
Pyecharts某宝螺蛳粉销售数据可视化大屏
Pyecharts某宝螺蛳粉销售数据可视化大屏
1、数据大屏的呈现
2、文件结构
├─data_process │ ├─data_cleaning.py # 数据清洗 │ └─jieba_goods_and_comment_deal.py # 数据分词存数据库 │ ├─data_set │ ├─李子柒螺蛳粉评论.csv # 评论数据集 │ └─螺蛳粉店铺数据.csv # 商品数据集 │ ├─src # md文件的图 │ └─xmind.png │ ├─luosifen.sql # 数据库文件 │ └─visual_analysis │ └─visual_large_screen.py # 可视化大屏代码 │ └─html ├─chart_config.json # echarts生成的文件 ├─my_new_charts.html # echarts生成的文件 └─page.html # echarts生成的文件
3、引言
近年来,随着中国经济的迅速发展,电子商务行业也随之蓬勃发展。作为电子商务的领军企业,某宝已经成为了人们购物的主要渠道之一。其中,某宝螺蛳粉的销售是一个备受关注的话题。螺蛳粉是一种具有地方特色的湖南小吃,以其独特的口感和香味,在某宝平台上赢得了众多消费者的喜爱和追捧。
本研究旨在探究某宝螺蛳粉销售的现状,为某宝平台上的消费者提供有价值的参考信息。选取销量最高的几款商品的评论来进行数据分析和可视化处理,帮助大家有目的的去选择螺蛳粉,同时分析螺蛳粉的某宝搜索关键字词频,寻找出适合提高搜索范围的关键词,分析地区销售量并进行可视化。
下面是开始该项目前绘制的思维导图:
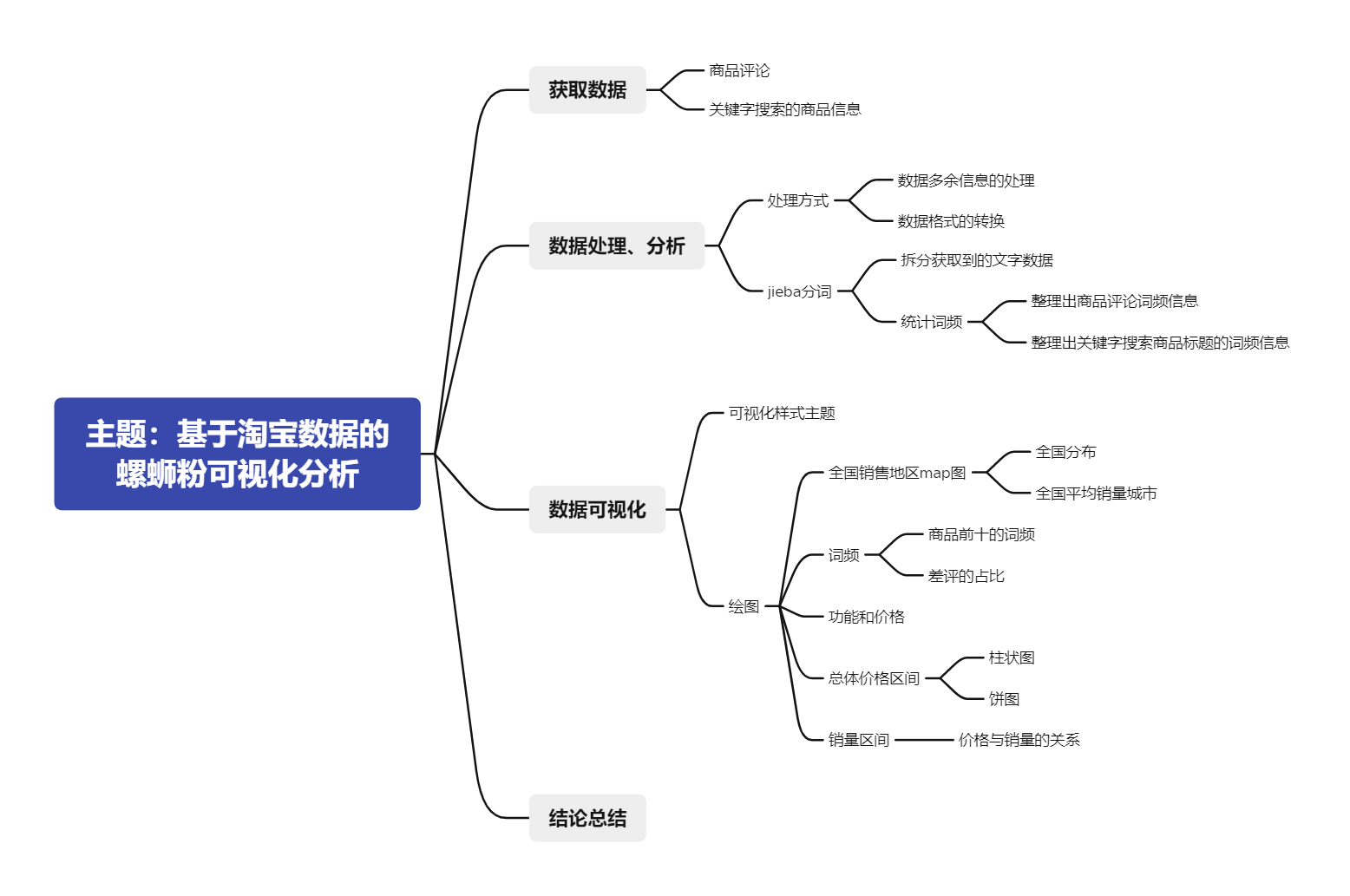
4、获取数据
一切的开始都是建立在数据之上,首要任务是获取数据。对于商品来说,能够展现其在市场的反响的数据,就是该商品的评论。
确定好了数据,接下来就要考虑如何获取数据。一页一页的复制粘贴肯定是不可能的,这里我选择使用爬虫爬取。
爬虫
俗话说:爬虫学的好,牢饭吃的早
爬虫可以快速爬取网站上的数据,并且架构十分简单。这里我使用的是request库。
