

Blind Super-Resolution With Iterative Kernel Correction【IKC】【阅读笔记】
在现实情况下,SR模型通常会由于实际得blur kernel与预先假设的不一致而造成严重的performance drop。blind SR问题就是要尝试解决blur kernel未知情况下的SR问题。本文就针对blind SR提出,预测每张照片blur kernel的方法,再将blur kernel的信息结合到SR网络中。
文中提出的预测blur kernel的方法称为Iterative kernel correction(IKC)。这个方法基于一个发现:由于kernel不匹配而造成的artifacts存在一定的pattern,因此作者提出用一个网络对kernel进行预测。但是这个问题是一个不适定性问题,对kernel $k$的准确预测是不可能的。因此加入了一个corrector对kernel进行纠正,作者发现如果只进行一次纠正,效果并不好。因此提出了迭代式纠正的方法。

算法的具体流程如下。

predicator首先预测一个初始的kernel $h_0$,训练时的优化函数为$||k_P(I^{LR};\theta_P||^2_2$,其结构如下
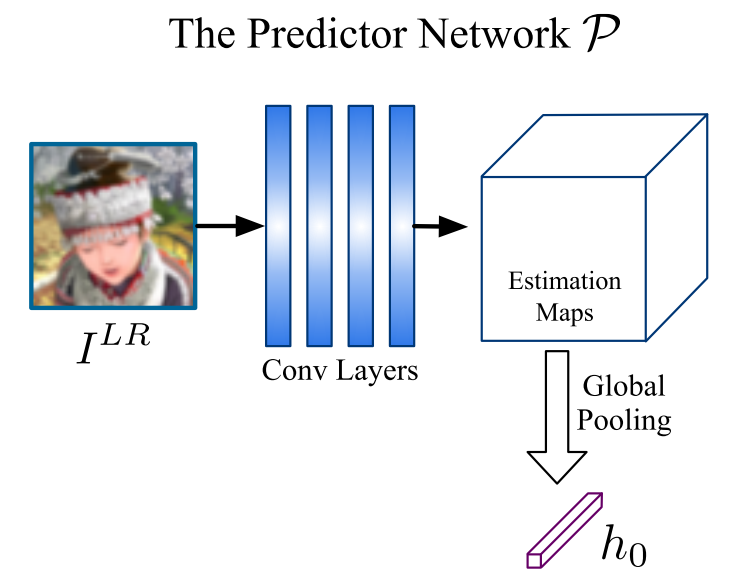
当kernel预测完成后,需要将kernel信息整合入SR模型中。在此之前针对不同的kernel进行SR的方法为SRMD,他是将LR图像和kernel maps拼接成一个$(b+C)\times H\times W$的输入。作者指出这样做并不是最好的方法,由于kernel maps不存在图像信息,同时对kernel maps和图像进行卷积会引入与图片不相关的interference。并且kernel信息只影响了第一层,网络的深层很难受到影响。因此作者提出了应用spatial feature transform(SFT)层的方法,构建SFTMD。
取SRResNet作为主干网络,在residual模块的所有conv层和global residual connection之后都加入SFT层。SRT层对每一个中间层的特征图都进行仿射变换(进行缩放和平移)。这个变换可以定义为$SFT(F, H)=\gamma\odot F+\beta$,其中两个变换参数$\gamma,\beta$是由CNN得到的。这个CNN取特征图$(C_f\times H\times W)$与kernel maps(b\times H \times W)进行拼接作为输入。
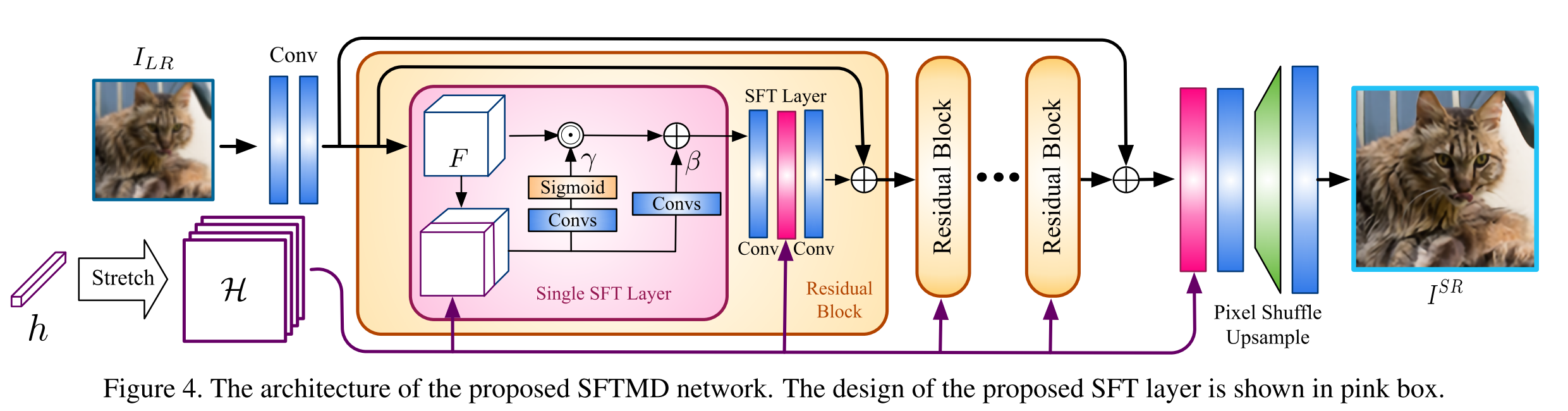
由这个网络$F$得到的SR结果$I^{SR}$会和该轮的kernel maps一起输入到corrector中,用于修正并产生新一轮的kernel($h_i=h_{i-1}+\Delta h_i$)。corrector的优化目标为$||k-(C(I^{SR};\theta_C)+k')||^2_2$,网络结构如下。

blur kernel首先都使用PCA方法进行降维以减小computation。并且由于PCA为kernel提供了一个特征表示,使得模型学习到的是SR图像与这些特征而不是kernel width之间的关系,从而使IKC不易受到kernel width的影响。在真实图像数据集中IKC表现很好,并且将IKC与 SRMD+手工选择的kernel进行比较,IKC虽然对比度相对较低,但也同样有清晰的边界和更自然的效果。

作者还指出,虽然本文中是针对各向同性的模糊核进行讨论,而实际情况还存在一定的motion blur。但是轻微的motion blur情况下,IKC的基础即这种kernel mismatch的现象仍然存在。因此通过employing such asymmetry of the kernel mismatch in each direction,IKC可以应用于更实际的场景。
个人感觉本文中提出的方法最后测试时需要运行多次,时间可能会比较慢?【待实验】和之前读到的MZSR相比,MZSR的表现要比这个有提升。本质上IKC是不是一个去模糊与超分的结合?

