ClickHouse Hash Join 分析
Join (Inner Join)
Join 算法
https://clickhouse.com/docs/en/operations/settings/settings/#settings-join_algorithm
Specifies JOIN algorithm.
Possible values:
hash — Hash join algorithm is used.partial_merge — Sort-merge algorithm is used.prefer_partial_merge — ClickHouse always tries to use merge join if possible.auto — ClickHouse tries to change hash join to merge join on the fly to avoid out of memory.Default value:
hash.QueryPlan
MacBook.local :) explain select * from t1 join t2 on t1.x = t2.x1 EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON t1.x = t2.x1 Query id: b7068d63-dc61-4389-a12c-ea8016e32bc0 ┌─explain──────────────────────────────────────────────────────────────────────────────────────┐ │ Expression ((Projection + Before ORDER BY)) │ │ Join (JOIN) │ │ Expression (Before JOIN) │ │ SettingQuotaAndLimits (Set limits and quota after reading from storage) │ │ ReadFromMergeTree │ │ Expression ((Joined actions + (Rename joined columns + (Projection + Before ORDER BY)))) │ │ SettingQuotaAndLimits (Set limits and quota after reading from storage) │ │ ReadFromMergeTree │ └──────────────────────────────────────────────────────────────────────────────────────────────┘ 8 rows in set. Elapsed: 0.003 sec.
查看 Pipeline
MacBook.local :) explain pipeline select * from t1 join t2 on t1.x = t2.x1 EXPLAIN PIPELINE SELECT * FROM t1 INNER JOIN t2 ON t1.x = t2.x1 Query id: c054b9e0-d82c-4bc4-a22d-64dd9f556cf0 ┌─explain──────────────────────────┐ │ (Expression) │ │ ExpressionTransform │ │ (Join) │ │ JoiningTransform 2 → 1 │ │ FillingRightJoinSide │ │ (Expression) │ │ ExpressionTransform │ │ (SettingQuotaAndLimits) │ │ (ReadFromMergeTree) │ │ MergeTreeInOrder 0 → 1 │ │ (Expression) │ │ ExpressionTransform │ │ (SettingQuotaAndLimits) │ │ (ReadFromMergeTree) │ │ MergeTreeInOrder 0 → 1 │ └──────────────────────────────────┘ 15 rows in set. Elapsed: 0.005 sec. MacBook.local :)
HashJoin 本质
Table1 INNER JOIN Table2
- Table2 被转换成一个HashTable1.
- Table1 去HashTable1中查找,如果发现key值匹配, 就将相关列的行的值copy到结果级。如果右表有多个行匹配,那么就copy多个对应行的值到对应列。
举例
Table1 Table2
x y x1 y1
-------- ----------
1 'a' 1 'c'
2 'b' 1 'd'
-------------------
Exeute:
select * from Table1 Inner Join Table2 on Table1.x = Table2.x1
Result:
x y x1 y1
--------------------
1 'a' 1 'c'
1 'a' 1 'd'
--------------------
HashJoin 的关键
遍历左表key column的同时,遇到多个匹配需要duplicate,或者filter。
ClickHouse 中 HashJoin的实现
│ JoiningTransform 2 → 1 │ │ FillingRightJoinSide
FillingRightJoinSideTransform
本质:使用右表构建HashTable.
