ClickHouse Processor & Pipeline
Processor 简述
Processor是处理SQL中各步骤数据的基本单元。数据,从Processor流入,经过Processor处理,处理后从Processor流出。
从功能上主要分为三类,
1.输入数据,抽象ISource
2.过程处理,Transform
3.结果输出(一般是常见是写磁盘),ISink
以select * from table1 语句为例,数据首先从磁盘读入ISource类型Processor0,流入Transform类型的Processor1,结果输出给Client,SQL执行结束。
Clickhouse 中的 Processor关系图![]()
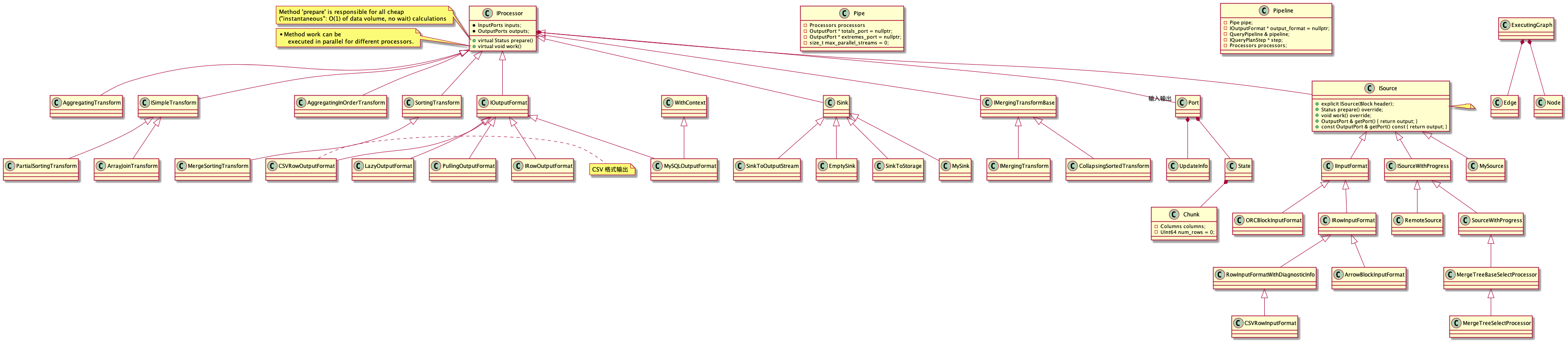
Processor的结构 (静态展示)
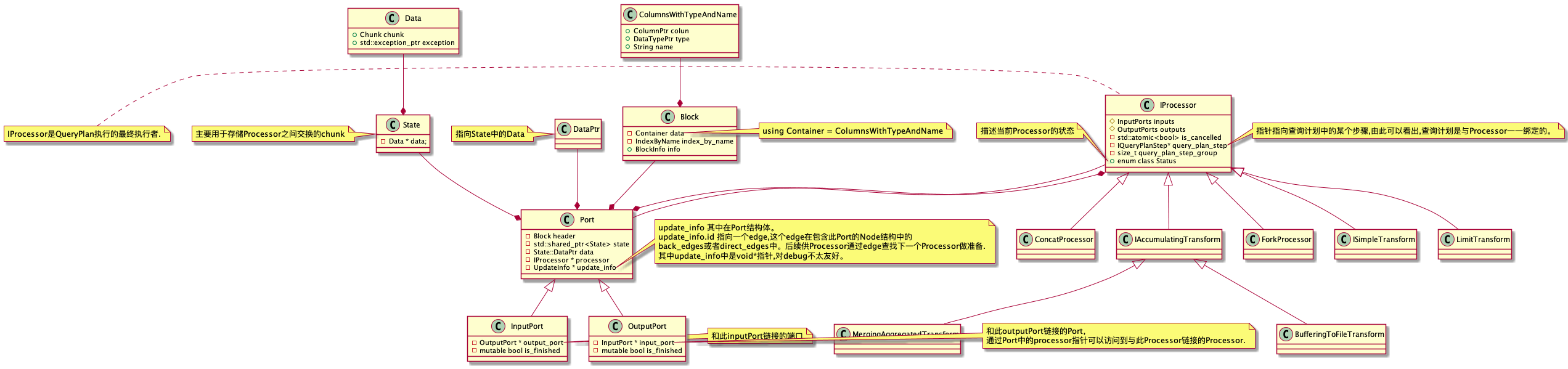
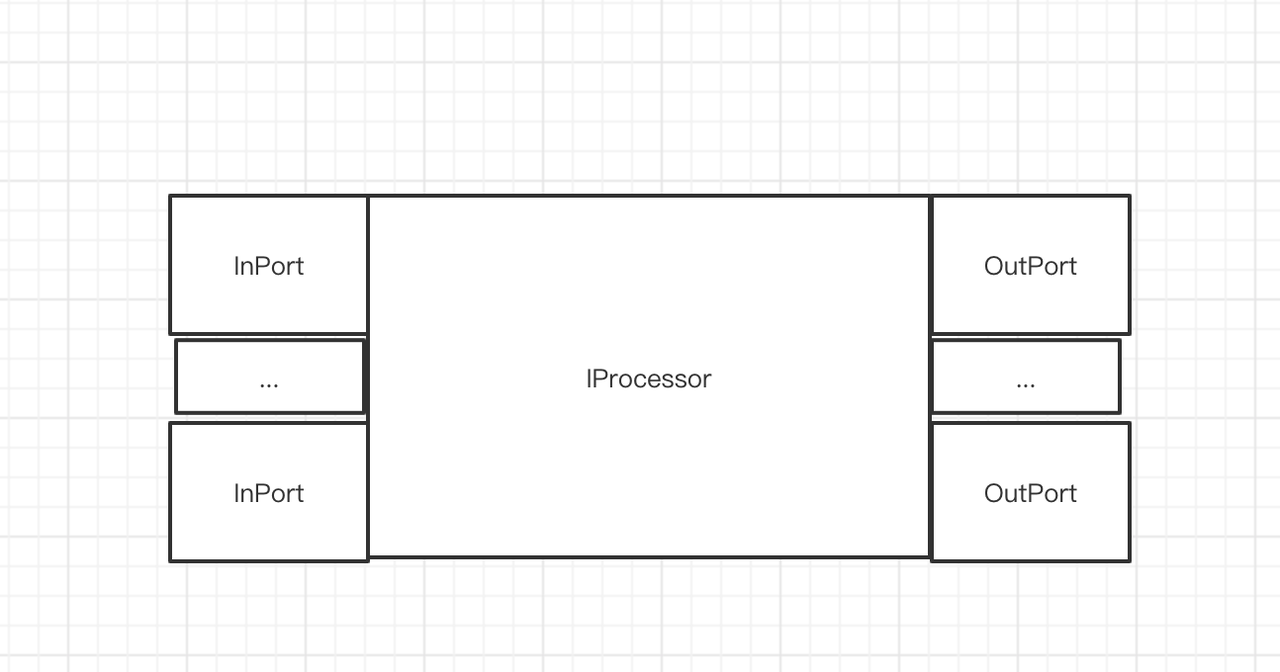
单个Processor的功能模块
2.数据流出端口 Outport
3.中间处理,Processor中的transform方法从Inport中读取数据,然后写入Outport。
例子 ConcatProcessor
这个Processor可多个Inport读取数据,然后输出结果到一个Outport

类比现实中水管联通基本单元 (图片源自网络)

链接水管设备图
引入Pipeline
Pipeline 本质
将Processor(小段水管pipe)串联构成管道。
类比现实管道 (图片源自网络)

管道
SQL中的pipeline
通过 SQL语法展示 某个执行SQL的pipeline。
例子,SELECT 查询 : SELECT id from table_map LIMIT 10, 2。
EXPLAIN PIPELINE
SELECT id
FROM table_map
LIMIT 10, 2
Query id: 078bc729-38f4-4788-8db7-875d00e74487
┌─explain────────────────────────────┐
│ (Expression) │
│ ExpressionTransform │
│ (SettingQuotaAndLimits) │
│ (Limit) │
│ Limit │
│ (ReadFromMergeTree) │
│ Concat 2 → 1 │
│ MergeTreeInOrder × 2 0 → 1 │
└────────────────────────────────────┘
↑ Progress: 8.00 rows, 230.00 B (1.43 thousand rows/s., 41.21 KB/
8 rows in set. Elapsed: 0.006 sec.