因为某宝一直再更新反爬机制,所以不提供爬虫代码,只提供数据集
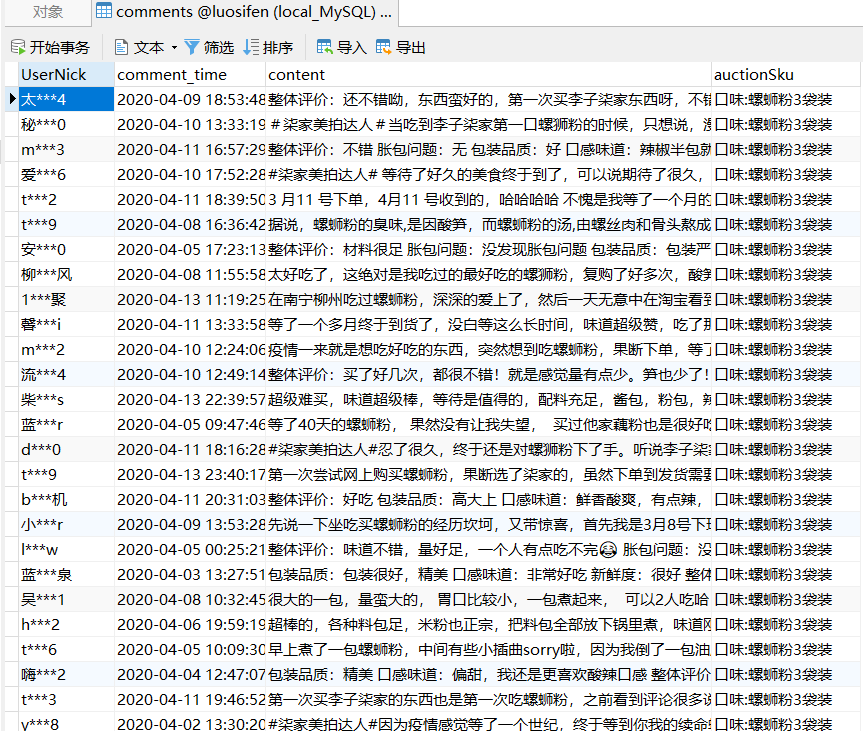
1、爬取商品追评
首先爬取商品的前100页追评,在试验阶段是想爬取1000页的,每页20条评论,这样就会有20000条评论。可是当开始爬取之后发现了问题。在大概100页之后的每一页追评数据都是一样的。考虑了两种情况:
-
某宝的反爬机制,不允许爬取更多的数据。(大概率是这种情况)
-
在100页后的数据不再更新,因为不会有人去浏览100页后的数据。
测试了许多次都是这样。所以们选取前100页、每件商品共计2000条的追评数据进行处理分析。
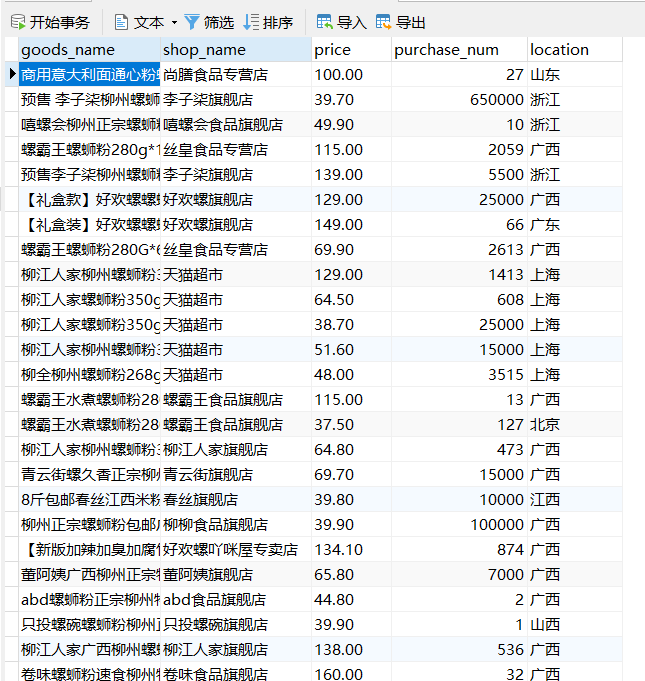
2、爬取商品信息
我们在某宝首页选取以“螺蛳粉”为关键字搜索,对搜索返回的页面信息进行数据爬取。

某宝反爬的解决
在爬取某宝的时候我经常被某宝的反爬机制给盾:
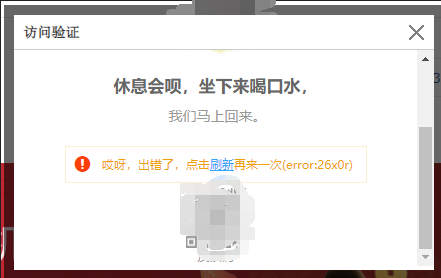