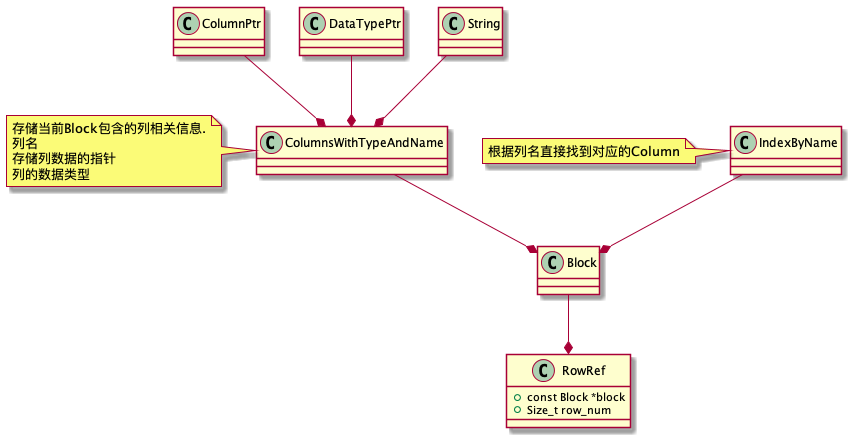
HashTable结构示意图
HashTable 可扩容.
[14789223245, [1,3,4,[Column1Ptr, Column2Ptr]] ] --HashCell
...
[79137398732, [2,[Column3Ptr]] --HashCell
...
[76349271791, [5,[Column5Ptr]] --HashCell
...
[hash值, [row_number, [指向相关列的指针]]] //
HashTable 在ClickHouse的实现
HashJoin使用的HashTable与LowCardinality结构中使用的一样。HashJoin结构体中创建HashTable,HashCell中存储StringRef与RowsRef,并且保存当前key的hash值。
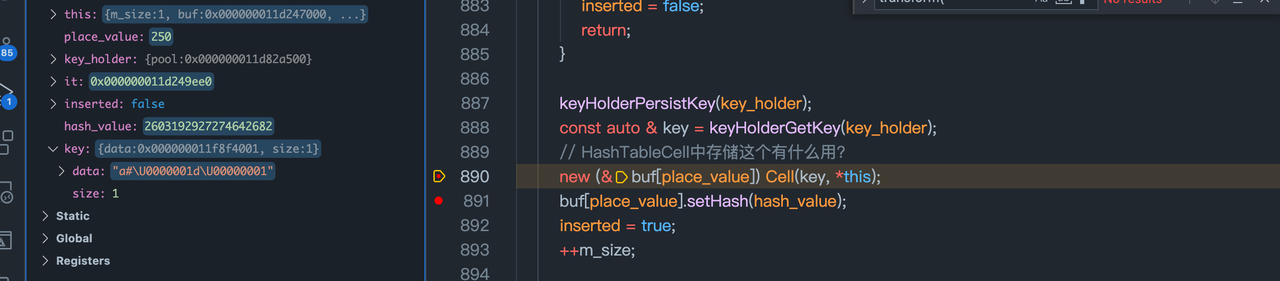
(细节)Join 构建HashMap debug 一览.

(细节)构建map_
'b' 是右表第一个元素.
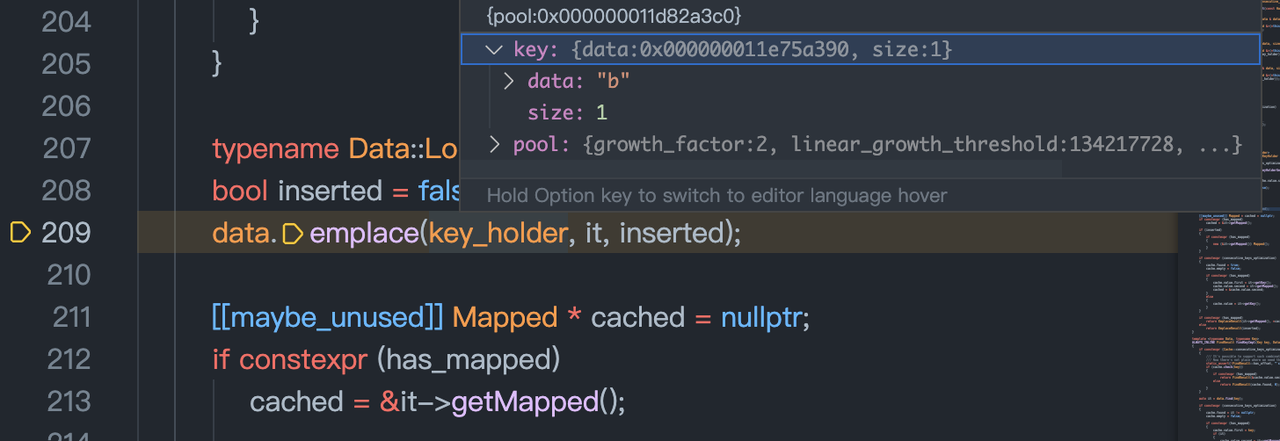
为'b'在hashTable中找位置。 b被放在HashTable中13的位置.
