Enhanced Deep Residual Networks for Single Image Super-Resolution【EDSR】【阅读笔记】
在这篇文章之前,陆续有了一些使用深度学习网络进行SR任务的工作,但是这些以提升PSNR为目标的深度神经网络存在几点问题:
- 网络表现对于网络结构很敏感,不同的初始化和训练方法对表现得影响也很大。这就使得模型的设计和优化策略的选择变得非常重要。
- 目前的SR算法都把不同放大因子的问题看作是独立的问题,没有利用他们之间的互相关系。
这篇文章主要针对这两点问题,首先改进了SRResNet网络结构,通过分析去除了不必要的模块简化了模型,提出了更稳定的训练方法。之后探索如何将其他尺度下训练的模型的只是转移,通过使用预训练的低尺度模型训练高尺度模型,从而在训练中利用了scale-interdependent信息。在训练$\times3, \times 4$模型时,将预训练的$\times2$作为初始化。并且提出了一个多尺度的超分模型,可以在一个模型中重建不同尺度的高分辨率图像。这篇文章的工作不是非常复杂,但是非常有效果,而且个人感觉paper的写作非常简洁清晰,在写作方面也值得借鉴。
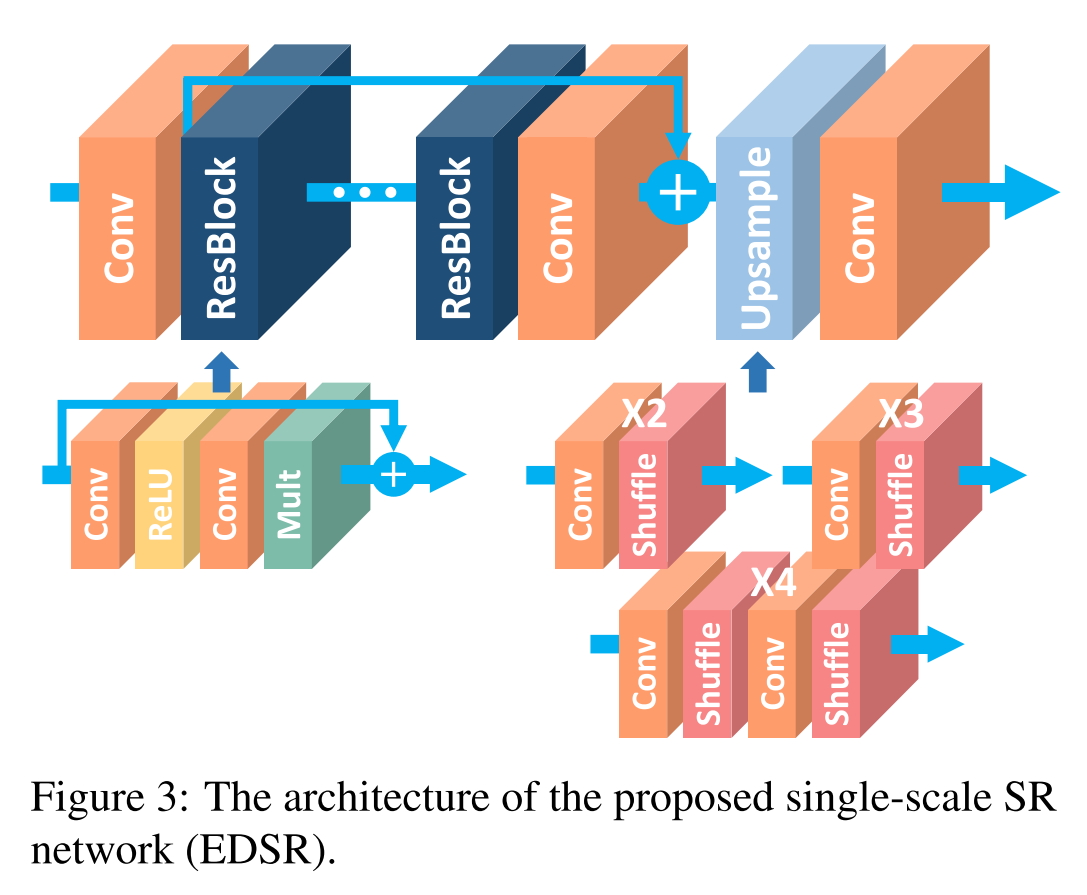
SRResNet是在ResNet提出后提出的,仅仅将ResNet直接应用于SR任务。但由于ResNet提出的初衷是应用于high-level-vision问题,直接应用实际上是suboptimal的。在每一个Residual Block中,都有一个Batch Normalization层,他归一化了特征但也因此去除了网络中的灵活性。本文去除每个Residual Block中的BN层,提升了表现。而且减少了大约40%的内存,这些节省的内存可以用于构建更大的模型。
模型的表现可以通过增加参数量来实现,假设一个网络的深度为$B$,宽度为$F$,那么参数量是$O(BF^2)$,内存量是$O(BF)$。(这只是一个大概的估计,他这里的宽度是把输入和输出的宽度视为一样的来看。一般模型会用参数量或是FLOPS进行衡量,一般一层的FLOPS用$H_out*W_out*(d*d*C*N)$来估计,$d*d*C*N$表示kernel的尺寸和个数)因此在资源有限的情况下应该尽可能增大F。但特征图数量增大到一定程度时会导致训练过程非常不稳定。文中提出使用Residual Scaling的方法解决该问题,即在每一个residual block中,最后一个卷积层后加一层constant scaling layer,乘以一个常数(文中使用的时0.1)
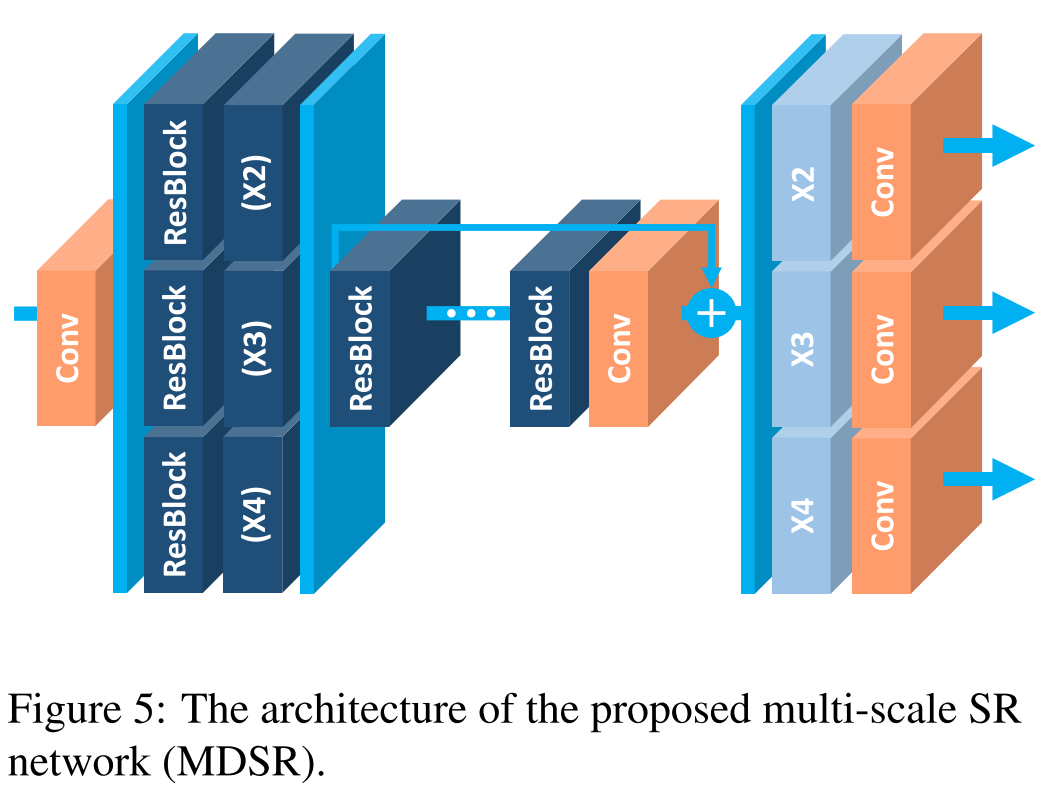