Pipeline 输出解读
- 整体语义
- Select 语句 的 pipeline,以递进关系表示依赖,上层依赖下层的输入。
- 其中pipeline ()里面的内容就是QueryPlan的节点名。 请见explain pipeline 中蓝色括号的内容与 下面query plan的内容。
- 数字语义
- 每个pipeline单元 后面都会标识并行度(默认是1没有标识), 'x' 后面的数据代表并行度(Processor的数量), n1 -> n2, '->',代表数据流向, n1代表Inport数量, n2代表OutPort数量。MergeTreeInOrder × 2 0 → 1,代表有两个并行度,0个Inport, 1个Outport。
查看SQL的执行计划 QueryPlan,我们发现表达的语义是一致的。
queryPlan.
MacBook.local :) explain select id from table_map limit 200 offset 0
Query id: 7666532a-6a3e-43c5-8160-a4539edc984d
┌─explain───────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ Limit (preliminary LIMIT (without OFFSET)) │
│ ReadFromMergeTree │
└───────────────────────────────────────────────────────────────────────────┘
↙ Progress: 4.00 rows, 221.00 B (2.73 thousand rows/s., 150.65 KB
4 rows in set. Elapsed: 0.002 sec.
Pipeline 三部曲
- Pipeline的构建
- Pipeline的执行准备
- Pipeline的执行
pipeline的构建 [开始]
局部构建Pipeline
上述SQL的例子: 以MergeTreeInOrder到Concat构建为例。
│ Concat 2 → 1 │
│ MergeTreeInOrder × 2 0 → 1 │
局部构建的Pipeline图片

图ReadFromMergeTree& ConcatProcessor 组装后的pipeline.
构建完整的Pipeline 图
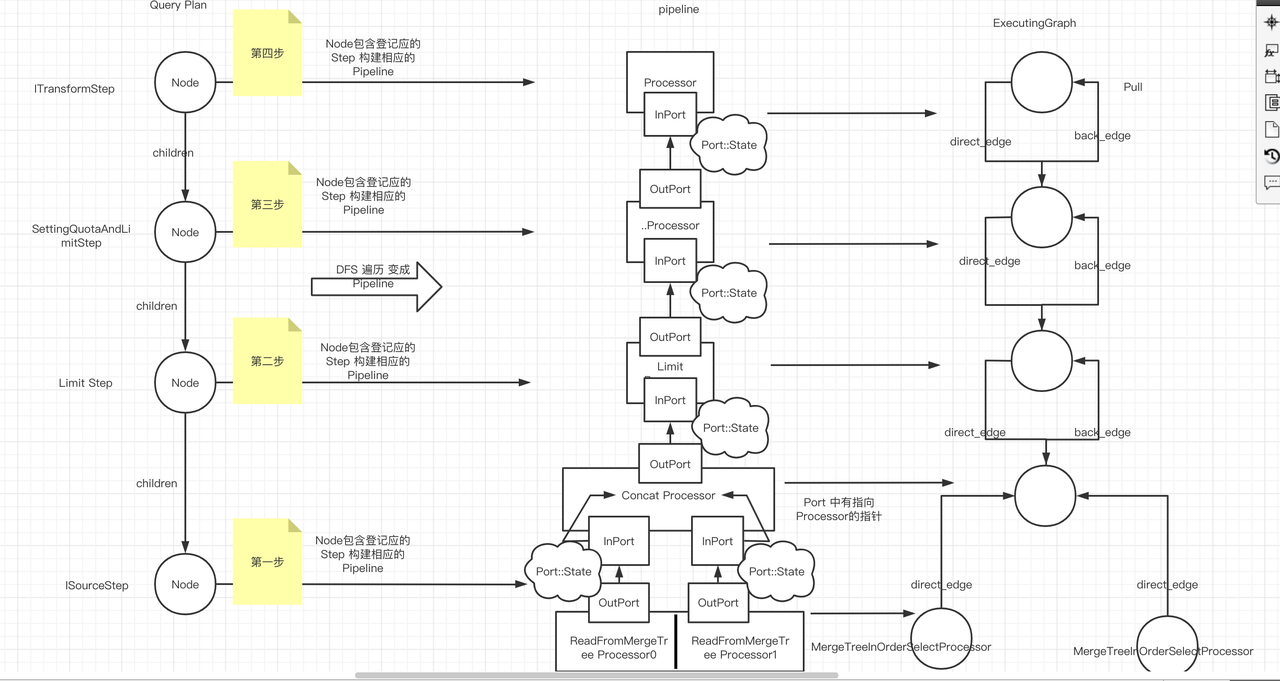
组装端口相关代码(ReadFromMergeTree 部分的Pipeline):
- DFS 根据QueryPlan 构建Pipeline (从没有children 的node开始构建第一个pipeline)。然后不断构建直到Pipeline都构建完毕。
QueryPipelinePtr QueryPlan::buildQueryPipeline(..){
QueryPipelinePtr last_pipeline;
std::stack<Frame> stack;
stack.push(Frame{.node = root});
while (!stack.empty())
{
auto & frame = stack.top();
if (last_pipeline)
{
frame.pipelines.emplace_back(std::move(last_pipeline));
last_pipeline = nullptr; //-V1048
}
size_t next_child = frame.pipelines.size();
// 当一个Node中的children都组装成了Pipeline时,那么就可以当前Node与children组装好的
// pipeline 构造新的Pipeline.
if (next_child == frame.node->children.size())
{
bool limit_max_threads = frame.pipelines.empty();
last_pipeline = frame.node->step->updatePipeline(std::move(frame.pipelines), build_pipeline_settings);
if (limit_max_threads && max_threads)
last_pipeline->limitMaxThreads(max_threads);
stack.pop();
}
else
stack.push(Frame{.node = frame.node->children[next_child]});
}
打通processor到对应Step.(暂时不明目的)
即设置
IProcessor 中的query_plan_step为当前的Step. (可能多个Processor对应一个Step).
detachProcessors() 方法:
for (auto & processor : processors)
processor->setQueryPlanStep(step, group);
即设置
IProcessor 中的query_plan_step为当前的Step. (可能多个Processor对应一个Step).
Pipeline构建 [结束]
所有的processors都存放在了last_pipeline,返回给调用者。
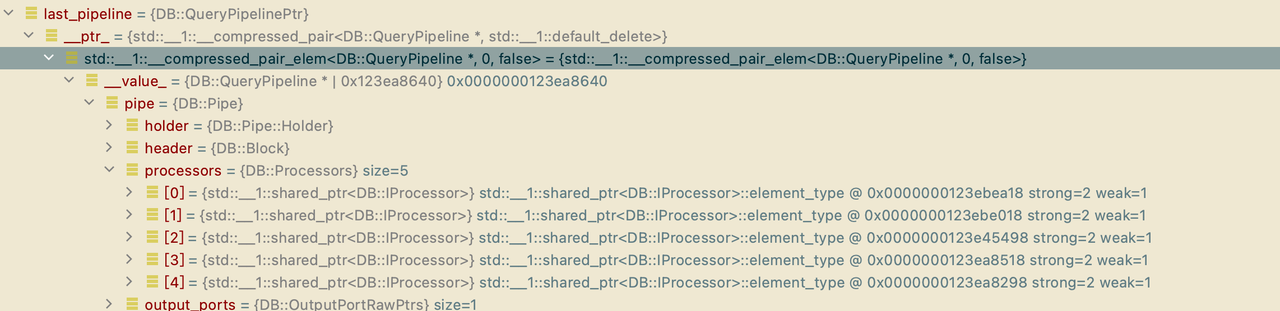
Pipeline重要数据结构分析
Pipeline中继承IProcessor的类的端口使用IProcessor中的成员变量。
ISource的 output端口中的Input_port就是 IProcessor的outputs[0]的input_port.