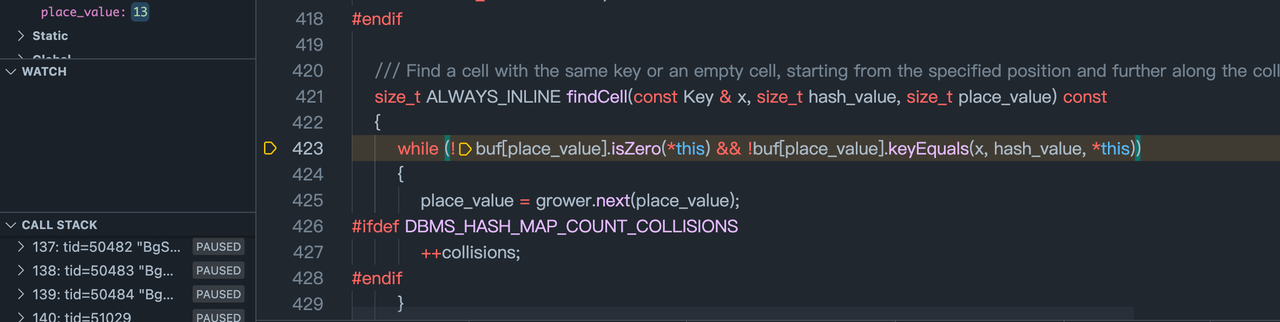
构建一个holder.key.data

构建一个在buf对应的内存位置构建一个HashCell.
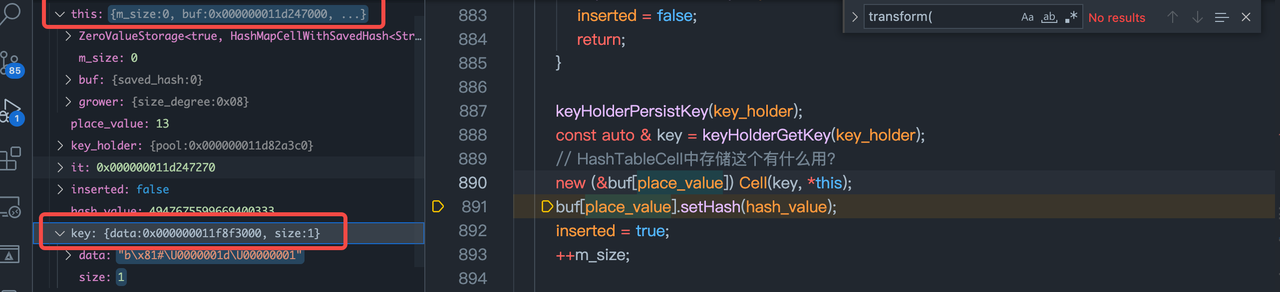
更新buf中的value(*this)的saved_hash值.