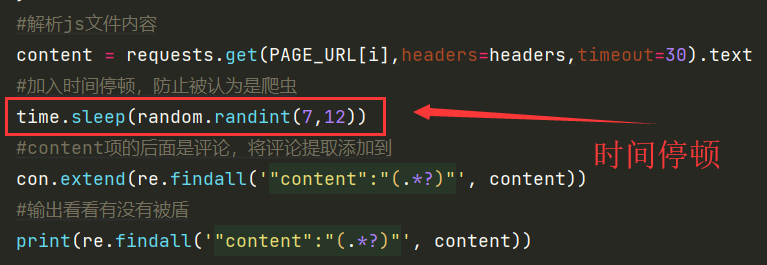
也尝试使用了IP池,但是网站上的免费IP基本都无法使用。在不停的试错中找到了一个很好的方法:sleep
在爬取的for循环中设置sleep函数,每请求爬取一次页面数据,就睡眠一段时间(测试下来7,12s之间,一次都没被盾)。这样可以让某宝认为你是人在访问,而不是爬虫,就不会出现滑块验证这种东西。
5、数据处理、构思
1、数据处理
获取数据过后,先简单的观察一下数据。对于商品的追评,没有什么需要注意的。但是关键字搜索爬取到的信息有点问题
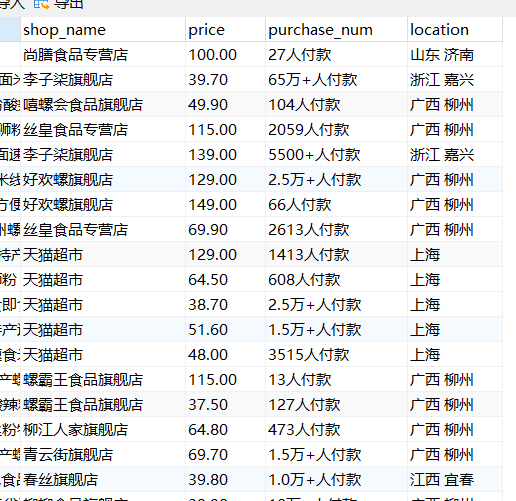
可以看到,地区后面跟有市级城市名称,付款人数不全是数字,还有汉字和符号。
- 考虑到后续需要绘制全国地图,需要的是省级地名,那么地区列中的市级城市名称就是需要省略的
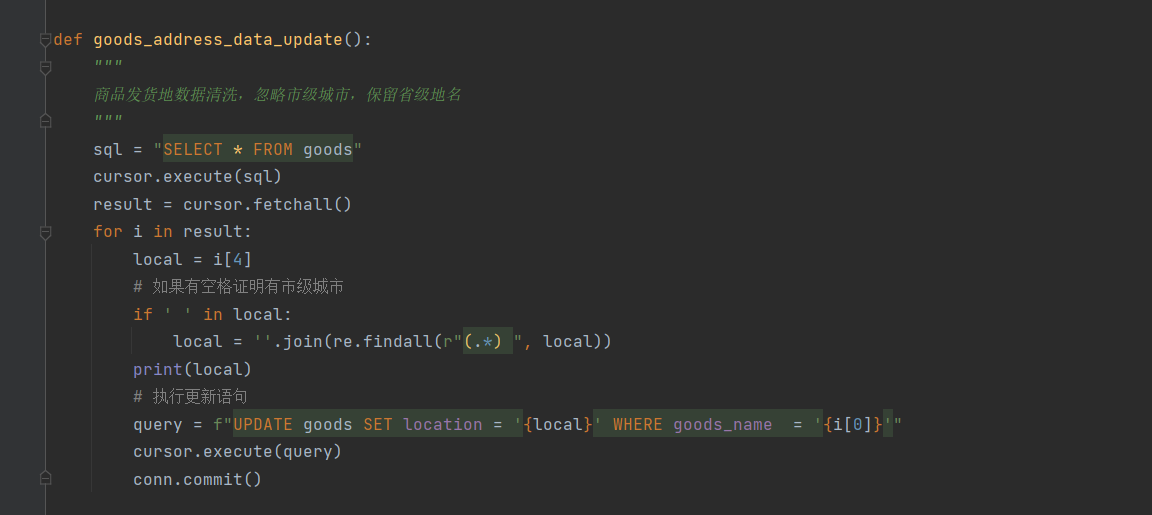
- 付款人数需要进行转变 例如:1.5万+人付款 ----> 15000