Pipeline中 Inport与OutPort端口间公用State。
即上游Processor在Outport流出数据(写入某个地方),就能被下游Processor 从InPort读取。
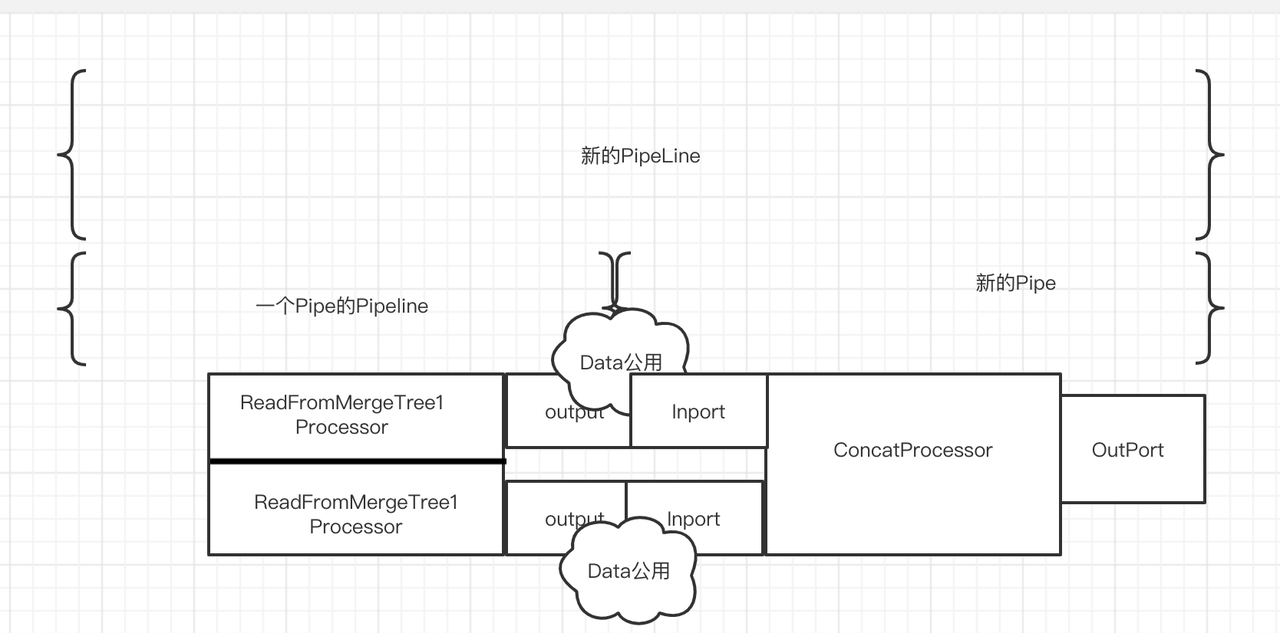
端口间数据
验证 端口间公用State.
查看State的地址.
MergeTreeOrderSelectProcessor 的 OutPort 的State

ConcatProcessor 的InPort 的State

赋值给更高级的抽象 BlockIO
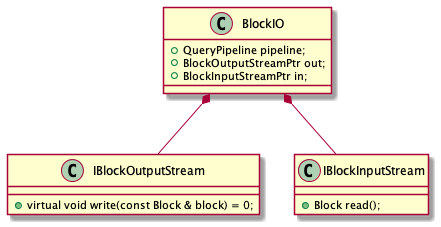
Pipeline的执行准备 [开始] 下一个Stage
构建Executing Graph
Executing Graph Node 和 edge
ExecutingGraph::ExecutingGraph(const Processors & processors)
{
uint64_t num_processors = processors.size();
nodes.reserve(num_processors);
/// Create nodes.
for (uint64_t node = 0; node < num_processors; ++node)
{
IProcessor * proc = processors[node].get();
processors_map[proc] = node;
nodes.emplace_back(std::make_unique<Node>(proc, node));
}
/// Create edges.
for (uint64_t node = 0; node < num_processors; ++node)
addEdges(node);
}
Excuting Graph edge 更新相邻Port状态
当前Processor的Port处理数据完毕后,通过edge到对下一个Processor的对应Port进行处理。
if (from_output < outputs.size())
{
was_edge_added = true;
for (auto it = std::next(outputs.begin(), from_output); it != outputs.end(); ++it, ++from_output)
{
const IProcessor * to = &it->getInputPort().getProcessor();
auto input_port_number = to->getInputPortNumber(&it->getInputPort());
Edge edge(0, false, input_port_number, from_output, &nodes[node]->post_updated_output_ports);
// 将edge添加到当前node的direct_edges中. 使用move语义.
auto & added_edge = addEdge(nodes[node]->direct_edges, std::move(edge), from, to);
// Port中的update_info 和 edge的update_info 指向同一个地方.
it->setUpdateInfo(&added_edge.update_info);
}
}
构建Executing Graph 结束
更新Execute Graph Node状态
创建另外线程执行

创建线程池,可并行执行Execute Graph.
Pull 模式 (控制方向类比图)
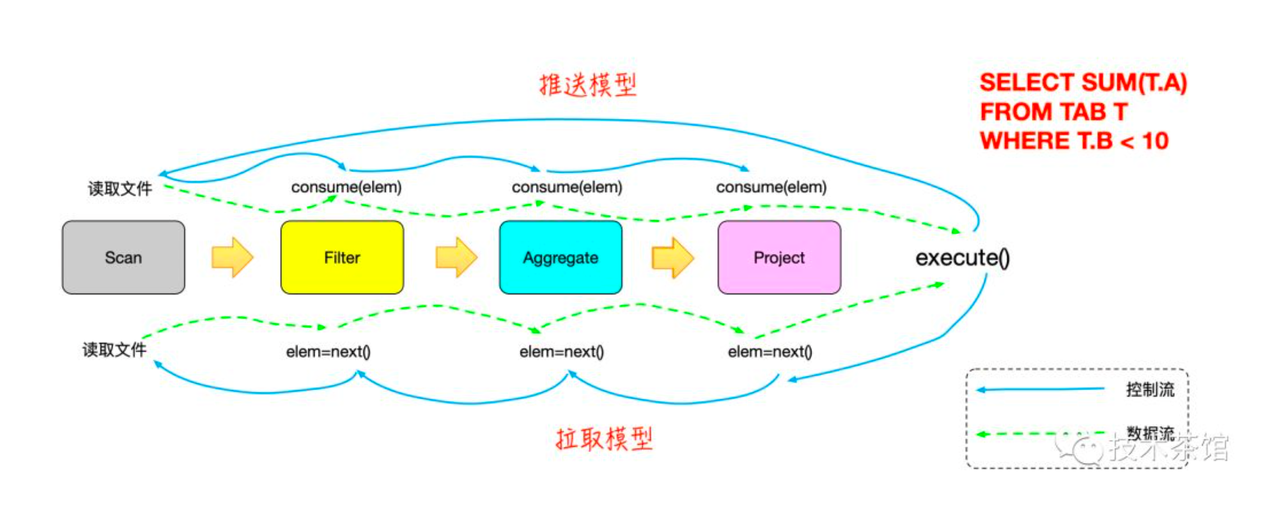
Node中的edge 方向(back vs direct)
- Node A 的direct_edge
// direct_edges 是指的 [ ] 节点A output 到child节点B
// |
// \|/ (direct_edge) 数据流指出去的edge.