接着更新 'a'
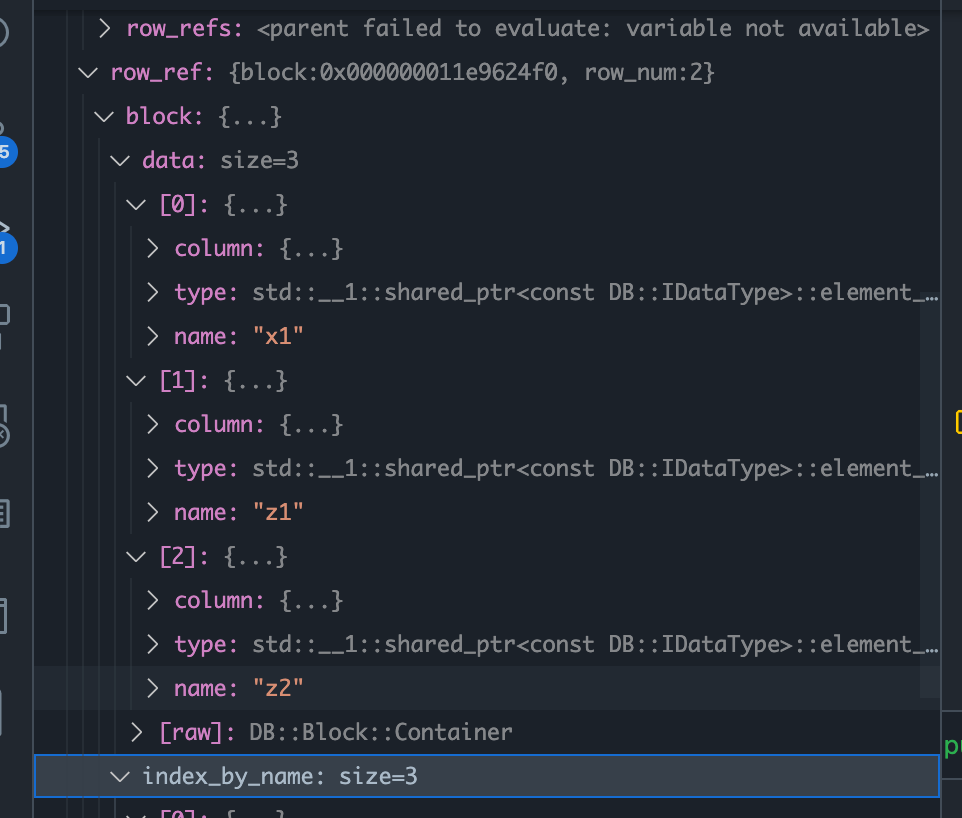
(细节)RowRef 数据结构
HashTable debug细腻.
通过右表key的hash值,我们可以从RowRef中的Block快速通过Column的随机访问快速拿到任意列的值,可以拿到所有列的相关索引的值。
struct RowRef
{
using SizeT = uint32_t; /// Do not use size_t cause of memory economy
const Block * block = nullptr;
SizeT row_num = 0;
RowRef() {}
RowRef(const Block * block_, size_t row_num_) : block(block_), row_num(row_num_) {}
};
第二个'a'写入,会在对应的RowsRef中增加row_number。
if (emplace_result.isInserted())
new (&emplace_result.getMapped()) typename Map::mapped_type(stored_block, i);
else
{
/// The first element of the list is stored in the value of the hash table, the rest in the pool.