文中提出的多尺度模型如下,预处理模块是两层的residual block,作用是reduce不同尺度的输入中的variance。主干部分是相同的,使用相同的参数。网络的最后是scale-specific的上采样模块,平行的分布,处理多尺度的重建工作。该多尺度模型的参数量相比单独处理的模型参数总和要小很多。
文章在DIV2K, Set5, Set10, B100, Urban100数据集上进行了实验。使用的是L1loss。通常L2loss可以使PSNR表现更好,但作者发现L1loss可以提供更好的收敛性。相比SRCNN,EDSR差不多能提升1个点的表现,在Set5甚至差不多能有2个点。相比SRResNet差不多可以提升约0.5个点。
去掉BN层的原因:
文中没有详细讲述为什么SR中要去掉BN层。查了一些资料,有这样一个比较初步的观点。
首先BN的作用是为了解决Interval Covariance Shift问题,他是由网络输入和输出分布发生变化造成的。
机器学习中的一个经典假设是:“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有$x\in \mathcal{X}, P_s(Y|X=x)=P_t(Y|X=x)$,但是$P_x(X)\neqP_t(X)$.对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
机器学习还有一个假设是“输入是独立同分布的”,他的意思是说所有的训练数据都是在同一个空间下随机采样得到的。但由于神经网络中各种非线性的操作,导致了空间产生了变化。第i层本来学到的可能是在空间A下的特征,但是网络一更新,第i层的输入空间改变了,第i层又需要重新调整自己。这就导致了神经网络训练变慢。BN层对输入做了一个归一化的操作,他先把输入都拉到了01分布,然后通过调整参数$\gamma,\beta$让这一层的分布又能具有他自己本身的特征。
在分类问题中,输入是一个图片,输出是类别,神经网络每一层学到的是图像的结构信息。源空间到目标空间的数据分布差别非常大。而在SR问题中,输入是一个图片,输出也是一个图片,并且是包含很多输入信息的图片,神经网络学到的是图像中的高频细节。输入和输出的数据分布差别没有那么的大,所以层与层之间也不会有那么严重的偏移现象,对于独立同分布的输入,在经过神经网络后也还可以比较接近的认为是独立同分布的。因此BN的作用并没有那么明显了,如果将BN中的参数省去用于扩大网络深度和宽度,表现的提升要更明显。而同时,BN是对一个batch进行归一化处理,他实际上是对图片的色彩进行了一定的拉伸。在SR任务中,我们需要关注的是图像自身的信息,BN引入了同一个batch中其他无关图片的统计量反而弱化了他自身的特征。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号