// [ ] 节点B
- NodeA 的back_edges
// back_edges 是指 [ ] 节点 A 从节点B 流入数据
// /|\
// | (back_edge) 数据流指向自己的edge
[ ] 节点B
例子: ConcatProcessor 相应的Node
2个back_edges: 有两个Inport
1个direct_edge: 一个outport

Pull模式初始化
挑选所有没有OutPort的Node. (当前SQL例子为 lazyOutputFormat)
void PipelineExecutor::addChildlessProcessorsToStack(Stack & stack)
{
UInt64 num_processors = processors.size();
for (UInt64 proc = 0; proc < num_processors; ++proc)
{
// 从root指向child方向的边, 在Select查询语句中,lazyOutputFormat是没有output到其他节点的Node.
if (graph->nodes[proc]->direct_edges.empty())
{
stack.push(proc);
/// do not lock mutex, as this function is executed in single thread
graph->nodes[proc]->status = ExecutingGraph::ExecStatus::Preparing;
}
}
}
初始化所有Node的状态. 参考 控制方向类比图
递归调用 prepareProcessor(),根据Graph Node中的edge更新所有Node状态。
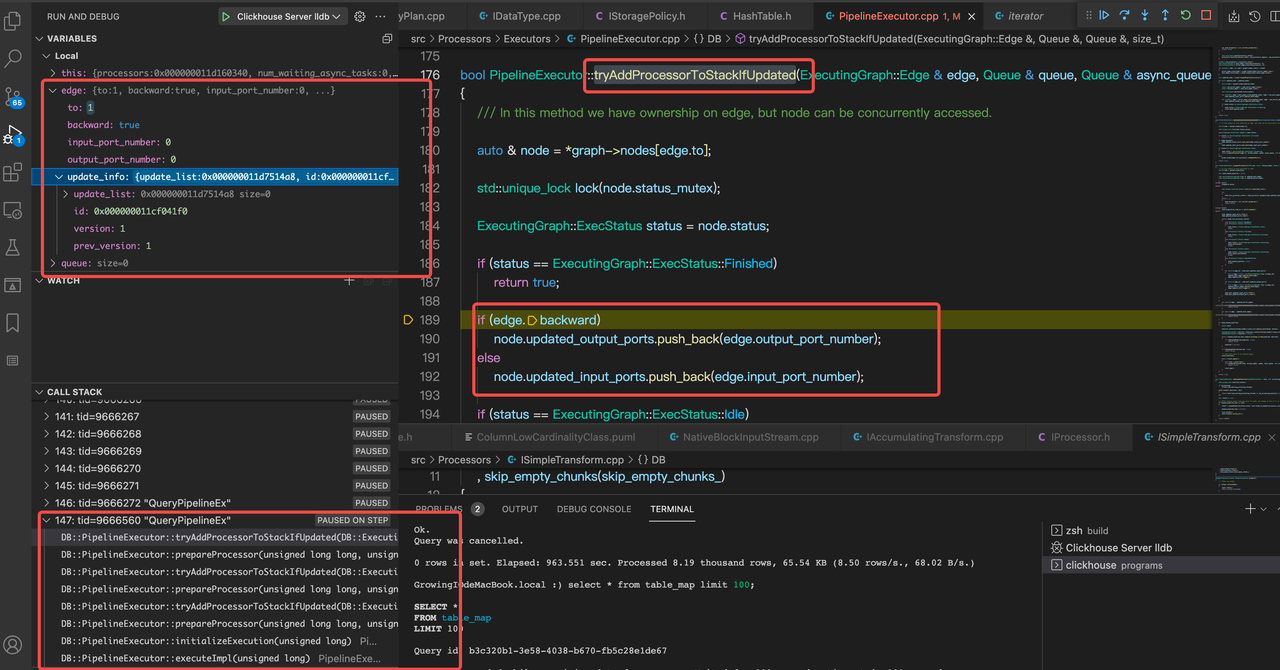
如图所示,如果是backward为true,那么当前端口就是InputPort, 下一个节点Port是OutputPort。共同组成edge (InputPort <---- OutpurtPort).
Private question.
代码分析
// tryAddProcessorToStackIfUpdated.
// 通过edge.to得到关联节点,并做初始化
auto & node = *graph->nodes[edge.to];
std::unique_lock lock(node.status_mutex);
ExecutingGraph::ExecStatus status = node.status;
if (status == ExecutingGraph::ExecStatus::Finished)
return true;
// 如果当前边的方向是backward,那么将edge中相应的port number添加到updated_output_ports中
if (edge.backward)
node.updated_output_ports.push_back(edge.output_port_number);
else
node.updated_input_ports.push_back(edge.input_port_number);
if (status == ExecutingGraph::ExecStatus::Idle)
{
node.status = ExecutingGraph::ExecStatus::Preparing;
// 这里调用prepareProcessor是PipelineExecutor.
return prepareProcessor(edge.to, thread_number, queue, async_queue, std::move(lock));
}
如何从Node中得到 下一个需要处理的edge.
// 当执行完 当前node.processor的prepare方法以后,我们就得到了下一个edge. node.last_processor_status = node.processor->prepare(node.updated_input_ports, node.updated_output_ports);
Port.h中
// InPort.setNeeded(). 如字面意思,开始设置Node的Inport端口信息.而Port和Edge关心很紧密,
在Port中的UpdateInfo中存储的id就是与当前Port关联的edge的地址.
见下图
void ALWAYS_INLINE setNeeded()
{
assumeConnected();
if ((state->setFlags(State::IS_NEEDED, State::IS_NEEDED) & State::IS_NEEDED) == 0)
updateVersion();
}
void inline ALWAYS_INLINE updateVersion()
{
if (likely(update_info))
update_info->update();
}
};
void inline ALWAYS_INLINE update()
{
if (version == prev_version && update_list)
update_list->push_back(id);
++version;
}
update_info 中的 Id 是 edge的地址.
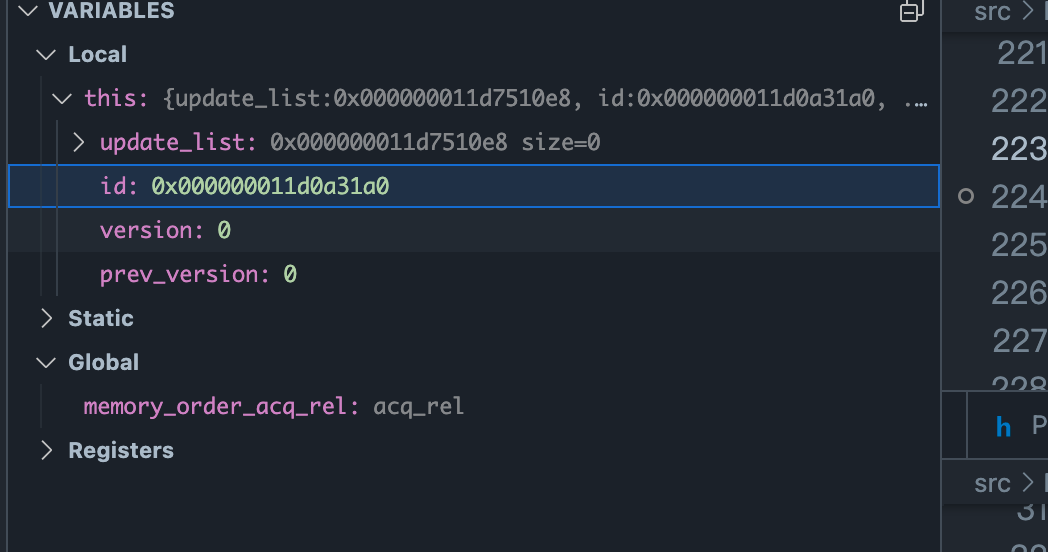
对应Graph Node中的back_edge中的update_info
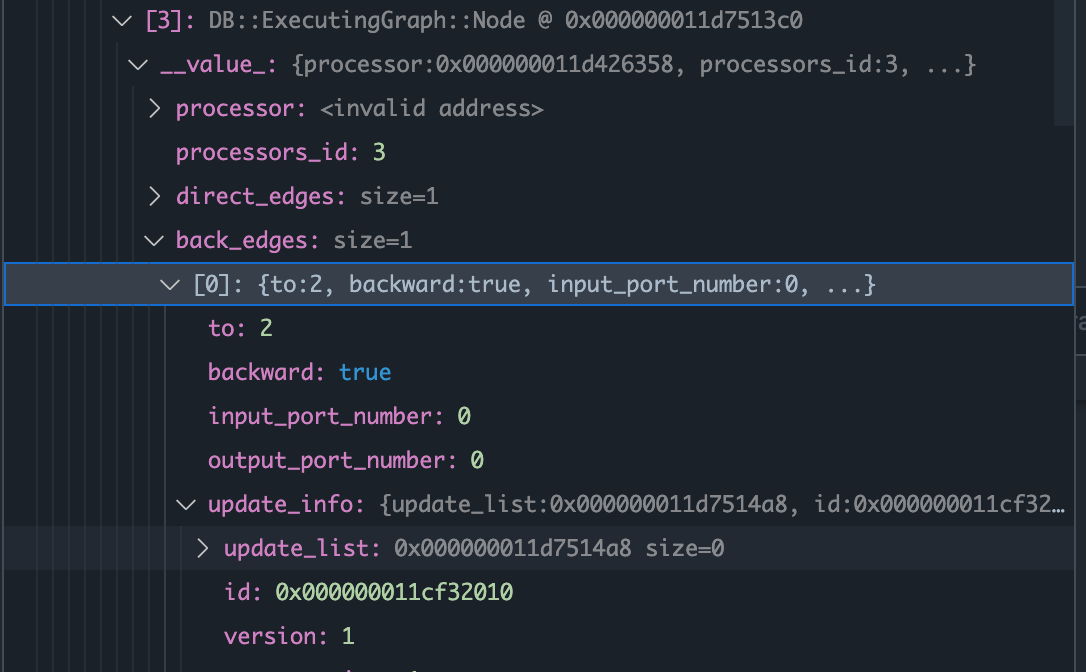
id 指向拥有这个update_info的edge.