emplace_result.getMapped().insert({stored_block, i}, pool);
}
可以看到创建HashTable,包含了其他右表的列的信息。也就是说在后续查找某列中i row的值,可以直接随机查找。
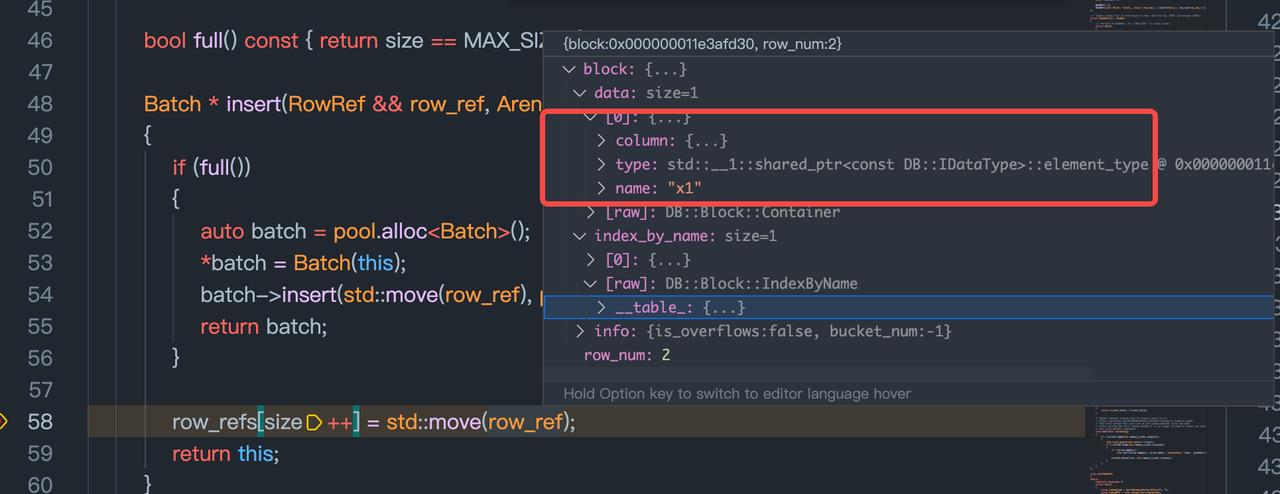
JoiningTransform::work().
此时需要FillingRightJoinSide构建的Join object。
读取参与Join的左侧的Chunk (columns)。
开始HashJoin时,需要使用Join结构中的maps_ ,
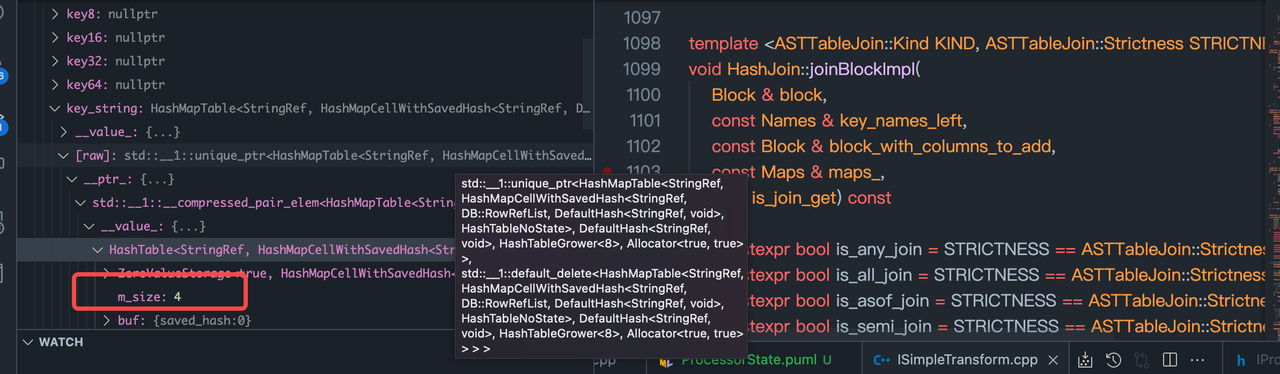
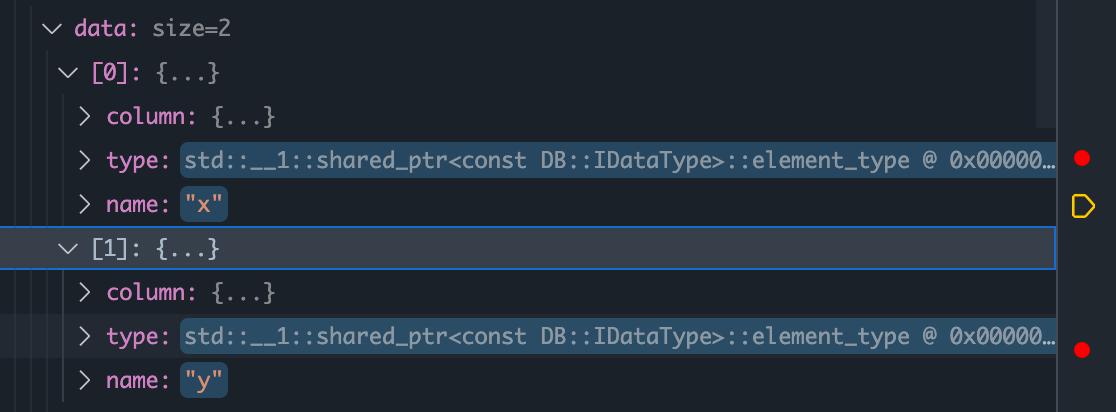
Block使用的是左侧列组成的Block.