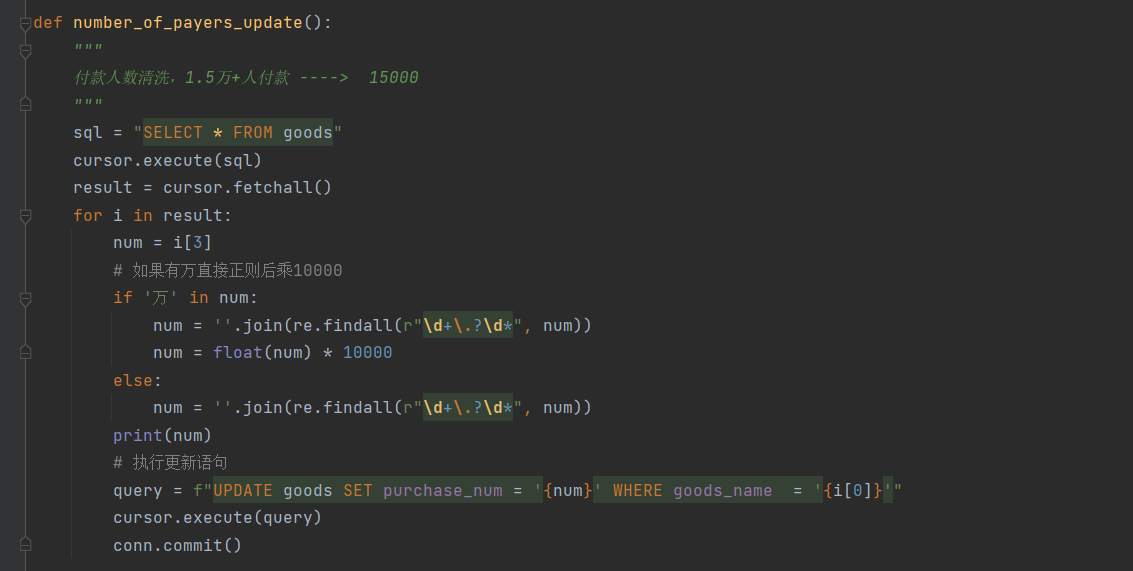
- 可能会出现大数吃小数的情况,但是由于无法获取到具体的销售量,这里选择忽略
结巴分词
这里用到一个很有意思的库:jieba库
它是用来拆词用的,将一句话拆成一个个词组,可以便于我们统计词频,从而分析我们爬取的评论
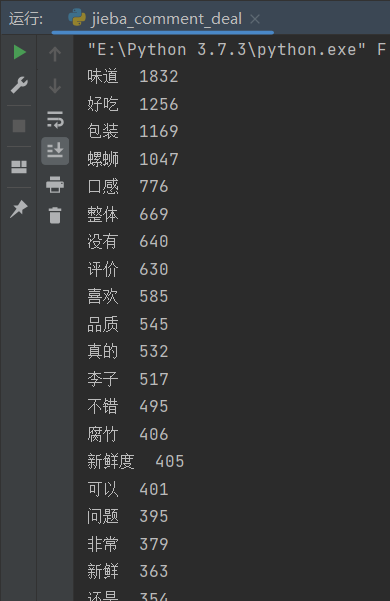
通过算法统计后,可以很清楚的知晓词频,知道了一些词的词频有助于我们判断这件商品是否不错。就像上图所示数据,在2000条数据中,”味道“的词频超过了1800条,如果每一条评论中出现一次,那么好评率将高达90%。但是这样计算我们也忽略了,是否有评论连续打10个味道?但是这也反映出顾客对商品的极度喜爱,所以我们选择保留。
2、数据构思
在处理完数据之后,我得到了商品的评论和搜索后的商品数据,当然这些都是通过结巴分词处理好的文件。
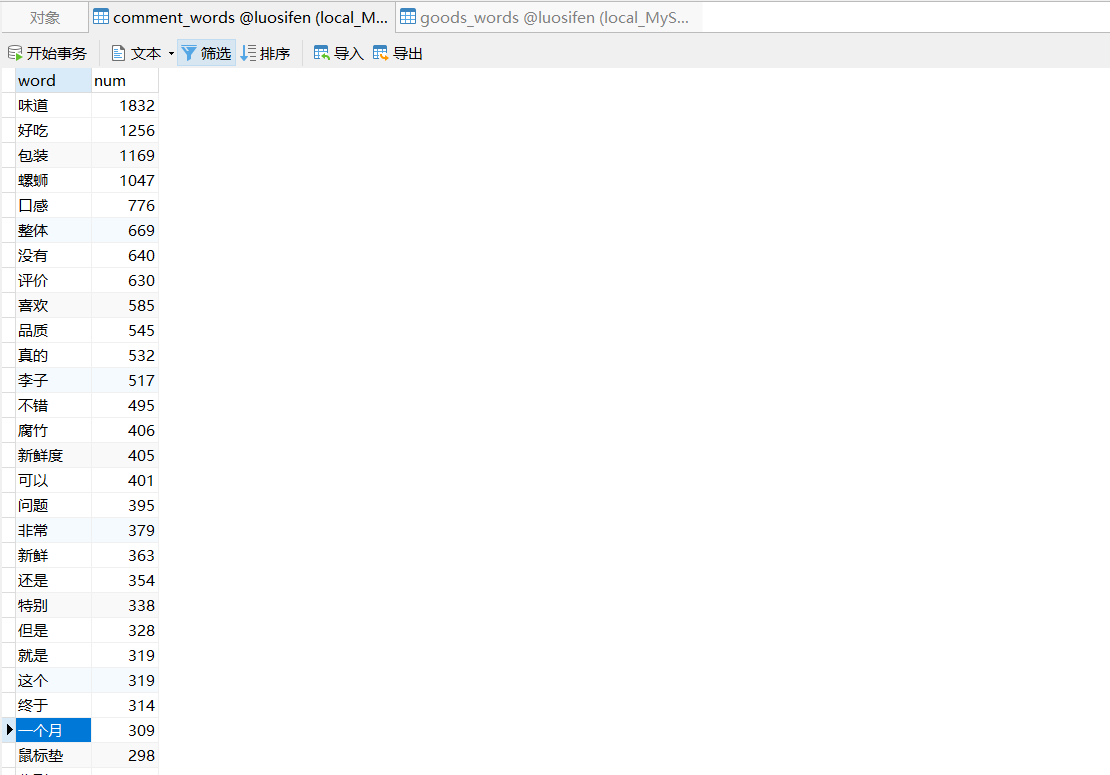