ExecutingGraph::Edge & ExecutingGraph::addEdge(Edges & edges, Edge edge, const IProcessor * from, const IProcessor * to)
{
auto it = processors_map.find(to);
if (it == processors_map.end())
{
String msg = "Processor " + to->getName() + " was found as " + (edge.backward ? "input" : "output")
+ " for processor " + from->getName() + ", but not found in list of processors.";
throw Exception(msg, ErrorCodes::LOGICAL_ERROR);
}
edge.to = it->second;
auto & added_edge = edges.emplace_back(std::move(edge));
added_edge.update_info.id = &added_edge;
return added_edge;
}
Pipeline::prepareProcessor()作用
-
初始化所有相关的Processors/Nodes的状态
- 获取当前 node_x 的Inport, 初始化,通过当前 node_x InPort中的update_info结构中的id 得到edge_e 地址.
- 根据edge_e中的to字段(下一个Node的index),在graph中获得下一个node_y。
- 根据edge_e中的output_number信息对node_y进行初始化。
- 执行node_y中的processor.prepare()方法
- 如果能执行到 input.setNeeded(),那么就得到了下一批edges. 回到a.
- 如果执行MergeTreeSelector时,没有Input.setNeeded(). 此时,设置node.status为Ready,将此Node加入到Queue,并将此Node状态置为Executing,表明此Node已经可以被执行。
case IProcessor::Status::Ready:
{
node.status = ExecutingGraph::ExecStatus::Executing;
queue.push(&node);
break;
}
并且这个Node,没有需要更新的edge,所以就可以返回。
初始化Node结束,MergeTreeSelect对应的Node作为准备好的Node放到queue中,这些Node作为SQL执行开始的Task发送给task_queue给threads执行。
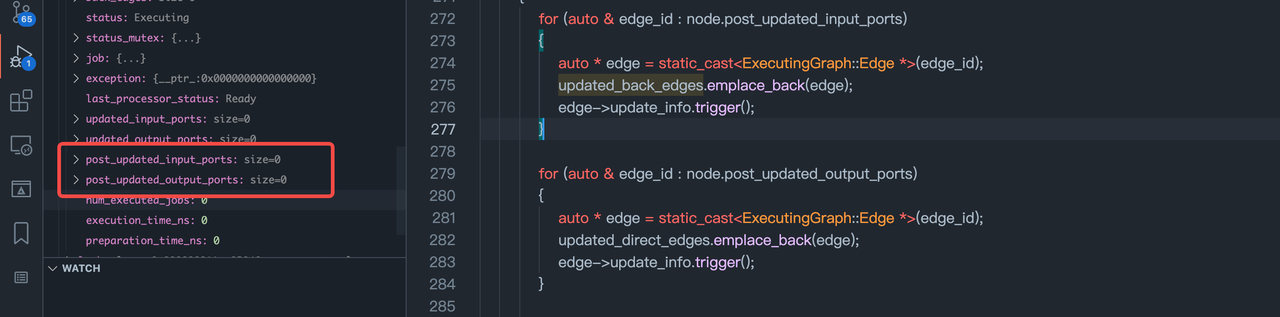
Processor的状态(会决定Node的状态)
enum class Status
{
/// Processor needs some data at its inputs to proceed.
/// You need to run another processor to generate required input and then call 'prepare' again.
NeedData,
/// Processor cannot proceed because output port is full or not isNeeded().
/// You need to transfer data from output port to the input port of another processor and then call 'prepare' again.
PortFull,
/// All work is done (all data is processed or all output are closed), nothing more to do.
Finished,
/// No one needs data on output ports.
/// Unneeded,
/// You may call 'work' method and processor will do some work synchronously.
Ready,
/// You may call 'schedule' method and processor will return descriptor.
/// You need to poll this descriptor and call work() afterwards.
Async,
/// Processor wants to add other processors to pipeline.
/// New processors must be obtained by expandPipeline() call.
ExpandPipeline,
};
参与执行的所有Node是不是都会进入Executing状态?
不是,只有正常执行,且实现了work()方法的Node,会从Preparing状态->Executing状态,然后交给 queue,再去执行。
Excute Graph Node更新结束
状态图 :
MergeTreeSelector [status: Executing, last_processor_status: Ready]
OtherSelectors [status: Idle, last_processor_status: NeedData]
总结
为什么需要构建ExecuteGraph?
个人理解就是为了完成一个class单独完成自己的事情。
Execute Graph 本质就是包含了Processor,有状态,可以被调度执行的Graph。
Pipeline是解决数据通过端口流通的结构,本身并不关心如何被调度执行。
准备Pipeline执行时,有一个Node失败,会很快返回。
1. MergeTreeSelector的状态 从Executing -> PortFull.
2.根据写的DFS规则,更新并添加相关节点. MergeTreeSelector只有direct_edge.
MergeTreeSelector [status: Executing, last_processor_status: Ready]
OtherSelectors [status: Idle, last_processor_status: NeedData]
queue中保留状态为Executing状态Node.
// 将Executing Node 放入到 task_queue中相应的thread需要处理的task queue中.
// task_queue: std::vector[[std::queue[Task*]],[std::queue[Task*]]], Task 模板类型,可以是Node.
task_queue.push(queue.front(), next_thread);
2. initializeExecution结束,
executeStepImpl()开始执行
//直到finished或者 yield.
while(!finished && !yield){
/// 准备
/// First, find any processor to execute.
/// Just traverse graph and prepare any processor.
while (!finished && node != nullptr){
...
// 从task_queue某个thread的Task队列中移出Task(node)
node = task_queue.pop(thread_num);
// 如果是1个并行度,那么就在当前线程中执行.
// 下面代码是指有多个Node并行执行是,会唤醒threads_queue中的其他线程一起执行。
if (node)
{
if (!task_queue.empty() && !threads_queue.empty()){
auto thread_to_wake = task_queue.getAnyThreadWithTasks()
...
}
}
}
执行
while (node && !yield){
// 当前线程执行Node任务
addJob(node);
...
// 最终调用Processor中的 work()方法处理.
node->job();
/// Try to execute neighbour processor.
{
/// Prepare processor after execution.
/// 找下个可以执行的Processors.
/// 如果有合适状态的Node(Executing状态),添加到queue队列,如果没有,结束任务.
