

Learning Continuous Image Representation with Local Implicit Image Function【阅读笔记】
CVPR21
将图像超分辨率问题转化为寻找图像的连续表示。本质上图像会存在分辨率的问题,是由于其存储和表示使用的是二维数组。如果将图像的表示是一个连续函数,那么图像就可以是任意分辨率的。这个思路受启发于三维重建中的implicit neural representation
implicit neural representation
所谓implicit neural representation是将物体表示为一个函数,该函数可以将坐标映射到图像信号。这个函数由神经网络学习得到。为了让不同的物体之间可以共享知识,一般用encoder-based方法,将物体的latent code作为输入之一。
目前使用encoder-based方法的implicit function无法表示高保真图像,这可能是由于只用一个简单的latent code完全encode图像的所有细节比较困难。
因此本文提出用一组encode来表示一个图像,即Local Implicit Image Function(LIIF)
具体来说就是,对于给定的坐标,根据坐标信息查询该坐标附近的局部latent codes作为函数输入,预测其RGB值
Local Implicit Image Function
每个图像$I^{(i)}$可以由一个二维特征图$M^{(i)}\in R^{H\times W\times D}$表示。 那么坐标$x_q$处的RGB值可以定义为:$I^{(i)}(x_q)=f(z^*,x_q-v^*)$,其中$z^*$是$M^{(i)}$中距离$x_q$最近的latent code,$v^*$是$z^*$对应的坐标。为了进一步丰富$M^{(i)}$中encode的信息,对其进行feature unfolding。即$\widehat{M}_{jk}^{(i)}=Concat({M_{j+l,k+m}^{(i)}}_{l,m\in{-1,0,1}})$
但上述表示存在一个最大的问题是预测是非连续的,当$x_q$变换时$z^*$会突然跳变。这导致坐标上无限接近的点可能输出的latent code非常不同。针对这个问题作者采用的解决方法是**local ensemble**
上式变为:$I^{(i)}(x_q)=\sum_{t\in{00,01,10,11}}\frac{S_t}{S}\cdot f(z_t^*, x_q-v_t^*)$,其中$S_t$是$x_q$和$v_t^*$之间长方形的面积。也就是说实际上的RGB值是附近四个邻域的加权均值

那么现在我们就可以在任意分辨率下使用LIIF对图像进行表示。对于给定的分辨率,最直接的方式就是根据像素点中心坐标求得对应的RGB值。但这样的方式是独立于size的,也就是说像素点包围的位置中的其他信息都丢失了。
因此作者采用了一种cell decoding的策略。s=f_{cell}(z, [x, c]),其中$c=[c_h, c_w]$, $[x,c]$表示concat
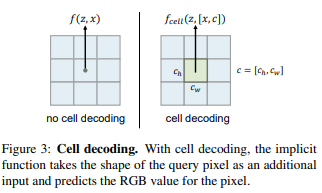
Learning Continuous Image Representation
因此整个训练任务的目标是通过给定一组训练集图像,学习到一个可适用于unseen image的连续表示。为此我们需要学习一个encoder$E_\phi$用于将基于像素的图像映射为二维特征图,还需要学习一个neural implicit function$f_\theta$。这里,考虑到希望学到的LIIF不仅可以重建其输入,还可以在高分辨率时保持高保真,因此采用的是自监督的方式学习。
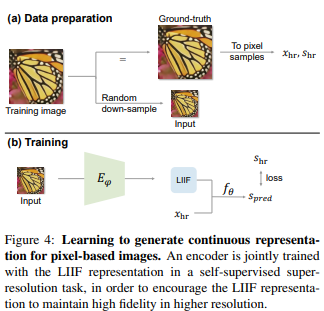
对于给定的一张训练图片,以随机的scale下采样作为input。对应的ground-truth表示为$x_{hr},s_{hr}$,$x_{hr}$是中心坐标,$s_{hr}$是对应的RGB值。$E_\phi$将input映射为二维特征图作为LIIF表示,使用$x_{hr}$进行query,$f_\theta$会预测对应RGB值$S_{pred}$,与$S_{hr}$计算loss。在本文的实验中$E_\phi$是EDSR或RDN去掉upsampler部分,选用的loss是L1 loss
实验
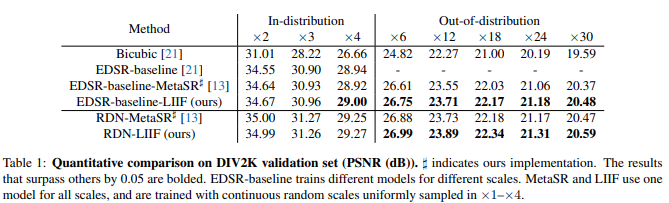
为了验证本文的方法可以对连续表示有效,除了验证训练的scale以外,还需要验证非常大的、不在训练分布中的上采样scale。因此训练时在1倍到4倍之间均匀采样,而在测试时对6倍到30倍都进行了验证。由于针对如此大倍数的SR方法很少,这里实际上的SOTA就只有MetaSR。

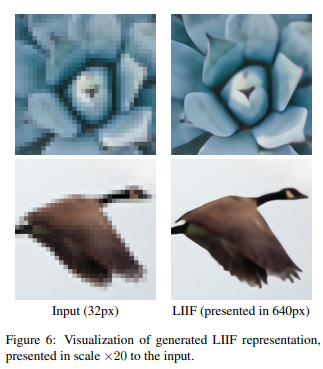
从视觉效果上来看也还是很不错的,其中1-SIREN是指直接针对一张测试图片拟合一个SIREN neural implicit function

发现cell decoding似乎会影响out-of-distribution high resolution时的PSNR值。因此进行了如下的实验:

可以看到针对30倍的任务,cell-1/30明显好于其他设定。如果decoding cell大于实际的像素大小,这就类似于用一个比较大的平均核对图像进行处理。结论是,使用cell decoding有助于in-distribution scales,当scale过大时可能会影响PSNR但是仍然可以提升视觉质量。
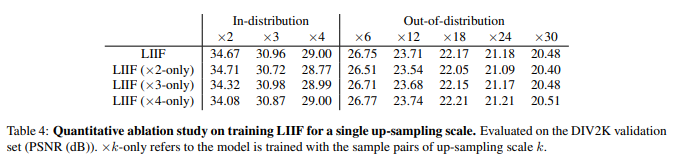
实验在训练时使用固定的scale,虽然可以提升该scale的结果,但是对于其他scale效果不好。
还针对size-varied ground-truth问题进行了实验。