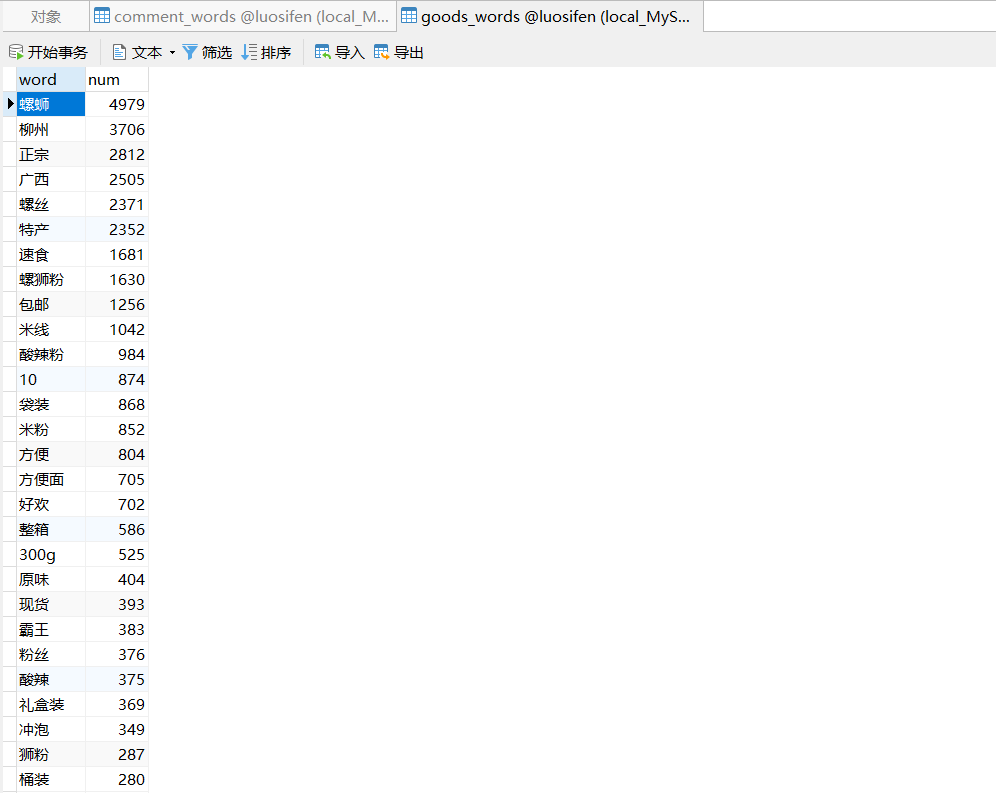
当然还有一份商品信息的数据
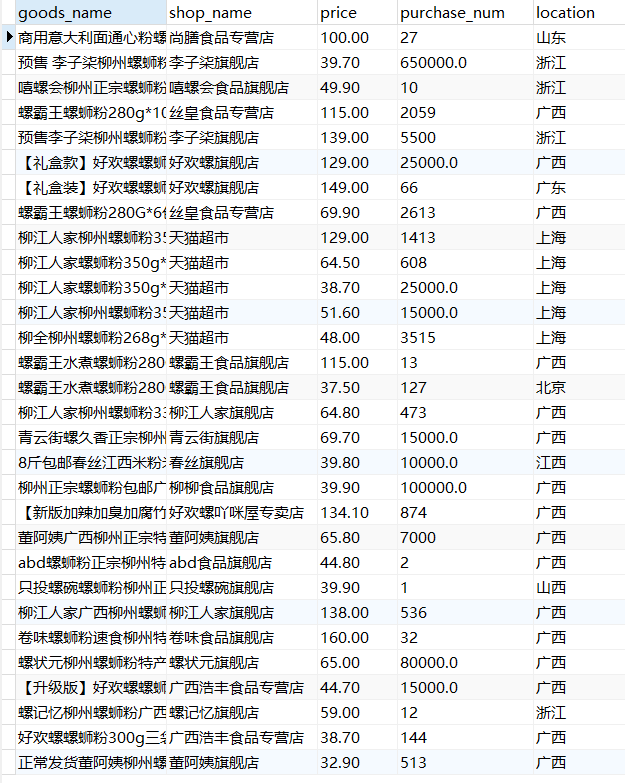
就这些数据而言,我需要可视化的情况有:全国销售商的销售量、每件商品前十的词频柱状图、价格区间、全国地区的商家数量、搜索关键词的各个词频。
有了这些构思,接下来就进行数据的可视化处理
6、数据可视化
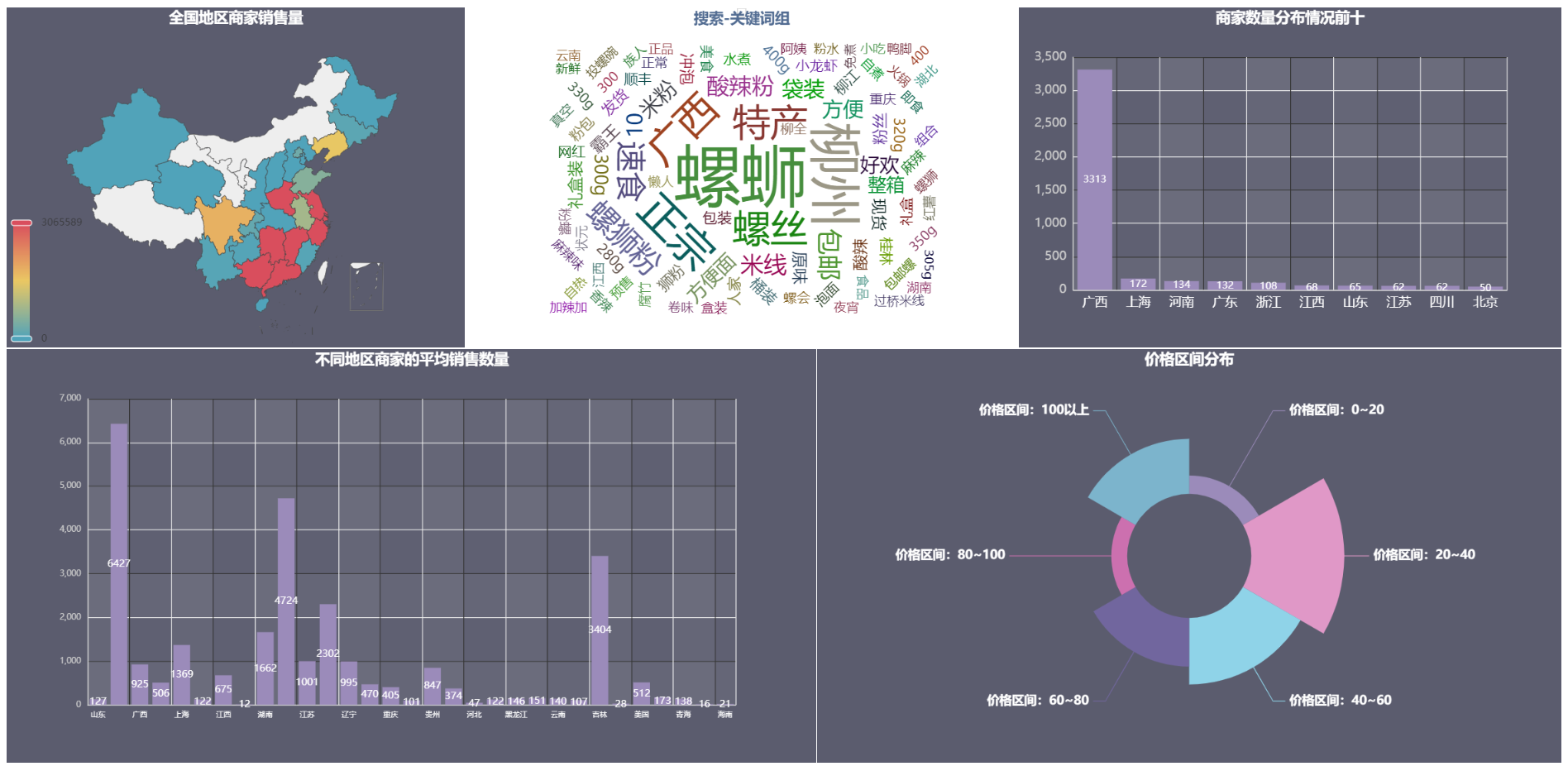
1、销售商销售量
选取不同地区销售商的销售量总和来绘制(PS:由于无法获取到全国地区的买家信息,我只能站在客户的角度对销售商进行分析)
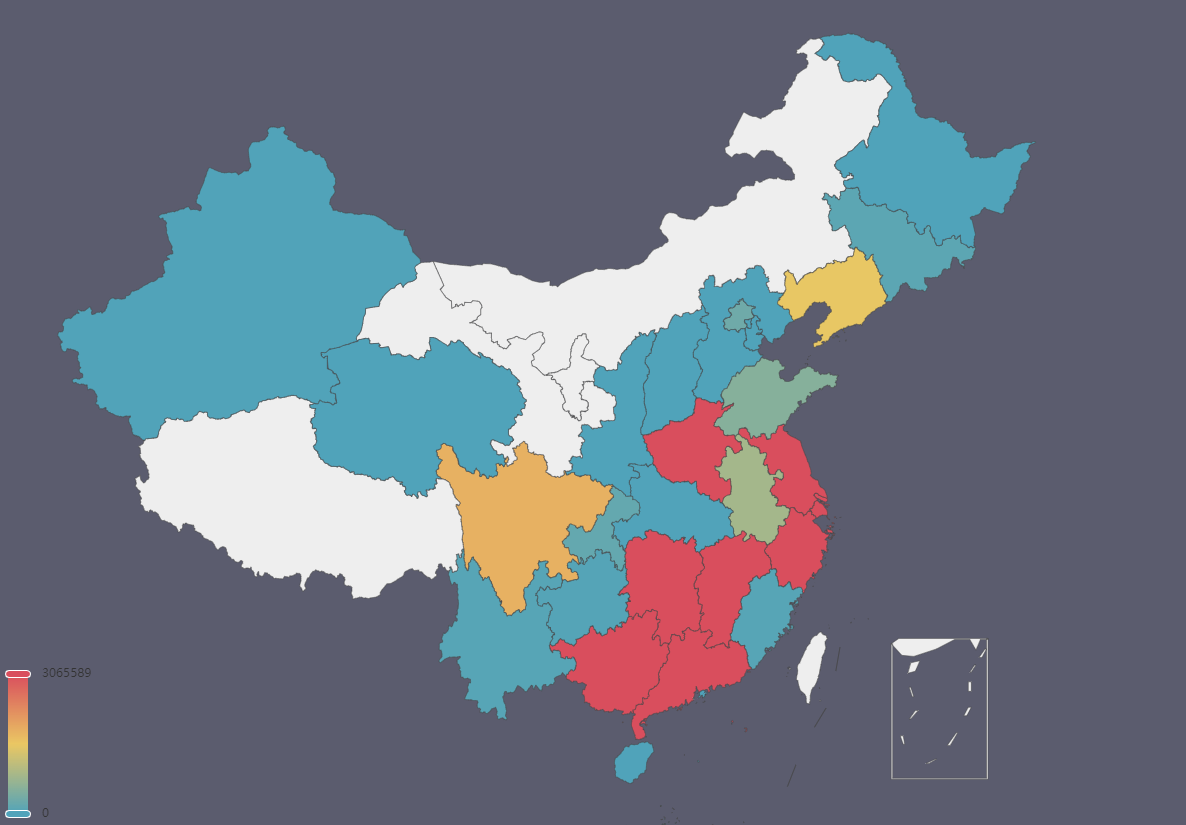
可以看到,沿海一带的商家销售量是最高的,所有的销售商都集中在中国的东南沿海方向,但是在西部和北部的销售商却寥寥无几,甚至没有。
2、价格区间分布
价格也是衡量一个商品销售量的重要指标,每当生产出一件商品,需要对市场的价格有所了解和分析才能确定销售价格,不然盲目的定价只会被市场的大流冲散。