{
auto lock = std::unique_lock<std::mutex>(node->status_mutex);
if (!prepareProcessor(node->processors_id, thread_num, queue, async_queue, std::move(lock)))
finish();
}
/// 执行下一批可以执行的Processors.
/// 将除queue中的第一个task之外的所有的任务搬运到task_queue,多线程执行这些Task.
/// 其中多线程模型中各个线程都会执行 executeSingleThread(thread_num, num_threads).
/// 单线程中executeSingleThread(0,1)只是一个特例
while (!queue.empty() && !finished)
{
task_queue.push(queue.front(), thread_num);
queue.pop();
}
}
}
}
执行结束后,监测各个Node中是否有exception.
/// Execution can be stopped because of exception. Check and rethrow if any.
for (auto & node : graph->nodes)
if (node->exception)
std::rethrow_exception(node->exception);
Pipeline 执行
生产者/消费者模型
生产: 执行过程中如果ExecutingGraph的Node可以变为Executing,那么就可以被放进task_queue (此时开始执行时,是沿着direct_edge 执行,数据流动方向)。
消费: 被创建的线程池消费,最终调用IProcessor中的work()方法。然后更新相邻的Node的状态,再次产生Executing 状态的Node。 一直到所有Node状态变成Finished状态,或者出现异常。
伪代码式分析
queue中保留状态为Executing状态Node.
// 将Executing Node 放入到 task_queue中相应的thread需要处理的task queue中.
// task_queue: std::vector[[std::queue[Task*]],[std::queue[Task*]]], Task 模板类型,可以是Node.
task_queue.push(queue.front(), next_thread);
initializeExecution结束,
executeStepImpl()开始执行
//直到finished或者 yield.
while(!finished && !yield){
/// 准备
/// First, find any processor to execute.
/// Just traverse graph and prepare any processor.
while (!finished && node != nullptr){
...
// 从task_queue某个thread的Task队列中移出Task(node)
node = task_queue.pop(thread_num);
// 如果是1个并行度,那么就在当前线程中执行.
// 下面代码是指有多个Node并行执行是,会唤醒threads_queue中的其他线程一起执行。
if (node)
{
if (!task_queue.empty() && !threads_queue.empty()){
auto thread_to_wake = task_queue.getAnyThreadWithTasks()
...
}
}
}
执行
while (node && !yield){
// 当前线程执行Node任务
addJob(node);
...
// 最终调用Processor中的 work()方法处理.
node->job();
/// Try to execute neighbour processor.
{
/// Prepare processor after execution.
/// 找下个可以执行的Processors.
/// 如果有合适状态的Node(Executing状态),添加到queue队列,如果没有,结束任务.
{
auto lock = std::unique_lock<std::mutex>(node->status_mutex);
if (!prepareProcessor(node->processors_id, thread_num, queue, async_queue, std::move(lock)))
finish();
}
/// 执行下一批可以执行的Processors.
/// 将除queue中的第一个task之外的所有的任务搬运到task_queue,多线程执行这些Task.
/// 其中多线程模型中各个线程都会执行 executeSingleThread(thread_num, num_threads).
/// 单线程中executeSingleThread(0,1)只是一个特例
while (!queue.empty() && !finished)
{
task_queue.push(queue.front(), thread_num);
queue.pop();
}
}
}
}
执行结束后,监测各个Node中是否有exception.
/// Execution can be stopped because of exception. Check and rethrow if any.
for (auto & node : graph->nodes)
if (node->exception)
std::rethrow_exception(node->exception);
queue中保留状态为Executing状态Node.
// 将Executing Node 放入到 task_queue中相应的thread需要处理的task queue中.
// task_queue: std::vector[[std::queue[Task*]],[std::queue[Task*]]], Task 模板类型,可以是Node.
task_queue.push(queue.front(), next_thread);
2. initializeExecution结束,
executeStepImpl()开始执行
//直到finished或者 yield.
while(!finished && !yield){
/// 准备
/// First, find any processor to execute.
/// Just traverse graph and prepare any processor.
while (!finished && node != nullptr){
...
// 从task_queue某个thread的Task队列中移出Task(node)
node = task_queue.pop(thread_num);
// 如果是1个并行度,那么就在当前线程中执行.
// 下面代码是指有多个Node并行执行是,会唤醒threads_queue中的其他线程一起执行。
if (node)
{
if (!task_queue.empty() && !threads_queue.empty()){
auto thread_to_wake = task_queue.getAnyThreadWithTasks()
...
}
}
}
执行
while (node && !yield){
// 当前线程执行Node任务
addJob(node);
...
// 最终调用Processor中的 work()方法处理.
node->job();
/// Try to execute neighbour processor.
{
/// Prepare processor after execution.
/// 找下个可以执行的Processors.
/// 如果有合适状态的Node(Executing状态),添加到queue队列,如果没有,结束任务.
{
auto lock = std::unique_lock<std::mutex>(node->status_mutex);
if (!prepareProcessor(node->processors_id, thread_num, queue, async_queue, std::move(lock)))
finish();
}
/// 执行下一批可以执行的Processors.
/// 将除queue中的第一个task之外的所有的任务搬运到task_queue,多线程执行这些Task.
/// 其中多线程模型中各个
Private Question
如果某个pipeline出现异常excpetion,提前结束,如何通知其他pipeline的执行者终止执行?
很多继承IProcessor的类,并没有实现cancel方法。推测不会生效
// 如果某个node在执行时,出现异常那么就会通知所有的Processors停止执行。
//
if (node->exception)
cancel();
// 这里发生运行时异常时,会调用所有processor的cancel()方法,
// 有些processor没有实现这个方法。可以调用IProcessor的cancel().
void PipelineExecutor::cancel()
{
cancelled = true;
finish();
// 这里的processors是PipelineExecutor中的变量,包含所有processors。
std::lock_guard guard(processors_mutex);
for (auto & processor : processors)
processor->cancel();
}
继承Processor的Transform的work()方法调用是否从task_queue出队后执行的? 是的
Executing Graph Node沿着 direct_edge方向运行?
首先执行MergeTreeSelector(Ready 状态).
/src/Processors/ISource.cpp
数据和状态变化是同步的.
output.pushData(std::move(current_chunk));
边执行Node边添加?
这种算法有两种倾向:
1. 尽可能先处理Direct方向的edge,因为data被消费出Pipeline后,才能使MergeTreeSelector Processor pull 数据进Pipeline
2.DFS
PipelineExecutor::prepareProcessor(){
...
node.last_processor_status = node.processor->prepare(node.updated_input_ports, node.updated_output_ports);
// DFS 过程中仅当node.last_processor_status为Ready才会被放入执行队列.
switch (node.last_processor_status)
{
...
case IProcessor::Status::Ready:
{
node.status = ExecutingGraph::ExecStatus::Executing;
queue.push(&node);
break;
}
...
}
...
// 尽可能从direct 方向进行DFS搜索。
for (auto & edge : updated_direct_edges)
{
if (!tryAddProcessorToStackIfUpdated(*edge, queue, async_queue, thread_number))
return false;
}
// 反向DFS初始化
for (auto & edge : updated_back_edges)
{
if (!tryAddProcessorToStackIfUpdated(*edge, queue, async_queue, thread_number))
return false;
}
}
// 仅当与此edge连接的Node状态Idle才会继续DFS,其他情况作为剪枝情况,停止DFS.
tryAddProcessorToStackIfUpdated() {
if (status == ExecutingGraph::ExecStatus::Idle)
{
node.status = ExecutingGraph::ExecStatus::Preparing;
return prepareProcessor(edge.to, thread_number, queue, async_queue, std::move(lock));
}
分析沿着direct_edge和back_edge 进行DFS遍历Node 不会死循环.
1.调用LimitTransform到node id 是1的时候, 节点的last_processor_status从 NeedData --> Finished。因为LimitTransform 得到了超过limit 为1的rows.所以状态可以变为结束.
1.1 LimitTransform 此时outport和inport都被更新,direct_edge和backward_edge方向的Node都需要被更新.由于DFS,会沿着direct_edge方形更新下一个节点ISimpleTransform Node.
