个人感觉这篇论文写的有点莫名其妙,很多地方都没有讲清楚,符号下标也都没有讲清楚。代码也是,全都是按block1,2,3这样来的,可读性奇差。但顶不住表现好啊。
Motivation:
如何重复利用网络的特征图,使得网络的深度不需要特别深也可以得到比较好的效果.一种方式是使用recursive结构,但这种方式计算量大.本文采用另一种方式——稠密连接。
目前的工作只关注了某个scale的特征限制了网络表达能力
本文提出的DRLN利用残差块之间的稠密连接,用拉普拉斯金字塔注意力对不同scale的特征赋予权重。
网络结构
![]()
网络分为四个部分:特征提取,cascading over residual on the residual,upsample,重建。重点在于CRIR部分,剩余部分和其他SR网络是一致的。
CRIR
CRIR是一个分层结构,包含多个cascading blocks。每个cascading block包含一个medium skip-connnection(MSC)和级联的特征拼接,由许多个dense residual laplacian module(DRLM)组成。每个DRLM包含一个densely connected residual 单元,压缩单元和拉普拉斯金字塔注意力单元。
没太明白原文里说的MSC什么意思,给的公式符号都没讲清楚,怀疑就是图上标注的SSC部分。图上的SSC部分又没有在原文中提到。实际上这个网络结构和RCAN是一样的,多的地方在于group内部对前面特征的拼接。
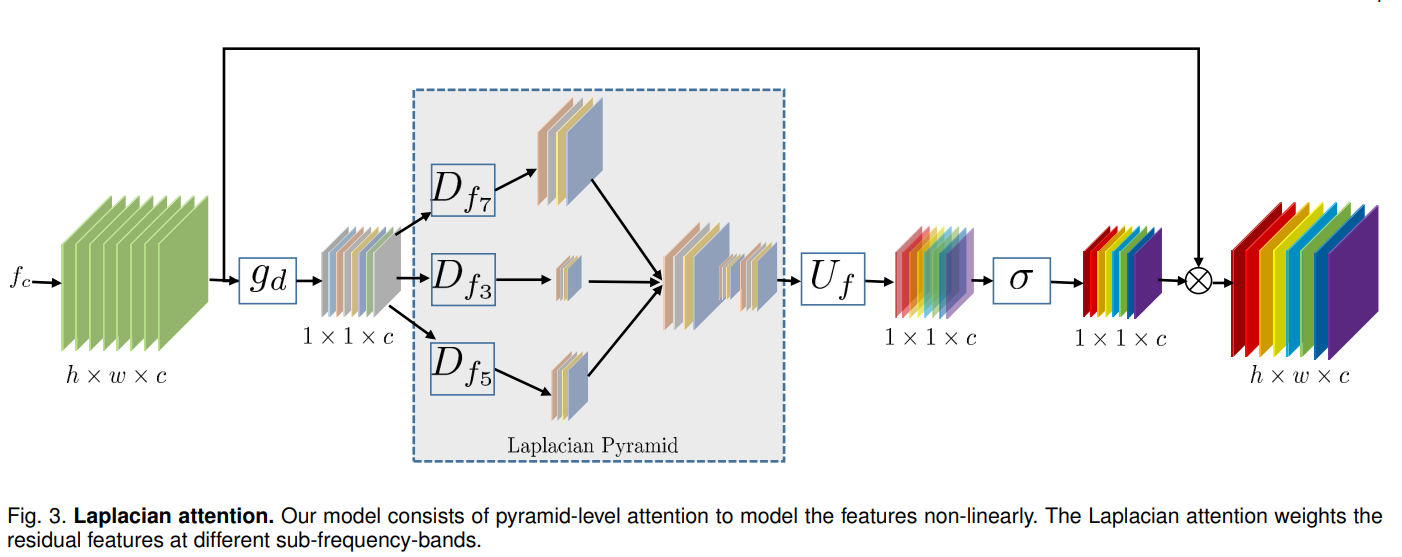
Laplacian Attention
![]()
这部分和RCAN也基本一样,区别在于中间用了三个不同的空洞卷积,再对他们的特征进行拼接之后进行后续操作。
这里的$D_{f_7}$指一个padding=7,dilation=7的卷积。3个操作最终得到的特征图的尺寸和原图是一样的,但是感受野不同。
实验
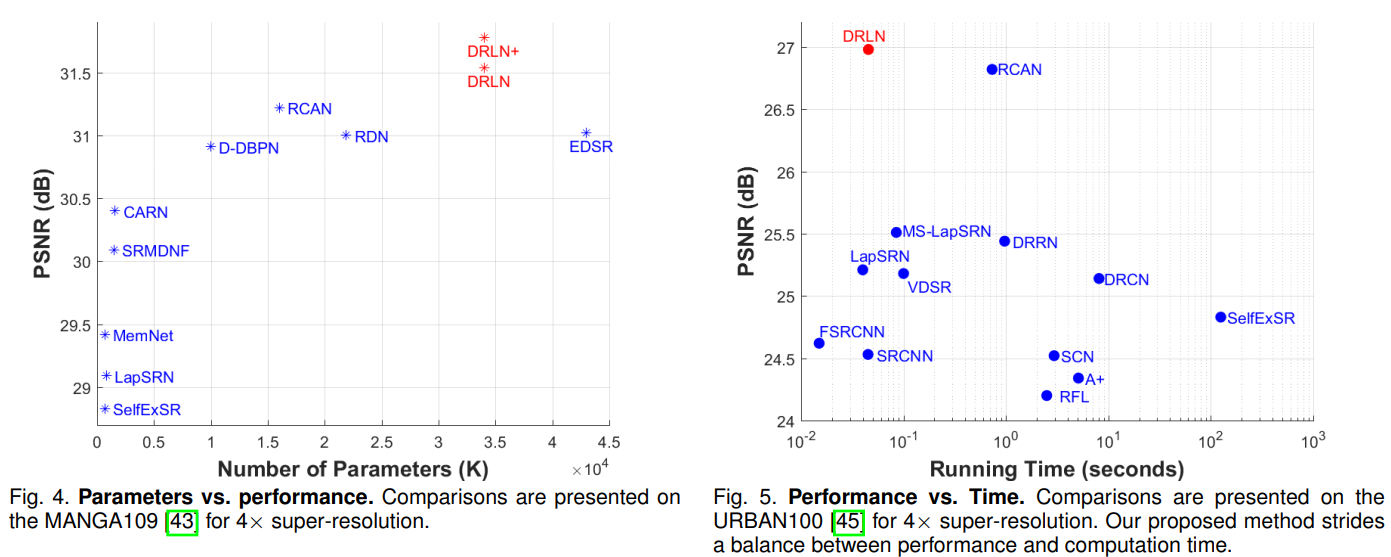
进行的实验有:Ablation Study;参数量,运行时间,PSNR和视觉效果与SOTA的比较。在blur degradation,noisy degradation的情况下和SOTA的比较;在真实情况下(指JPEG compression)和SOTA比较。
Bicubic degradation情况下,DRLN在所有数据集所有倍数下都超过SOTA。
![]()
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号