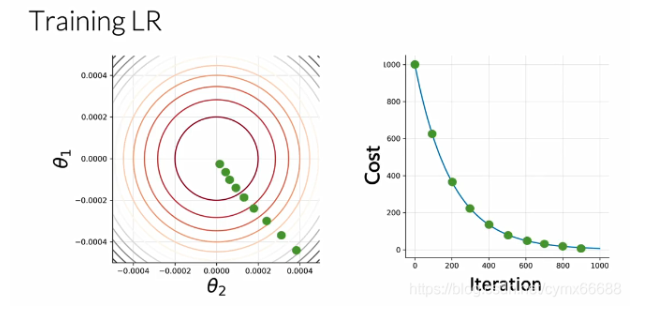
在先前的视频中,你学习了如何分类是否一个推文有一个积极情绪或是消极情绪,通过使用一个我给你的θ \thetaθ。在这个视频中,你将从零开始学习θ \thetaθ,具体的说,我将带你们通过一个算法来得到θ \thetaθ变量。让我们看看怎么做吧。为了训练你的逻辑回归分类器,迭代直到你发现一组参数θ \thetaθ,来使你的成本函数最小化。让我们假设你的损失仅取决于参数θ 1 \theta_1θ1和θ 2 \theta_2θ2,你会有一个成本函数,就像左边的等高线图。在右边,你可以看到迭代过程中成本函数的变化。首先,你必须初始化你的参数θ \thetaθ。然后你就可以自代价函数的梯度方向上更新你的θ \thetaθ。在100次迭代之后,将是这个点,在这里200次迭代,等等。在许多次迭代之后,你获得一个跟你最优成本相近的点,你的训练在这里终止了。
让我们看下模型的详细过程。首先,你必须初始化你的参数向量θ \thetaθ。然后你使用逻辑函数来得到你的每一个观察值。接着,你能够计算你的成本函数梯度并更新你的参数。最后,你计算你的成本J,根据一个停止参数或迭代的最大值来确定是否需要更多的迭代。正如你在其他课程中看到的,这种算法被称为梯度下降法。
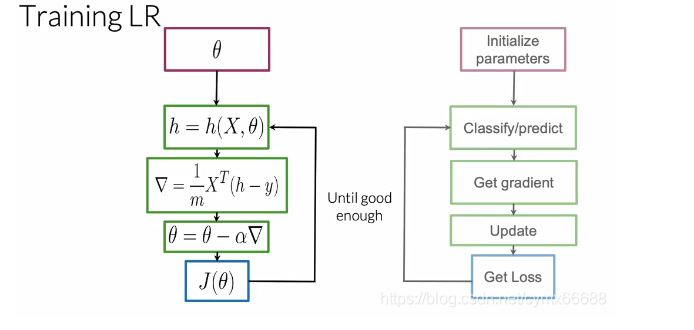
现在你有了你的θ \thetaθ变量,你想要计算你的θ \thetaθ,意味着你想要计算你的分类器。一旦你把θ \thetaθ放到你的sigmoid函数中,你能得到一个好的分类器还是一个差的分类器?
logistic-regression-testing
现在你已经有了数据,你将使用这个数据来预测我们新的数据点。例如,给一个新的推特,你使用这个数据来看这条推特是积极的还是消极的。在这情况下,你想要分析你的模型是否可以很好地概括。在这个视频中,我们将给你展示你的模型是否可以很好地概括,具体来讲,我们将给你展示如何计算模型的准确率。让我们看看你要怎么做吧。对于这个,你需要验证集X和验证集Y。在训练中被搁置的数据,也被称为验证集。θ \thetaθ是你从数据训练中得到的一组最优参数。首先,你将对验证集X计算带有参数θ \thetaθ的sigmoid函数,然后你将评估带有θ \thetaθ的h每个值是否大于或等于阈值,阈值通常设为0.5。
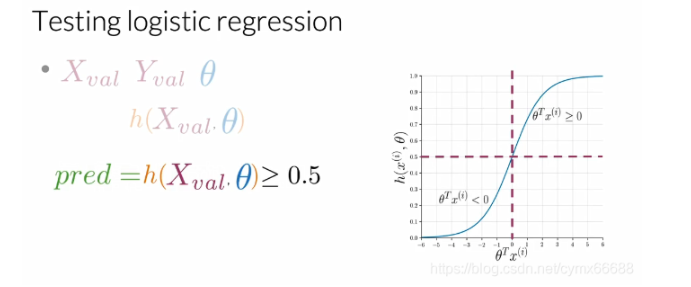
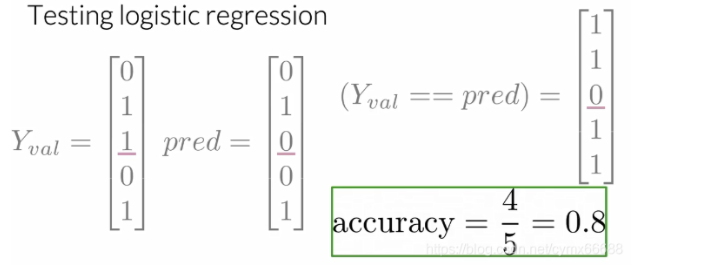
例如,如果你的h ( X v a l , θ ) h(X_val, \theta)h(Xval,θ)等于下面的向量0.5,0.8,0.5等等,直到验证集的示例数(即h ( X v a l , θ ) = [ 0.3 0.8 0.5 . . . h m ] T h(X_val, \theta)=[0.30.80.5...hm]T h(Xval,θ)=[0.30.80.5...hm]T),你将断言它的每个部分是否大于等于0.5。所以0.3大于等于0.5吗?不。因此我们的第一个预测等于0。0.8大于等于0.5吗?是的。因此我们第二个样本预测是1。0.5大于等于0.5吗?是的。因此我们第三个预测等于1,等等。最后,你将会有一个填充了0和1的向量,分别表示预测的正例和负例。
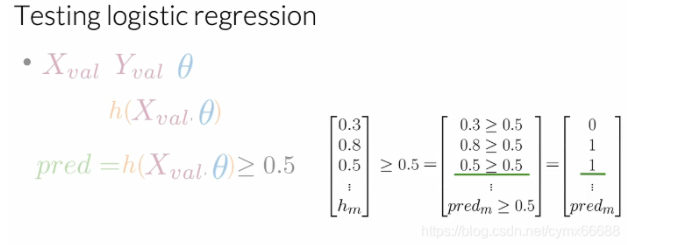
在创建预测向量之后,你可以计算验证集上你的模型准确率。这样做的话,你将对你做的预测和验证数据中每一个观察的真实值作比较。如果值等于你的预测值,那么是正确的。这个度量给了一个你的逻辑回归将正确作用于未知数据上的次数估计。所以如果你的准确率等于0.5,这意味着50%的情况下,你的模型可以工作的很好。