// 当前Node(LimitTransform) 是接收 MergeTreeSelector输出的节点。
// 因为MergeTreeSelector 和 当前节点Data是指向同一个数据.
// 在后面两个循环对数据进行了依次转移。此方法没有重写 IProcessor的work()方法。
// prepare 时就完成了数据的处理。主要是对limit进行限制。
// process_pair()->preparePair()-> LimitTransform::splitChunk(PortsData & data),
//对已有数据在当前Transform进行进行组装.
for (auto pos : updated_input_ports)
process_pair(pos);
for (auto pos : updated_output_ports)
process_pair(pos);
/// If we reached limit for some port, then close others. Otherwise some sources may infinitely read data.
/// Example: SELECT * FROM system.numbers_mt WHERE number = 1000000 LIMIT 1
if ((!limit_is_unreachable && rows_read >= offset + limit)
&& !previous_row_chunk && !always_read_till_end)
{
for (auto & input : inputs)
input.close();
//
for (auto & output : outputs)
output.finish();
return Status::Finished;
}

2.ISimpleTransform 会将LimitTransform通过outport设置的数据,通过自己的inport处理. last_processor_status: NeedData->Ready. (这里没有设置post_updated_out_ports原因是,这个Transform有work()方法,只有通过work()方法处理才能将inport中的数据转移到outport中。)所以这里会将该Node放到queue上去执行。(这里不会沿着direct_edg 一直更新下去Node)
case IProcessor::Status::Ready:
{
node.status = ExecutingGraph::ExecStatus::Executing;
queue.push(&node);
break;
}
3.继续更新LimitTransform back_edge方向的Node.因为只有一个MergeTreeSelector。 ?这样会陷入死循环而使ISimpleTransform没有办法执行么? 从LimitTransform 更新到 MergeTreeSelector,然后MergeTreeSelector通过direct_edge又更新回来?不会,因为LimitTransform 在拿到limit (本次测试limit 是 1) 的数据时,会对和它公用的Data数据进行状态更新,更新为State::IS_FINISHED.这样就整体结束了。
- 执行完所有和LimitTransform Node相关的Node状态,开始执行加入到queue中的ISimpleTransform. 同样也是按照direct_edge方向执行.直到所有节点都到Finished状态或者出现异常。
- expand_pipeline目前没有接触到.
参考
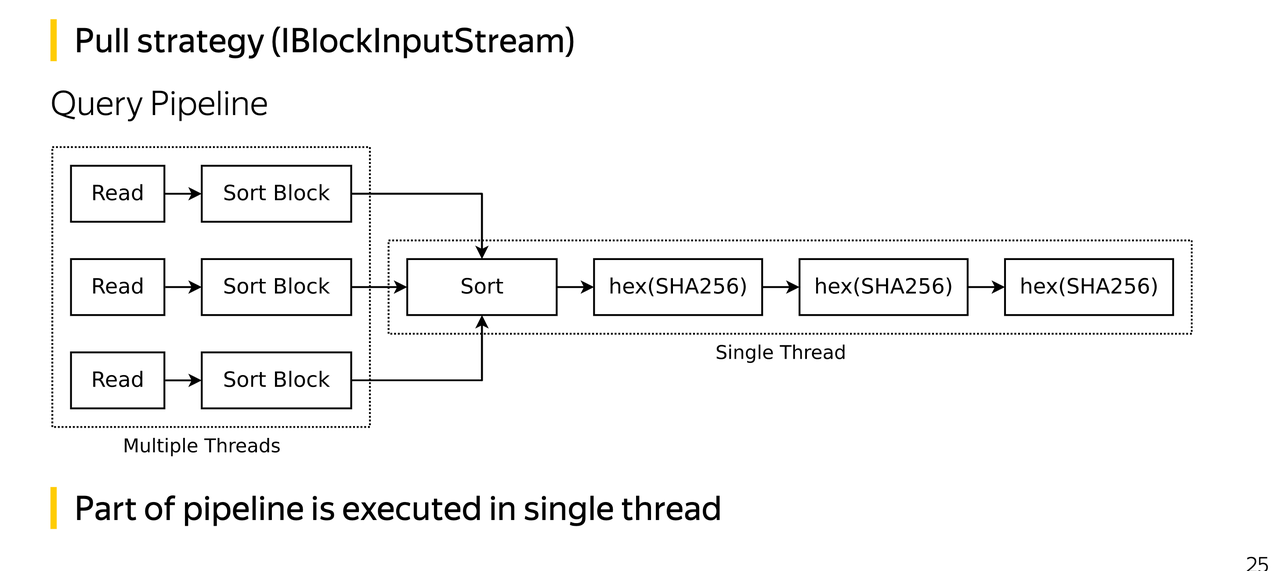
使用分治方法。

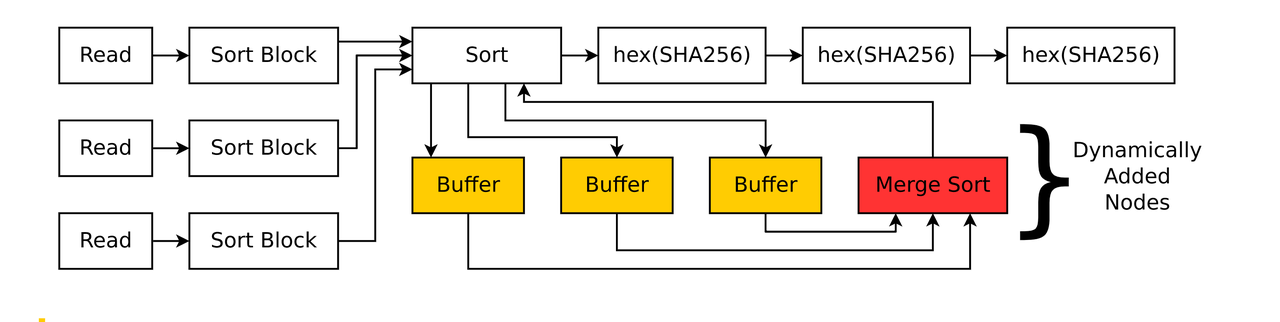
执行收尾时检查否有异常(异常保存在node中).
/// Execution can be stopped because of exception. Check and rethrow if any.
for (auto & node : graph->nodes)
if (node->exception)
std::rethrow_exception(node->exception);
一些总结
- Processor的执行方式上有两种,一种是实现了work()方法的Processor,这种Node需要加入到queue中执行。另一种,没有work方法,在prepare此Node时,就等价于对Node进行了处理。
比如 LimitTransform 是没有实现work()方法的,那么它的数据从(inport->outport)流动是在prepare时 就完成了。 但是IsimpleTransform 实现了work()方法,说明处理inport的数据然后输出到outport 可能比较复杂,需要 发送到queue中,然后通过专门调用addJob(), job->work()单独处理这个任务。
- 针对Processor的状态更新,使用DFS算法,先direct_edge方向,back_edge方向更新🔗Node的对应状态。
- 当Node更新某个端口数据时,会同时影响共有数据的State中的状态。例如
当LimitTransform 设置为Finished时,会更新inport中的Data的状态,会影响到MergeTreeSelector outport的状态。 auto flags = state->setFlags(State::IS_FINISHED, State::IS_FINISHED);
- 在更新Node节点状态时,有加锁动作.
std::unique_lock lock(node.status_mutex);
- 执行Execution Graph 的架构
主线程 与 执行线程 解耦, 通过 LazyOutputFormat中的 Queue(非全局变量)进行通信.
Pipeline 执行 结束
执行Pipeline 总体模型
执行在TCPHandler 类发起.
发起者执行的逻辑,创建异步线程绑定到需要输出的data上.