这里我选用饼状玫瑰图进行绘制
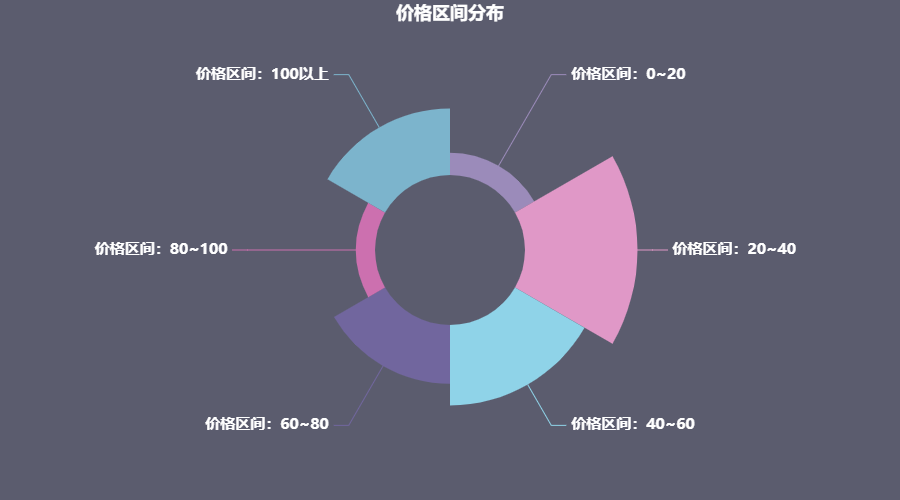
可以看到,在20~40区间的销售量是最高的,但同时我也发现,价格在100以上的也有不少的人数。考虑到现在螺蛳粉市场的普遍售价,100以上的应该是囤货。
3、商家分布
比较好奇哪里商家多,就画出来看看
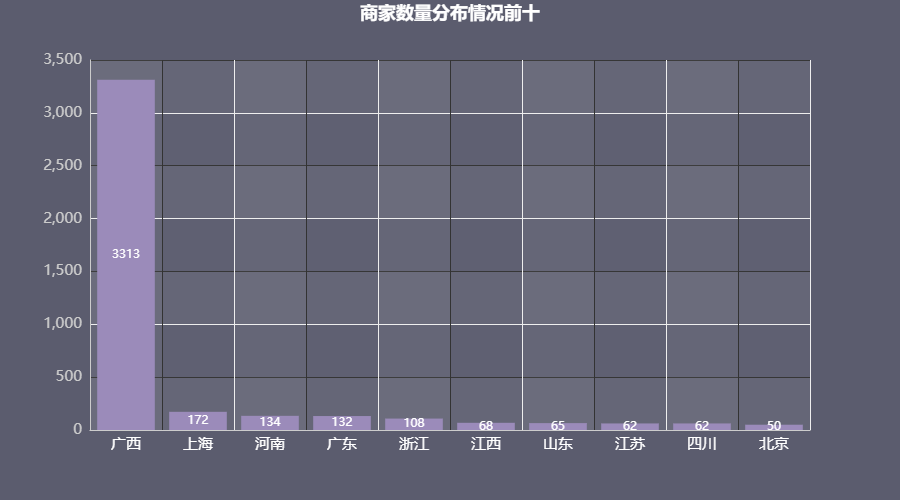
绘制完图形后发现一个问题,广西商家数量远远大于其他家,侧面证明广西老铁是螺蛳粉的忠实用户。
4、不同地区商家平均销售量
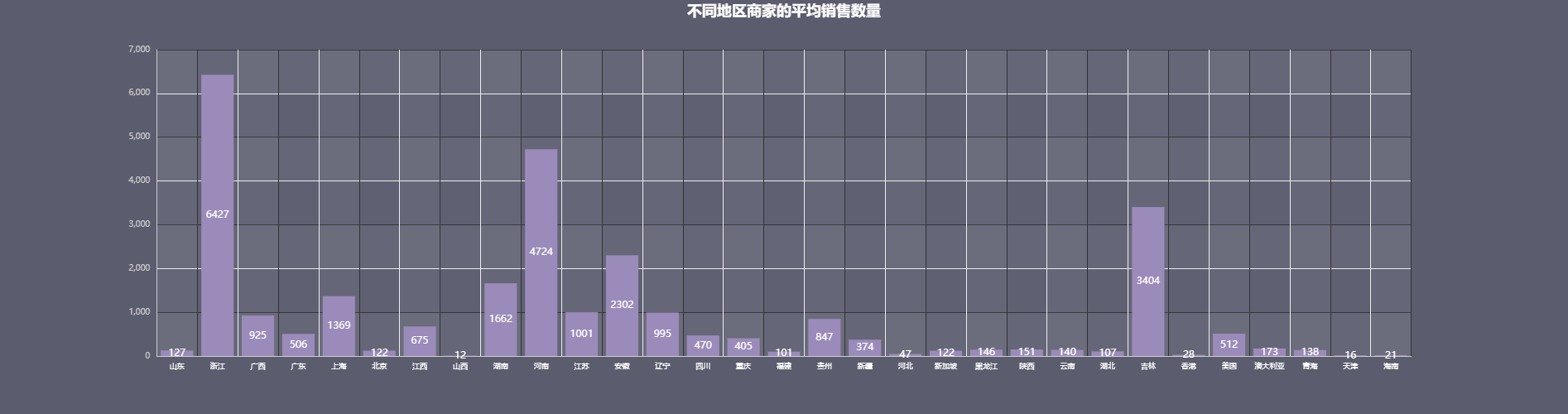
有意思的事情发生了,浙江名列榜首,其次是河南。广西的平均销售量连前三都没有碰到。而吉林勇夺了第三的宝座。
5、搜索关键词的词频
搜索商品后返回商品界面的呈现也是一门学问,如果你的商品信息包含了人们喜欢搜索的词组,那么被呈现在前面的概率就越高,你的商品就能以更高的曝光率呈现在顾客的视线里面。这里我选择使用词云图绘制

可以看到,螺狮、柳州、广西、正宗等是绝大多数产品所出现的关键词,同时一些新颖而且高频的词也呈现了出来,如特产、速食、方便、礼盒装。
7、源码下载
CSDN:某宝螺蛳粉销售数据可视化大屏(python+echarts)
Github:某宝螺蛳粉销售数据可视化大屏(麻烦各位看官点亮star)
8、号外
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “👍点赞” “✍️评论” “💙收藏” 一键三连哦!
【👇🏻👇🏻👇🏻关注我| 获取更多源码 | 定制源码】大学生毕设模板、期末大作业模板 、Echarts大数据可视化等! 「一起探讨 ,互相学习」!(vx:python812146)
以上内容技术相关问题😈欢迎一起交流学习👇🏻👇🏻👇🏻🔥
本文作者:Dancing-Pierre
本文链接:https://www.cnblogs.com/wyc-1009/p/17547991.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步