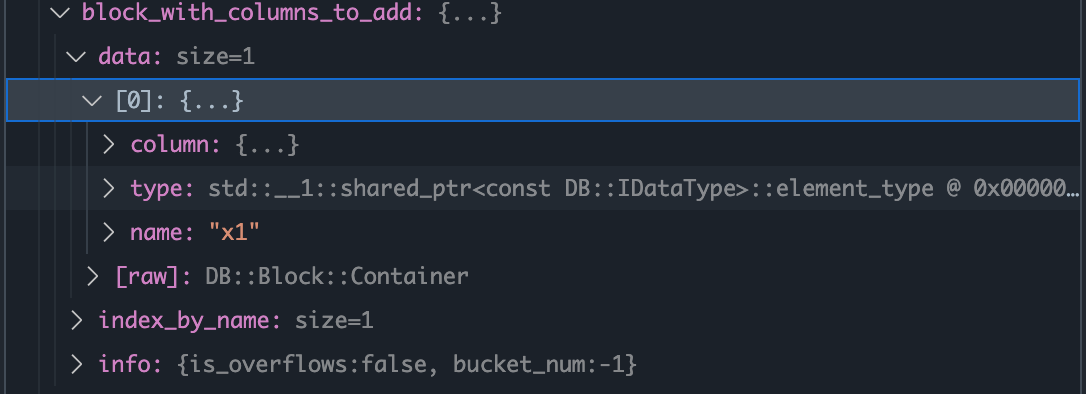
右边表需要被加到最终结果block中的column。 block_with_columns_to_add 变量
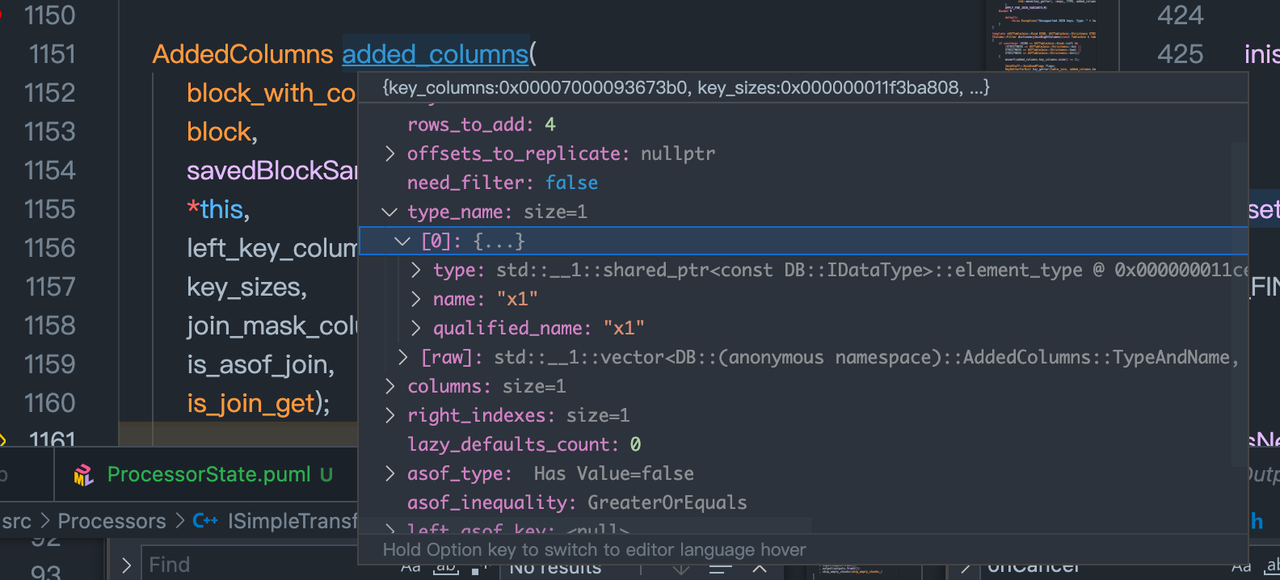
根据block_with_columns_to_add 构建added_columns。
SwitchJoinRightColumns 最重要的函数 filter 与replicate
参与计算这两个关键的要素,只需要参与Join 左表的key column 就可以。其他的filter和replicated都是和左表的key column保持一致。 这里的列都是新建并填充的,这样保证在匹配/不匹配的情况下填充时的灵活性。
size_t rows = added_columns.rows_to_add; // rows_to_add 是 左表 column的行. 此时右表的可以被map表示.
filter = IColumn::Filter(rows, 0);// 以左表行数 设置filter. 比较合理
added_columns.offsets_to_replicate = std::make_unique<IColumn::Offsets>(rows); // 以左表行数设置 需要复制的行. 合理. 如果是左表[a,a] -> 右表[a] => 那么左表行最终为[a,a]合理。
for (auto &row: rows){
// 第一层的过滤,目前不知道哪个算子提供这个join_mask_columns。测试时为Nullptr,即所有行都不进行过滤。
bool row_acceptable = !added_columns.isRowFiltered(i);
// 如果这行row需要被保留,我们需要查看这个left_key_column的第i行在map中的位置.在hashTable中查找。 获取 类型为String 类型的key
// StringRef key(chars + offsets[row - 1], offsets[row] - offsets[row - 1] - 1);
auto find_result = row_acceptable ? key_getter.findKey(map, i, pool) : FindResult();
if (find_result.isFound()){
setUsed<need_filter>(filter, i); 设置相应filter[i]为1.
// 将当前所有能和当前左表key join上的row添加到所有左边列。
// columns[i] 开启复制模式,因为columns这里一开始都是empty.
addFoundRowAll<Map, add_missing>(mapped, added_columns, current_offset); // 通过对各个列调用此方法来完成 左表 [a] -> [a,a] 右表,让 所有的列都完成对应的复制 [a,a]。
//void insertFrom(const IColumn & src, size_t n) override {
// data.push_back(assert_cast<const Self &>(src).getData()[n]);
// }
//
}
if constexpr need_replicated){
// 当前row i 更新对offsets进行更新.这里主要是为了后面replicate时,可以采用批量的方式. memcpyxxx 一种优化方式.
