barabasilab-networkScience学习笔记3-随机网络模型
第一次接触复杂性科学是在一本叫think complexity的书上,Allen博士很好的讲述了数据结构与复杂性科学,barabasi是一个知名的复杂性网络科学家,barabasilab则是他所主导的一个实验室,这里的笔记则是关于里面介绍的课程的笔记,当然别人的课程不是公开课,所以从ppt里只能看到骨干的东西了,对了补充下,slider相关的书籍在这里可以找到
说实话这一节的slider我没有看很明白公式,数学功底差了,如果你能够有更好的解释欢迎留言
Random Networks(Erdös-Rényi model (1960))是由Pál Erdös和Alfréd Rényi提出的,这个东西是什么的呢?看下面的维基介绍:
自二十世纪60年代开始,对复杂网络的研究主要集中在随机网络上。随机网络,又称随机图,是指通过随机过程制造出的复杂网络。最典型的随机网络是保罗·埃尔德什和阿尔弗雷德·雷尼提出的ER模型。ER模型是基于一种“自然”的构造方法:假设有
个节点,并假设每对节点之间相连的可能性都是常数
。这样构造出的网络就是ER模型网络。科学家们最初使用这种模型来解释现实生活中的网络[1]:7-9。
 个节点,并假设每对节点之间相连的可能性都是常数
个节点,并假设每对节点之间相连的可能性都是常数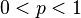 。这样构造出的网络就是ER模型网络。科学家们最初使用这种模型来解释现实生活中的网络
。这样构造出的网络就是ER模型网络。科学家们最初使用这种模型来解释现实生活中的网络我想你大概知道这个网络模型了吧,节点之间的链接完全随机的,slider在最后说这种模型在现实中是完全不存在的,我们了解这个模型只是拿来作对比,看看在没有外界因素作用下(随机的情况下)这种模型有什么特点,这样我们就可以更好地研究其它模型了。
既然说到模型特点,那么就需要先了解清楚这个随进网络的一些特征了,这样才能在以后的学习更好的网络模型的时候进行很好的比较
上一节课说到网络模型的三个重要特征:
- Degree distribution: P(k)
- Path length: <d>
- Clustering coefficient: C
还记得么?那么这节课就是讲随机网络模型的这三个特征来一一的分析
仔细看来,这里面的数学推导都是应用随机过程的方法,网络科学(或者很多科学)建立在随机过程之上(数学),这也可见学习它们的重要性
首先说说度的分布,它是二项分布的,把这个东西和现实中的网络比较起来(一些人搜集的互联网数据构建的网络,蛋白质结构绘制的网络,或者Facebook网络)相差甚远,现实中往往分布式幂函数分布(因为我们大数据时代搜集数据的便利才能验证某些模型是正确的,所有的模型要基于现实,而从现实那里获取的第一步资料往往是数据,大数据时代,更加集中想往数据这个层面走,而机器学习也直接从数据中来抽取智慧(规律),这让我突然想起来了牛顿的运动定律与开普勒的运动定律)
随机网络为了也有一些演化,并试着解释物理学中的一些相变现象(比如水变成冰),临界点的研究通常是典型的非线性系统,也就是所谓的复杂系统,这也是为什么开篇说网络是复杂系统的heart
那点分布不行,path length呢?这个好像跟现实中会有点像,现实中研究这个得出的结论称之为六度理论,或者称之为小世界。
后面还讲到随机网络的Clustering coefficient,这个也是和现实中的网络很不相同的
slider里面有两个重要的slider要分享给大家:
好了,我要滚出实验室了,大叔赶人了,看我不走,他走了



 浙公网安备 33010602011771号
浙公网安备 33010602011771号