这个data就是PullingAsyncPipelineExecutor和异步执行线程需要通信的"全局变量"。
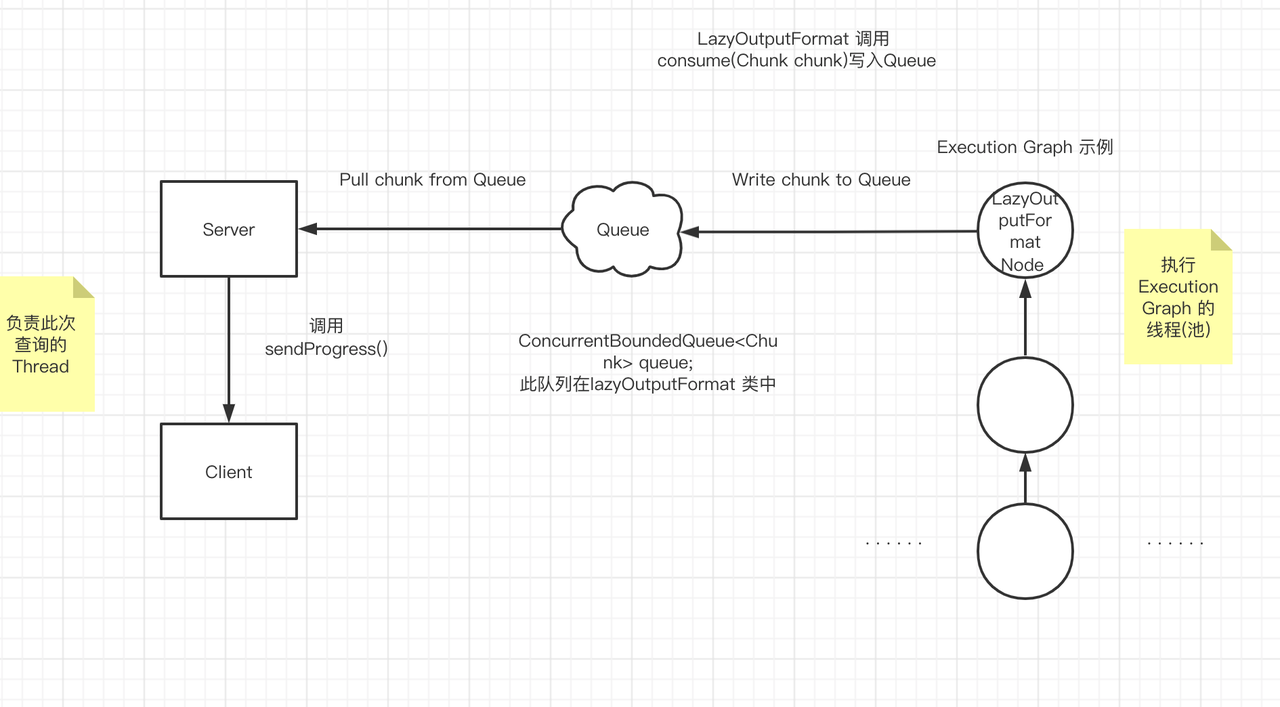
多threads Execute Graph调度执行 分析
- 如果有两个Node(比如max_threads也是2,),那么在PipelineExecutor中如何协同线程工作的。
首先PipelineExecutor会创建max_threads的线程以及一个存放Tasks的数据结构.
queue: vector<std::deque<Task *>> // 先入先出的队列,存放需要执行的Node的结构
[ [NodePtr0, NodePtr1, NodePtr2, ...] ]
[ [NodePtr0, NodePtr1, NodePtr2, ...] ]
....
[ [NodePtr0, NodePtr1, NodePtr2, ...] ]
1.任意thread_i都可以看到这些需要被执行的task.
2.每个 thread_i 会绑定 到 一个ExecutorContext_i,并wait ExecutorContext_i中的wake_flag, 有task_queue被更新。
3.当某个thread_i 执行扫描可运行的Node时,会将对应的task (node) push到
task_queue[thread_j](j可以不等于i) 队列,(同时将node从当前queue中出队)中,并set wake_flag,让这个线程thread_j去干活。
4.这保证了pipeline找那个处于Executing状态的Node可以充分运行。
threads: 模拟线程
std::vector<std::unique_ptr<ExecutorContext>> executor_contexts;
/***
/// Context for each thread.
struct ExecutorContext
{
/// Will store context for all expand pipeline tasks (it's easy and we don't expect many).
/// This can be solved by using atomic shard ptr.
std::list<ExpandPipelineTask> task_list;
std::queue<ExecutingGraph::Node *> async_tasks;
std::atomic_bool has_async_tasks = false;
std::condition_variable condvar;
std::mutex mutex;
bool wake_flag = false;
/// Currently processing node.
ExecutingGraph::Node * node = nullptr;
/// Exception from executing thread itself.
std::exception_ptr exception;
#ifndef NDEBUG
/// Time for different processing stages.
UInt64 total_time_ns = 0;
UInt64 execution_time_ns = 0;
UInt64 processing_time_ns = 0;
UInt64 wait_time_ns = 0;
#endif
};
***/
?怎么初始化,怎么使用?
// 初始化这些线程 (使用globalThread),并且每个thread名字都是 QueryPipelineEx.
// 初始化threads的函数是一个lambda表达式,其中capture了this指针.
for (size_t i = 0; i < num_threads; ++i)
{
threads.emplace_back([this, thread_group, thread_num = i, num_threads]
{
/// ThreadStatus thread_status;
setThreadName("QueryPipelineEx");
if (thread_group)
CurrentThread::attachTo(thread_group);
SCOPE_EXIT_SAFE(
if (thread_group)
CurrentThread::detachQueryIfNotDetached();
);
try
{
executeSingleThread(thread_num, num_threads);
}
catch (...)
{
/// In case of exception from executor itself, stop other threads.
finish();
executor_contexts[thread_num]->exception = std::current_exception();
}
});
}
线程的上下文 主要是功能是在保证在多个Node可以在多个线程执行时,保持一个Node在主线程执行之外,
其他的Node可以被其他thread执行。
这种模型还是很好的。
个人疑问? max_threads为什么会在两个MergeTreeSelector时为1.
max_threads 会在某处被设置.

settings.max_block_size // default = 65505 bytes.
// 如果 SQL 中的LIMIT 和 OFFSET 常量 的和 小于 max_block_size,那么 会影响ExecuteGraph的并行度。
if (!query.distinct
&& !query.limit_with_ties
&& !query.prewhere()
&& !query.where()
&& !query.groupBy()
&& !query.having()
&& !query.orderBy()
&& !query.limitBy()
&& query.limitLength()
&& !query_analyzer->hasAggregation()
&& !query_analyzer->hasWindow()
&& limit_length <= std::numeric_limits<UInt64>::max() - limit_offset
&& limit_length + limit_offset < max_block_size)
{
max_block_size = std::max(UInt64(1), limit_length + limit_offset);
max_threads_execute_query = max_streams = 1;
}

由于测试select 语句中offset数量太小,导致虽然有两个ReadFromMergeTreeSelector,仍然是1个线程在执行。
个人疑问? 执行因超时Cancelling 如何中断PipelineExecutor执行, cancelled 是做这个使用的么? Cancelled。
当执行 processOrdinaryQueryWithProcessors()时,会piplineExecutor 会调用pull()方法。
每隔100ms 会判断是否用户发送过来 cancel query的命令。如果有
当执行 processOrdinaryQueryWithProcessors()时,会piplineExecutor 会调用pull()方法。
每隔100ms 会判断是否用户发送过来 cancel query的命令。如果有
while (executor.pull(block, interactive_delay / 1000))
{
std::lock_guard lock(task_callback_mutex);
if (isQueryCancelled())
{
/// A packet was received requesting to stop execution of the request.
executor.cancel();
break;
}
最终调用PipelineExecutor::cancel() 设置Pipeline::atomic_bool 类型为true.
实验时没有看到对应的pipeline被打断执行,(sql 被cancel还是会被执行到底)。
最终调用PipelineExecutor::cancel() 设置Pipeline::atomic_bool 类型为true.
实验时没有看到对应的pipeline被打断执行,(sql 被cancel还是会被执行到底)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号