(*added_columns.offsets_to_replicate)[i] = current_offset;
}
}
执行完Join算法以后。将结果存放到block
for (size_t i = 0; i < added_columns.size(); ++i)
block.insert(added_columns.moveColumn(i));
返回前的replicate 操作
- ?最后返回之前需要创建一个新的column 新建 需要replicate的列。目前不知道最后一步实现的replicate的含义是什么。
for (size_t i = 0; i < existing_columns; ++i)
block.safeGetByPosition(i).column = block.safeGetByPosition(i).column->replicate(*offsets_to_replicate);
ColumnPtr ColumnString::replicate(const Offsets & replicate_offsets) const
{
size_t col_size = size();
if (col_size != replicate_offsets.size())
throw Exception("Size of offsets doesn't match size of column.", ErrorCodes::SIZES_OF_COLUMNS_DOESNT_MATCH);
auto res = ColumnString::create();
if (0 == col_size)
return res;
Chars & res_chars = res->chars;
Offsets & res_offsets = res->offsets;
res_chars.reserve(chars.size() / col_size * replicate_offsets.back());
res_offsets.reserve(replicate_offsets.back());
Offset prev_replicate_offset = 0;
Offset prev_string_offset = 0;
Offset current_new_offset = 0;
for (size_t i = 0; i < col_size; ++i)
{
size_t size_to_replicate = replicate_offsets[i] - prev_replicate_offset;
size_t string_size = offsets[i] - prev_string_offset;
for (size_t j = 0; j < size_to_replicate; ++j)
{
current_new_offset += string_size;
res_offsets.push_back(current_new_offset);
res_chars.resize(res_chars.size() + string_size);
// 这里就是利用了 前面记录的offset进行memcpy copy的优化.
memcpySmallAllowReadWriteOverflow15(
&res_chars[res_chars.size() - string_size], &chars[prev_string_offset], string_size);
}
prev_replicate_offset = replicate_offsets[i];
prev_string_offset = offsets[i];
}
return res;
}
总结
- 计算右表key的列hashTable,并将相关联的其他右表列信息也更新在map中。
- 根据map计算左表的最终结果放到block.
- 所有的计算重点都在 SwitchJoinRightColumns<KIND, STRICTNESS>(maps_, added_columns, data->type, null_map, used_flags) 函数中。
- 将右表key的列加入到block
- 返回。
收获
- RightTable到->Join,然后不同的JoiningTransform可以自由Join,将结果写入到local变量added_columns,这样可以使join并行化。
- HashTable 作用起到了关键性的作用。
-
问题:
- 在BuildQueryPlan 执行FillingRightJoinSide::transformHeader()和JoiningTransform::transformHeader()的意义是什么?
- 在JoiningTransform:: joinRightColumns()执行结束之后的对 block中已有的column进行replicate的作用是什么?
- Interpreter 执行优化?
- BlockStreaming.
- QueryPipeline = pipeline.
InBlockInputStream
Block RemoteQueryExecutor::read()
{
if (!sent_query)
{
sendQuery();
if (context->getSettingsRef().skip_unavailable_shards && (0 == connections->size()))
return {};
}
while (true)
{
if (was_cancelled)
return Block();
Packet packet = connections->receivePacket();
if (auto block = processPacket(std::move(packet)))
return *block;
else if (got_duplicated_part_uuids)
return std::get<Block>(restartQueryWithoutDuplicatedUUIDs());
}
}
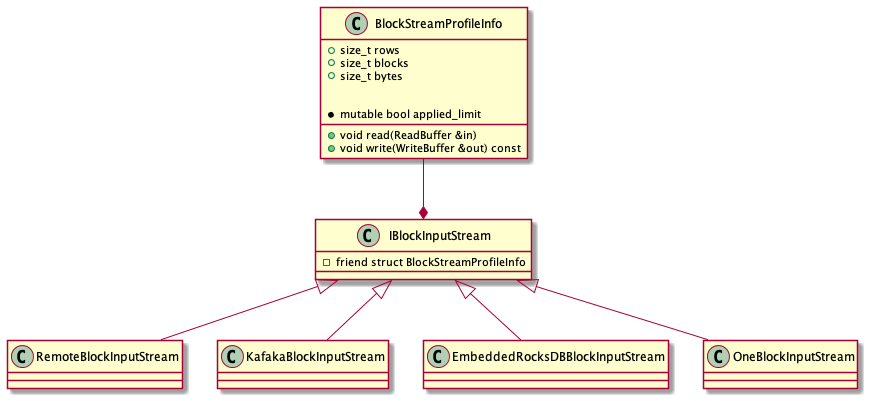
IBlockInputStream可以 输出 Block(data) 给调用者。以RemoteBlockInputStream为例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号